Direct Preference Optimization for Large Language Model Alignment
The alignment of large language models (LLMs) to human preferences, complex reasoning protocols, and safety constraints has undergone a rapid and profound architectural evolution. While autoregressive next-token prediction over massive corpora serves as the foundation of pre-training, it is the post-training alignment phase that dictates a model's utility, stylistic adherence, and capacity for advanced problem-solving. Historically, this critical phase was dominated by Reinforcement Learning from Human Feedback (RLHF) utilizing the Proximal Policy Optimization (PPO) algorithm. However, the substantial computational overhead, infrastructure complexity, and algorithmic instabilities inherent to PPO drove the rapid adoption of reward-free paradigms, most notably Direct Preference Optimization (DPO).
As the boundaries of LLM capabilities expand from conversational chat into complex mathematical logic, multi-step agentic planning, and verifiable coding, the limitations of standard DPO - such as length exploitation, severe susceptibility to noisy preference labels, and catastrophic degradation during out-of-distribution generation - have catalyzed a Cambrian explosion of alignment algorithms. This comprehensive research report provides an exhaustive technical examination of the post-training alignment landscape. The analysis explicitly compares the training pipelines of traditional RLHF and DPO, details the mathematical derivation of implicit reward models, and catalogs the extensive family of derivative optimization algorithms, including IPO, KTO, ORPO, and SimPO. Furthermore, the report explores the renaissance of group-relative reinforcement learning techniques, specifically GRPO, DAPO, and GSPO, which are currently driving the state-of-the-art in frontier open-weight models like Llama 3 and Qwen 2.5.
The Foundational Bottleneck: Traditional RLHF and PPO Pipelines
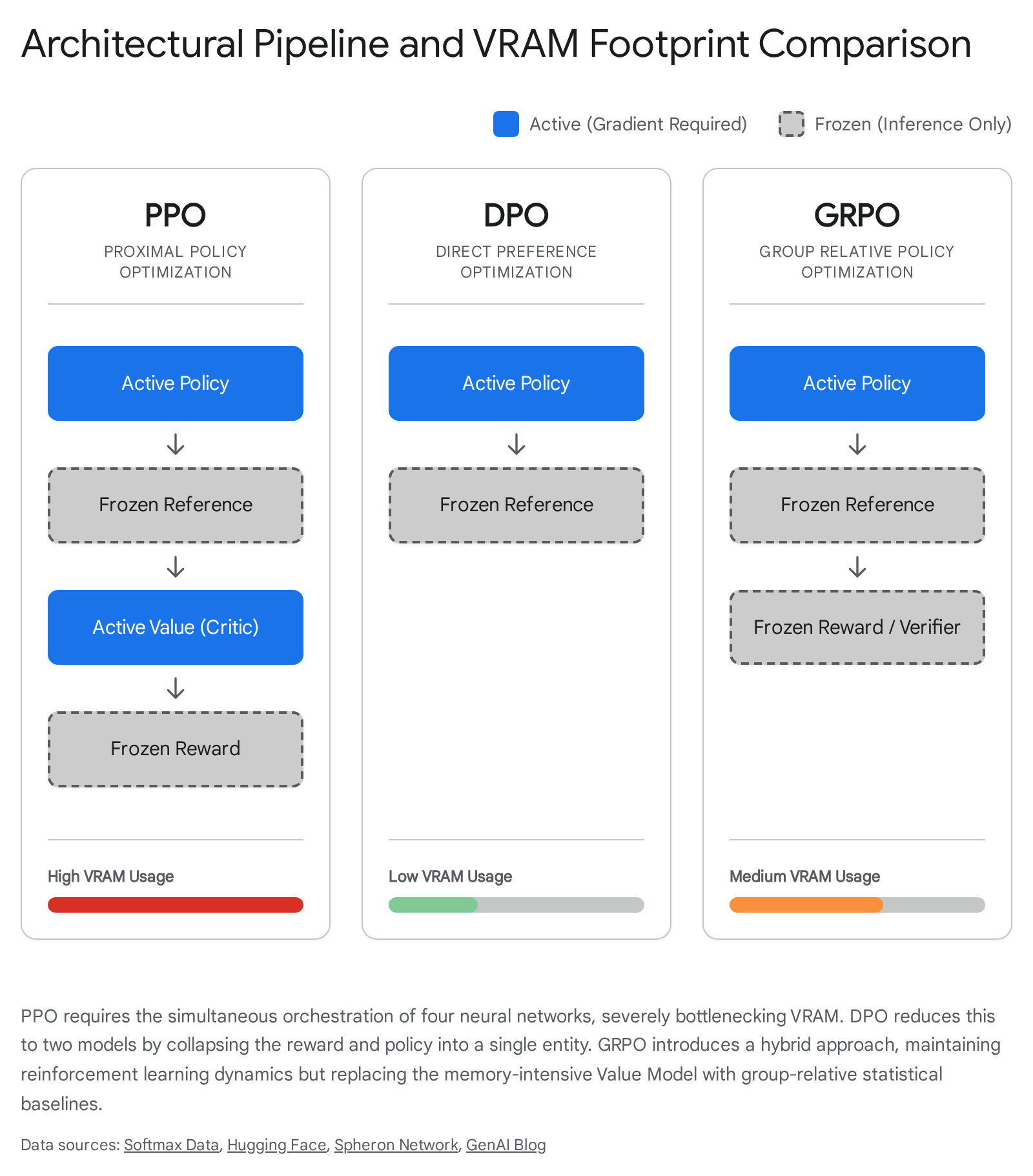
To understand the specific pain points of traditional RLHF, one must first dissect the architectural requirements and mathematical intricacies of the PPO training pipeline. PPO is an online, actor-critic reinforcement learning algorithm that requires the simultaneous orchestration of four distinct neural networks in memory, creating a massive computational bottleneck for large-scale language models.
The PPO architecture consists of the Policy Model (the actor), which is the language model actively being updated; the Reference Model, which is a frozen copy of the pre-trained or supervised fine-tuned (SFT) model; the Reward Model, a separate scalar-output network previously trained on human preference data to evaluate the quality of the policy's generations; and the Value Model (the critic), a network that predicts the expected future reward from a given token state to establish a baseline for advantage calculation 123.
This four-model architecture imposes severe computational and memory constraints. For a standard 7-billion parameter language model, the PPO pipeline requires sufficient Video RAM (VRAM) to hold roughly four copies of the model simultaneously. Beyond the model weights, the system must retain the optimizer states (such as the first and second moments in AdamW) and the gradients for both the active Policy and active Value networks 34. When scaling to 32-billion or 70-billion parameter models, this footprint frequently forces practitioners to rely on extensive multi-node tensor parallelism and pipeline parallelism, drastically increasing communication overhead, slowing down training throughput, and escalating infrastructure costs to levels accessible only to the most well-funded global AI laboratories.
Beyond hardware constraints, PPO suffers from inherent and mathematically complex optimization instabilities. The algorithm relies on Generalized Advantage Estimation (GAE) to compute the advantage of a specific action. In the context of language models, an action is the generation of a single token. The Value Model must learn to assign credit across unbounded, discrete token sequences 23. In tasks requiring multi-step logic, such as a 1,000-token chain-of-thought mathematical proof, calculating the exact token responsible for a correct or incorrect final answer is notoriously difficult. If the Value Model produces inaccurate or high-variance baselines, the gradient updates fed to the Policy Model become erratic.
Furthermore, PPO relies on a clipped surrogate objective and a Kullback-Leibler (KL) divergence penalty to prevent catastrophic policy shifts 12. The algorithm attempts to maximize the reward while ensuring the updated policy does not deviate excessively from the Reference Model, preserving the fundamental language capabilities acquired during pre-training. However, hyperparameter sensitivity in this dynamic is extreme. Empirical studies have demonstrated that PPO over-correction operates in both directions; if the KL penalty coefficient is too weak, the model experiences catastrophic forgetting of its SFT capabilities, whereas if it is too strong, the policy becomes over-constrained and fails to optimize for the target reward 5.
Direct Preference Optimization (DPO): Mechanisms and Mathematics
To circumvent the vast engineering convolutions of PPO, Direct Preference Optimization (DPO) was introduced as a mathematically elegant reparameterization of the standard RLHF objective. DPO eliminates the explicit Reward Model and Value Model entirely, recasting preference alignment as a straightforward classification problem optimized via a binary cross-entropy objective 164. This shift dramatically lowers the barrier to entry for alignment, allowing researchers to fine-tune massive models on consumer-grade hardware.
Mathematical Derivation of the Implicit Reward Model
The theoretical foundation of DPO relies on the profound realization that a language model policy can implicitly define its own reward function, effectively grading its own performance against a frozen reference model. The traditional KL-constrained reward maximization objective utilized in standard RLHF is defined mathematically as:
$$ \max_{\pi_\theta} \mathbb{E}{x \sim \mathcal{D}, y \sim \pi\theta} \left[ r(x,y) - \beta \mathbb{D}{\text{KL}}(\pi\theta(y|x) |
| \pi_{\text{ref}}(y|x)) \right] $$
In this equation, $r(x,y)$ represents the true, latent reward function, $\beta$ is a hyperparameter that controls the strength of the KL divergence penalty, and $\pi_{\text{ref}}$ represents the foundational reference policy. As established in classical reinforcement learning literature, the optimal analytical solution to this specific KL-constrained reward maximization objective takes a closed-form expression 64:
$$\pi_r^*(y|x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y|x) \exp\left(\frac{1}{\beta} r(x,y)\right)$$
Here, $Z(x)$ represents the intractable partition function, a normalization constant that integrates over all possible generations to ensure the resulting probabilities sum strictly to one. DPO's primary mathematical breakthrough is the algebraic manipulation of this optimal policy equation to solve directly for the reward function $r(x,y)$ 16:
$$r(x,y) = \beta \log \frac{\pi_\theta(y|x)}{\pi_{\text{ref}}(y|x)} + \beta \log Z(x)$$
This rearranged equation demonstrates that the reward is implicitly defined by the log-ratio of the active policy model against the reference model, scaled by $\beta$, plus the partition function. To eliminate the intractable nature of the partition function, this implicit reward definition is plugged into the Bradley-Terry (BT) model of human preferences. The BT model calculates the probability that a response $y_w$ (the winning or preferred response) is favored over $y_l$ (the losing or rejected response) 15:
$$P(y_w \succ y_l | x) = \frac{\exp(r(x,y_w))}{\exp(r(x,y_w)) + \exp(r(x,y_l))} = \sigma \left( r(x,y_w) - r(x,y_l) \right)$$
Because the Bradley-Terry model operates entirely on the relative difference between two rewards, subtracting the implicit reward of the losing response from the implicit reward of the winning response causes the intractable partition function $Z(x)$ to perfectly cancel out 15. Substituting the implicit rewards back into the BT probability model yields the final, highly efficient DPO loss function:
$$\mathcal{L}{\text{DPO}}(\pi\theta; \pi_{\text{ref}}) = - \mathbb{E}{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi\theta(y_w | x)}{\pi_{\text{ref}}(y_w | x)} - \beta \log \frac{\pi_\theta(y_l | x)}{\pi_{\text{ref}}(y_l | x)} \right) \right]$$
Conceptually, this mathematically elegant formulation means the training process directly adjusts the neural network weights of the policy to increase the relative log probability of preferred responses while simultaneously decreasing the likelihood of rejected responses. By relying on this indirect reparameterization, DPO achieves the exact same theoretical optimum as complex PPO without ever necessitating online token generation, generalized advantage estimation, or a dedicated, memory-intensive reward model 45.
Addressing the DPO Data Quality Misconception
A pervasive and dangerous misconception within the applied machine learning community is the belief that by bypassing the dedicated reward model, DPO somehow reduces the necessity for meticulous data curation. The empirical reality observed in large-scale deployments is precisely the opposite. Because DPO optimizes directly on a static offline dataset $\mathcal{D}$, the evolving policy is hyper-sensitive to the precise quality of the preference pairs $(y_w, y_l)$ 67.
In a traditional PPO pipeline, a separately trained Reward Model acts as a crucial epistemic buffer. It generalizes from the raw human preference data, smoothing over individual annotator contradictions, label noise, and minor formatting errors to create a continuous, generalized reward landscape 1112. DPO completely lacks this smoothing buffer. If the preference pairs in the dataset contain noisy labels, contradictory human preferences, or poorly formatted but "preferred" outputs, the DPO loss function will blindly and aggressively push the model weights to memorize these exact discrepancies 58. Therefore, DPO strictly requires high-margin, high-quality preference pair datasets. Without rigorous data filtering, the direct, unbuffered gradient updates rapidly lead to model degradation, mode collapse, and a loss of general reasoning capabilities 118.
Pathologies of DPO and Advanced Mitigation Strategies
While DPO dramatically lowers the barrier to entry for open-source model alignment, rigorous empirical testing across diverse testbeds has exposed several fundamental algorithmic limitations. These pathologies manifest severely when scaling offline optimization to complex, high-stakes production environments.
Sensitivity to Noisy Labels and Reward Margin Explosion
DPO exhibits a mathematical propensity to overfit rapidly on preference datasets. The algorithm iteratively attempts to drive the log-ratio difference between the chosen and rejected responses toward infinity 568. In scenarios where human preference labels are nearly deterministic, or conversely, when the dataset is plagued with high variance and noise, the model over-corrects. Analysis of DPO training dynamics reveals that the reward margin can explode from a baseline of 1 to nearly 600 within a mere 150 training steps, causing the loss to collapse to zero 5. This indicates the model is memorizing the specific pairs rather than learning a generalized human preference function, causing a severe degradation in the natural language understanding capabilities established during the prior SFT phase.
To mitigate this overfitting, researchers developed Identity Preference Optimization (IPO). IPO acknowledges that DPO's logistic loss drives preferred sample log-ratios to infinity and replaces it with a squared loss mechanism. This bounds the total loss and applies a critical regularization term that constrains deviations from the reference model, enabling practitioners to train models to convergence without relying on arbitrary early stopping tricks 7814.
Alternatively, Conservative DPO (cDPO) integrates the concept of label smoothing into preference learning. By assuming a certain percentage of the preference labels in the training dataset are inevitably flipped or noisy, cDPO blends the standard DPO objective with an inverted objective. This effectively dampens the gradients and prevents the policy from treating every preference label as absolute ground truth 8159. Pushing this paradigm further, Robust DPO (rDPO) constructs an unbiased estimate of the binary cross-entropy loss specifically tuned to the statistical noise level of the preferences, allowing the importance weights in the gradients to automatically adjust to the detected noise level, debiasing the optimization process 159.
Out-of-Distribution (OOD) Generation Shifts
Because DPO is an offline algorithm, it is bounded entirely by the coverage of the dataset and cannot explore new generative trajectories during training. Furthermore, DPO fundamentally assumes that the reference model $\pi_{\text{ref}}$ is capable of assigning a meaningful probability mass to both the winning and losing responses present in the dataset. If the preference pairs $(y_w, y_l)$ are sourced from an external, vastly superior model - such as a proprietary frontier model like GPT-4 - and these responses are deeply out-of-distribution for the current base policy, the log-probability ratios become extreme. The loss landscape becomes dominated by a handful of OOD examples, leading to severe training instability 817.
The primary mitigation strategy for OOD degradation involves strict on-policy data collection. Researchers have demonstrated that executing a Rejection Sampling Optimization (RSO) pass significantly improves DPO outcomes. In RSO, the base model itself generates a wide array of responses to a given prompt. These on-policy generations are then scored and paired by an external judge to create the DPO dataset, thereby guaranteeing that the reference model maintains an accurate and stable log-probability distribution over the training data 68.
Verbosity and Length Bias Exploitation
A highly documented pathology of standard DPO is its tendency to exploit sequence length. Because the DPO implicit reward is calculated over the sum of log probabilities across a token sequence, longer responses naturally accumulate higher total variances. When human annotators exhibit even a slight psychological bias toward longer, more detailed responses - a pervasive phenomenon in crowdsourced data - DPO violently exploits this correlation. The policy rapidly learns that generating unnecessarily verbose, dense, and structurally repetitive answers is the most efficient method to maximize the implicit reward margin, sacrificing conciseness and precision in the process 4818.
The Proliferation of Offline Variants: A Comprehensive Taxonomy
To resolve the structural limitations of DPO, the machine learning community engineered a distinct taxonomy of reward-free, offline alignment algorithms. Table 1 enumerates these core methodologies, illustrating their architectural divergence, mathematical underpinnings, and the primary alignment bottleneck they aim to resolve.
Table 1: Comprehensive Taxonomy of Preference Alignment Algorithms
| Algorithm | Method Paradigm | Underlying Loss Function / Mechanism | Memory Requirements | Primary Problem Solved |
|---|---|---|---|---|
| PPO 123 | Online RL, Actor-Critic | Clipped surrogate objective with generalized advantage estimation (GAE) and KL divergence penalty. | Very High: Policy, Value (Critic), Reference, and Reward models reside simultaneously in VRAM. | Baseline RLHF; maximizes scalar rewards while remaining near the reference policy via online exploration. |
| DPO 64 | Offline, BT Model | Binary Cross-Entropy on the implicit reward (log-ratio of Policy to Reference). | Low: Policy and Reference models only. | Eliminates the Reward and Value models; mathematically simplifies RLHF to a classification task. |
| IPO 678 | Offline, Regularized | Squared loss on the log-ratio difference minus a target margin ($1/2\tau$). | Low: Policy and Reference models only. | Prevents DPO from driving log-ratios to infinity; mitigates overfitting on noisy or highly deterministic labels. |
| KTO 81920 | Offline, Unpaired, Prospect Theory | Kahneman-Tversky value function; compares single generation likelihood against a reference baseline expected reward ($z_0$). | Low: Policy and Reference models only. | Eliminates the need for expensive paired $(y_w, y_l)$ data; operates efficiently on simple binary labels (Desirable/Undesirable). |
| ORPO 212210 | Offline, Monolithic | $\mathcal{L}{\text{SFT}} + \lambda \mathcal{L}{\text{OR}}$; Combines negative log-likelihood loss with a log-odds ratio penalty for rejected responses. | Very Low: Only the Policy model; completely reference-free. | Combines SFT and preference tuning into a single compute-efficient step; eliminates the frozen reference model overhead. |
| SimPO 82425 | Offline, Length-Normalized | Modified Bradley-Terry objective utilizing length-normalized average log probabilities and a target reward margin $\gamma$. | Very Low: Only the Policy model; completely reference-free. | Eradicates DPO length bias; aligns training metric natively with inference generation metrics; highly memory efficient. |
| GRPO 32627 | Online RL, Critic-Free | Clipped surrogate objective utilizing standard normalization over an online sampled group of $G$ responses. | Medium: Policy and Reference models; requires memory overhead for $G$ online rollouts. | Eliminates the complex Value Model from PPO; drastically reduces memory while maintaining crucial online RL exploration dynamics. |
Deep Dive: Kahneman-Tversky Optimization (KTO)
While the majority of DPO variants attempt to optimize the paired Bradley-Terry model, Kahneman-Tversky Optimization (KTO) represents a paradigm shift by abandoning paired preference data entirely. Acquiring strictly paired preference data $(y_w \succ y_l)$ is labor-intensive, expensive, and limits the utilization of vast amounts of absolute, unpaired feedback - such as simple thumbs-up or thumbs-down interactions on a production user interface 81928.
KTO models LLM alignment through the psychological lens of human prospect theory, a behavioral economics framework which posits that humans perceive value relative to a reference point and exhibit profound loss aversion 1920. KTO requires only a binary signal indicating whether a standalone output is desirable or undesirable. The algorithm calculates the perceived utility of a generation by comparing it to a theoretical reference point ($z_0$), applying different scaling hyperparameters ($\lambda_D$ for desirable outputs, $\lambda_U$ for undesirable outputs) to carefully modulate the model's simulated risk and loss aversion 1112. If a desirable response is assigned a high reward but the generation heavily diverges from the baseline reference model (thereby increasing the KL penalty), KTO suppresses the gradient update. This sophisticated dynamic forces the model to learn the precise, semantic features that make an output desirable, rather than bluntly maximizing output probabilities to hack the reward function 2811.
Deep Dive: Odds Ratio Preference Optimization (ORPO)
Odds Ratio Preference Optimization (ORPO) fundamentally rearchitects the alignment phase by collapsing the traditionally separate SFT and preference tuning phases into a single, monolithic training step 2122. Traditional DPO necessitates a distinct SFT phase to achieve baseline competency, followed by a second phase where a frozen copy of that exact SFT model must be loaded into memory as a reference anchor. ORPO completely discards the reference model requirement 2231.
Instead of relying on a reference baseline, ORPO utilizes the standard negative log-likelihood (NLL) SFT loss to maintain general language generation capabilities, while simultaneously appending an Odds Ratio penalty directly to the objective function. The odds ratio mathematically quantifies how much more likely the model is to generate the preferred token sequence versus the rejected token sequence 212231. By applying a weak penalty to the log probabilities of rejected tokens and a strong adaptation signal to the chosen tokens, ORPO effectively contrasts favored and disfavored styles at the granular token level. This monolithic approach eliminates the KL divergence anchor entirely, resulting in significantly fewer FLOPs and drastically reduced VRAM requirements, making state-of-the-art alignment accessible on resource-constrained hardware configurations 182210.
Deep Dive: Simple Preference Optimization (SimPO)
To directly combat the verbosity and length exploitation pathologies inherent in standard DPO, researchers introduced Simple Preference Optimization (SimPO). SimPO shares ORPO's reference-free architecture but takes a vastly different approach to reward formulation. The authors of SimPO identified a fundamental discrepancy in DPO: the implicit reward function is not aligned with the actual metric used to evaluate sequence generation during inference 182413.
SimPO replaces the sum of log probabilities used in DPO with an average log probability, effectively normalizing the implicit reward by the total sequence length. The SimPO reward function for a response $y$ to input $x$ is defined as $r_{\text{SimPO}}(x, y) = \frac{\beta}{|y|} \log \pi_{\theta}(y|x)$ 24. Furthermore, SimPO introduces a target reward margin ($\gamma$) into the Bradley-Terry objective, ensuring the reward for the winning response is separated from the losing response by a specific threshold to improve generalization 182513. By aligning the training metric directly with length-normalized inference metrics, SimPO completely strips the model of its ability to mathematically exploit verbosity, forcing the optimizer to focus purely on the semantic density and quality of the output 1833.
The Renaissance of Online RL: Verifiable Rewards and GRPO
Despite the elegance, simplicity, and memory efficiency of offline methods like DPO, ORPO, and SimPO, they possess a critical, insurmountable limitation: offline methods fundamentally lack the ability to explore novel trajectories. Because they optimize strictly over a static dataset, they cannot teach a language model to construct complex, multi-step mathematical proofs or write sophisticated, functional code if those exact deductive paths are absent from the training corpus 3. This severe limitation catalyzed a massive industry pivot back to online reinforcement learning, specifically tailored for verifiable tasks. The breakthrough that made this compute-feasible arrived with Group Relative Policy Optimization (GRPO), initially pioneered during the development of DeepSeekMath and subsequently driving the reasoning capabilities of models like DeepSeek-R1 and Qwen 2.5 263435.
The Mechanism of GRPO
GRPO elegantly solves the most egregious memory bottleneck of standard PPO: the Value Model (the Critic). In a standard PPO pipeline, the Value Model is a separate, massive neural network trained simultaneously with the policy to estimate the expected future return of a specific state. GRPO discards this network entirely, cutting VRAM requirements nearly in half and eliminating the complex, secondary optimization loop that frequently causes PPO to diverge 2327.
Instead of a learned critic, GRPO relies on group-relative statistics. Given an input prompt, the active policy generates a group of $G$ multiple distinct responses (rollouts). A reward model - or, crucially for reasoning and mathematical domains, a rule-based deterministic verifier - assigns a scalar score to each individual response 2635. GRPO then calculates the advantage $A_{i}$ of each response $o_i$ simply by standardizing the rewards within that specific generated group 261437:
$$A_i = \frac{r_i - \frac{1}{G}\sum_{j=1}^G r_j}{\text{std}(r_1, \dots, r_G)}$$
This group-relative baseline replaces the learned value function perfectly. If a response performs better than the average of its peers generated from the exact same prompt, its advantage is mathematically positive, and its generating policy ratio is reinforced 3537. Furthermore, GRPO drops the reward-based KL penalty used in PPO, instead adding the KL divergence between the policy and the reference model directly into the total loss objective as a regularizer, greatly simplifying the advantage computation and increasing training stability 143738.
Pathologies in GRPO and Advanced Solutions: DAPO and GSPO
As AI laboratories scaled GRPO to train massive Mixture-of-Experts (MoE) architectures on ultra-long chain-of-thought reasoning traces, new, severe instabilities materialized, requiring further algorithmic innovation.
Length Bias and Token-Level Dilution (DAPO): Because vanilla GRPO calculates the loss at the sample level and divides the total sequence reward equally among all tokens in that response (normalization by $1/|o_i|$), it inherently and unfairly penalizes longer cognitive traces 41540. Shorter, potentially incomplete or heuristically "hacked" answers receive massive gradient updates per token, while comprehensive, multi-step derivations see their gradients severely diluted 1540.
Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) resolves this critical flaw. DAPO shifts from sample-level aggregation to a token-level policy gradient loss where all tokens across the entire batch share equal weight, regardless of the response length they belong to 44041. Furthermore, DAPO implements asymmetric, decoupled clipping bounds. While standard GRPO uses a single clip range (e.g., $\epsilon = 0.2$), DAPO utilizes different values for lower and upper bounds. It allows the model more freedom to deviate from the reference policy when moving away from a poorly rewarded output, but enforces strict clipping constraints to prevent instability when optimizing highly rewarded outputs 441. DAPO also introduces overlong reward shaping, applying a penalty that increases linearly if a sequence exceeds a specific length threshold, ensuring the model remains concise even when token dilution is resolved 4142.
MoE Collapse and Sequence-Level Optimization (GSPO): In advanced MoE models, sophisticated routing mechanisms dynamically distribute tokens across various expert networks. GRPO utilizes a token-level importance sampling (IS) ratio. When processing complex, 10,000-token multi-step reasoning sequences, applying highly variable IS ratios token-by-token introduces massive, high-variance gradient noise. This noise compounds exponentially, frequently causing the routing mechanisms in MoE models to collapse entirely during RL training 424316.
Researchers at Alibaba resolved this critical MoE failure with Group Sequence Policy Optimization (GSPO) 381645. The fundamental insight of GSPO is aligning the basic unit of optimization with the unit of reward. Because the reward (e.g., determining if a math equation is correct or if code compiles) is granted at the sequence level, applying importance sampling at the token level creates a mathematical and theoretical disconnect 4647. GSPO rectifies this by defining the IS ratio based on the joint likelihood of the entire sequence:
$$\rho_{i}^{\mathrm{seq}} = \left( \prod_{t=1}^{|o_{i}|} \frac{\pi_\theta(o_{i,t} \mid x, o_{i,<t})}{\pi_{\text{ref}}(o_{i,t} \mid x, o_{i,<t})} \right)^{\frac{1}{|o_i|}}$$
By geometrically averaging the individual token probabilities, GSPO produces a single, highly stable sequence-level importance ratio. Applying clipping and optimization to this sequence-level ratio drastically reduces the variance of the gradient updates. Empirical results demonstrate that GSPO completely prevents MoE routing collapse without necessitating ad-hoc, computationally expensive engineering fixes like routing replay, allowing models to utilize their full parameter capacity during reinforcement learning 16454849.
Comparative Analysis: Computational Efficiency and End-Task Benchmarks
The dichotomy between online RL (PPO) and offline preference learning (DPO and SimPO) presents practitioners with a fundamental architectural trade-off: theoretical optimality and exploration versus computational accessibility and speed. Table 2 details the comparative performance of these algorithms across varied task domains.
Table 2: Benchmark Performance and Efficiency Comparison
| Metric / Benchmark | PPO (Online RLHF) | DPO (Offline Preference) | SimPO (Reference-Free) | Key Finding / Observation |
|---|---|---|---|---|
| VRAM Requirement (7B Model) | ~4x Model Size | ~2x Model Size | ~1x Model Size | PPO is severely bottlenecked by the Value Model. DPO halves the footprint. SimPO is highly memory efficient 34. |
| Training Throughput | Low | High | Highest | PPO requires generating rollouts mid-training; DPO and SimPO optimize instantly over pre-calculated datasets 1233. |
| Code Generation (APPS, CodeContest) | State-of-the-Art | Moderate Degradation | N/A | PPO consistently outperforms DPO in strict logic and programming tasks 1750. |
| Mathematical Problem Solving (GSM8K) | Superior (+1.3 to 2.5 pts) | Suboptimal | Moderate | PPO's online exploration discovers new trajectories; DPO is confined to specific CoT paths in its static dataset 50. |
| AlpacaEval 2.0 (Length-Controlled) | Competitive | Baseline | +6.4 pts over DPO | SimPO effectively neutralizes length exploitation, leading to superior perceived quality without verbosity 2551. |
| Arena-Hard (Win Rate) | Competitive | Baseline | +7.5 pts over DPO | SimPO's target reward margin leads to superior separation of high-quality responses in conversational domains 2513. |
| Distribution Shift Tolerance | High (Robust) | Low (Fragile) | Moderate | PPO handles out-of-distribution prompts well; DPO suffers catastrophic collapse if the reference model diverges 1217. |
Rigorous empirical studies consistently demonstrate that while DPO matches or exceeds PPO in standard conversational dialogue and summarization, PPO definitively outperforms DPO in domains requiring rigorous structural correctness, such as competitive programming and mathematical proofs. On average across diverse testbeds including StackExchange, Nectar, and UltraFeedback, PPO holds a quantifiable advantage over DPO, specifically driving improvements of up to 2.5 points in mathematics and 1.2 points in general domains 5052.
However, for practitioners focused primarily on chat alignment rather than logic, SimPO has proven exceptionally potent. By enforcing length-normalized rewards and removing the reference model anchor, SimPO outperforms standard DPO by up to 6.4 points on AlpacaEval 2.0 and 7.5 points on Arena-Hard, establishing itself as the premier offline method for conversational optimization 2551.
Real-World Implementations in Frontier Open-Weight Models
The theoretical debates surrounding alignment algorithms are ultimately settled by their deployment strategies in frontier open-weight models. The leading global AI laboratories have adopted distinct, highly customized post-training pipelines tailored to their specific scale and architectural designs.
Meta: Llama 3 and Llama 3.1 Pipeline Architecture
Despite possessing the immense compute resources necessary to deploy PPO at scale, Meta opted to align the Llama 3 and 3.1 families - ranging from 8 billion up to 405 billion parameters and supporting extended 128K context windows - primarily using a highly modified, iterative DPO pipeline 53545517. Meta researchers found that DPO yielded superior performance on critical instruction-following benchmarks like IFEval, while requiring significantly less compute footprint than PPO for large-scale models 5417.
However, deploying vanilla DPO was insufficient at the 405B scale. Meta implemented two critical algorithmic modifications to stabilize the training dynamics: First, they instituted the masking of formatting tokens. In standard DPO, special formatting tokens such as headers and termination identifiers appear simultaneously in both the chosen and rejected responses. The contrastive nature of the DPO loss forces the model to simultaneously increase and decrease the likelihood of these identical structural tokens. This conflict destabilizes training, causing models to either repeat response tails indefinitely or abruptly hallucinate termination tokens early 535517. Meta resolved this by explicitly masking these specific tokens from the loss calculation, decoupling formatting from preference optimization 5457.
Second, Meta appended an NLL regularization loss. To prevent aggressive DPO from catastrophically degrading the foundational language modeling capabilities acquired during pre-training and SFT, an auxiliary Negative Log-Likelihood (NLL) loss term with a scaling coefficient of 0.2 was applied exclusively to the chosen sequences. This addition anchors the policy, ensuring it maintains desired formatting and baseline fluency while navigating the preference landscape 551757.
Alibaba: Qwen 2.5 and Qwen 3 Hybrid Alignment
Alibaba's Qwen team has pioneered a sophisticated, multi-stage hybrid alignment strategy. Following an aggressive pre-training phase that scaled from 7 trillion to a massive 18 trillion high-quality tokens to build expert knowledge, the post-training pipeline for Qwen 2.5 initiates with over 1 million diverse SFT samples 345818.
Crucially, the Qwen post-training utilizes a sequential application of both offline and online methods to maximize model capability. The pipeline deliberately begins with offline DPO to rapidly establish foundational human preference alignment, ensure stylistic control, and embed core safety guardrails efficiently 3460. Once the base policy is stabilized via DPO, the pipeline transitions to online reinforcement learning to drastically enhance complex problem-solving and long-context capabilities 3458. While the Qwen 2.5 generation utilized standard GRPO, the transition to the more complex Qwen 3 integrated the proprietary Group Sequence Policy Optimization (GSPO) algorithm. This strategic shift to sequence-level likelihood normalization proved critical for maintaining gradient stability across their massive MoE architectures, allowing Qwen to scale RL effectively without the token-level variance collapse that plagues standard GRPO 431645.
Zephyr and Community Validation
In the broader open-source ecosystem, smaller but highly capable models like HuggingFace's Zephyr series heavily popularized the efficacy of the DPO methodology. The Zephyr-7B-beta model was aligned using vanilla DPO trained on the binarized UltraFeedback dataset 719. This implementation established early, vital proof that carefully tuned offline alignment - specifically identifying that a highly constrained $\beta$ hyperparameter value of 0.01 was optimal - could allow a compact 7B model to punch significantly above its weight class in rigorous MT-Bench evaluations, achieving state-of-the-art conversational performance without incurring the massive infrastructure overhead required by PPO 71962.
Conclusion
The post-training alignment of Large Language Models has rapidly transitioned from a monolithic reliance on Proximal Policy Optimization to a highly diversified, sophisticated ecosystem of specialized algorithms. Direct Preference Optimization successfully democratized alignment by mathematically recasting reinforcement learning as a streamlined classification problem, yet its inherent vulnerabilities to length exploitation, OOD degradation, and noisy preference data quickly necessitated extensive innovation.
The current machine learning frontier is characterized by a strategic, bifurcated approach. For conversational alignment, stylistic adherence, and safety supervision, highly modified offline algorithms like SimPO and ORPO offer unparalleled compute efficiency, robust length control, and reference-free scalability. However, for pushing the absolute boundaries of autonomous cognitive generation, verifiable mathematical logic, and complex coding, the industry has definitively pivoted back to the exploratory power of online reinforcement learning. The advent of Group Relative Policy Optimization (GRPO) and its sophisticated sequence-level derivatives (DAPO, GSPO) has successfully decoupled the profound benefits of online exploration from the crippling memory overhead of legacy Value Models. Ultimately, the state-of-the-art is no longer defined by a single, monolithic algorithmic choice, but rather by the sequential orchestration of these diverse methodologies - leveraging offline preference optimization to establish a stable behavioral foundation, followed by targeted, critic-free online reinforcement learning to unlock higher-order, multi-step problem-solving capabilities.