Differential Privacy in AI Training
The exponential scaling of deep learning architectures, particularly large language models and foundation vision models, relies fundamentally on the ingestion of internet-scale datasets. While this paradigm yields unprecedented generative and analytical capabilities, it introduces severe vulnerabilities regarding data memorization. Neural networks routinely memorize idiosyncratic training examples, leaving the models susceptible to data extraction, model inversion, and membership inference attacks 123. Through these attack vectors, adversaries can reconstruct sensitive personally identifiable information, proprietary corporate data, or copyrighted materials simply by interacting with a model's inference application programming interface 23.
To provide mathematical guarantees against such memorization, the field of privacy-preserving machine learning has operationalized differential privacy. Originally developed for statistical database queries, differential privacy has been adapted into the neural network training loop, bounding the influence of any single training example. This ensures that a model's final weights, and consequently its inference outputs, are statistically indistinguishable regardless of whether a specific data point was included in the training corpus 14.
This report provides an exhaustive analysis of differential privacy in artificial intelligence training. It details the mathematical mechanisms that enforce privacy, the severe computational and memory overheads introduced by per-sample gradient processing, the disparate impact of privacy noise on model fairness, and the real-world engineering compromises required to deploy these systems at an enterprise scale. Furthermore, it synthesizes the evolving global regulatory landscape, including standards from the National Institute of Standards and Technology and the International Organization for Standardization, alongside legislative frameworks governing data privacy.
Mathematical Foundations of Differential Privacy
Differential privacy provides a rigorous framework for quantifying and limiting the privacy loss associated with data analysis 56. Rather than relying on heuristic de-identification techniques, which are routinely bypassed using auxiliary data to re-identify individuals, differential privacy addresses the root vulnerability by injecting calibrated statistical noise 57.
Epsilon and Delta Parameters
The formal definition of differential privacy centers on two distinct mathematical parameters, epsilon and delta. A randomized algorithm is defined as satisfying differential privacy if, for all possible output sets and for any two neighboring datasets that differ by exactly one record, the probability of producing a given output on the first dataset is bounded by a multiplicative factor of the probability of producing that output on the second dataset, plus a small additive constant 1234.
The epsilon parameter represents the privacy loss budget, measuring the maximum allowable multiplicative difference in the output probabilities. It strictly bounds the worst-case information leakage. A smaller epsilon value corresponds to stronger privacy guarantees, as it forces the distributions of the algorithm's outputs on neighboring datasets to be more identical 1389. For context, if the epsilon value is set to 0.1, an attacker is only 1.1 times more likely to learn something about an individual compared to a baseline scenario where that individual's data had never been processed 9.
The delta parameter accounts for a strictly small probability of failure where the pure multiplicative bound might not hold. In practice, delta is set to be significantly smaller than the inverse of the dataset size to prevent the algorithm from bypassing the privacy mechanism by simply releasing a few raw records at random 18.
The Post-Processing Property and Sequential Composition
Two foundational theorems make differential privacy highly viable for machine learning applications: the post-processing property and sequential composition.
The post-processing property dictates that if a machine learning model's parameters are trained under a differential privacy guarantee, any subsequent computation applied to those parameters cannot degrade the original privacy bound 2. This applies to downstream inference generation, further fine-tuning on non-private data, or model quantization. If the model weights themselves are mathematically proven not to leak training data, the outputs generated by querying those weights are inherently protected 2.
Sequential composition allows developers and researchers to track privacy loss across multiple mathematical operations 810. If an algorithm accesses a private dataset multiple times, such as calculating gradients over multiple epochs of machine learning training, the total privacy loss accumulates. Under basic composition theorems, querying a differentially private mechanism multiple times yields a linear growth in privacy loss 10. Because deep learning requires thousands of iterative steps, basic composition results in unacceptably loose privacy bounds, necessitating more advanced privacy accounting frameworks.
Differentially Private Stochastic Gradient Descent
To impart differential privacy onto a deep neural network, the standard training optimization algorithm must be fundamentally altered. In 2016, researchers introduced Differentially Private Stochastic Gradient Descent (DP-SGD), a method that embeds privacy directly into the optimization loop 111.

Vulnerabilities in Standard Stochastic Gradient Descent
Standard stochastic gradient descent updates model weights by computing the gradient of a loss function over a mini-batch of training examples. The standard update rule aggregates the gradients of all examples in the batch by averaging them, and the model steps in the opposite direction of the gradient to minimize the predictive error 1.
The critical vulnerability in this standard approach is that a gradient serves as a direct mathematical representation of how much the model needs to adjust its internal parameters to fit a specific data point. If an anomalous, unique, or highly sensitive training example is sampled, its individual gradient might be exceptionally large. When this gradient is aggregated and applied to the model parameters, the weights shift significantly to accommodate that exact data point. An adversary observing the final model weights can then infer the presence of that data point, executing a membership inference attack, or reverse-engineer its features through data extraction methodologies 13.
Per-Sample Gradient Computation and Clipping
Differentially Private Stochastic Gradient Descent neutralizes the vulnerabilities of standard training algorithms through three core operational pillars 1. The first and second pillars revolve around strictly limiting the sensitivity of the parameter update. To bound the extent to which any single training example can influence the aggregate gradient, the algorithm must calculate the gradients for each example individually, rather than computing a single generalized gradient for the entire batch 1212.
Once these per-sample gradients are computed, they are subjected to an algorithmic clipping operation based on their L2 norm. If the L2 norm of a specific per-sample gradient exceeds a predefined clipping threshold, the gradient vector is scaled down proportionally so its norm exactly equals the threshold limit 21012. If the norm is already below the threshold, the vector remains unchanged.
This gradient clipping mechanism serves a mathematically vital purpose by enforcing a strict upper bound on the sensitivity of the gradient function 210. Because no single data example is permitted to produce a gradient with a norm larger than the specified threshold, the maximum possible difference that any one example can make to the aggregate batch gradient is strictly contained. Bounding this sensitivity is the absolute mathematical prerequisite for calculating the exact amount of statistical noise required to successfully mask the data point 210.
Gaussian Noise Injection and Privacy Accounting
The third pillar is the injection of calibrated statistical noise. After the per-sample gradients are clipped to the threshold, they are aggregated together. Before this aggregated gradient vector is utilized to update the neural network's weights, Gaussian noise is added directly to it 112.
Because the maximum influence of any sample is bounded by the clipping threshold, adding noise sampled from a Gaussian distribution ensures that the inclusion or exclusion of any single training example is statistically masked by the variance of the noise 1011. The magnitude of this noise is determined by a specified noise multiplier hyperparameter, combined with the clipping threshold itself 1211.
To ensure that the training process remains viable over thousands of iterative steps without fully depleting the privacy budget, implementations rely on advanced privacy accounting mechanisms, most notably the Moments Accountant and Rényi Differential Privacy 13121112. Traditional composition theorems sum privacy loss linearly, resulting in rapid budget exhaustion. The Moments Accountant tracks the higher-order moments of the privacy loss random variable, yielding a much tighter mathematical bound on the cumulative loss. This advancement allows deep learning models to undergo extensive training epochs while maintaining single-digit epsilon guarantees 1012.
Algorithmic Comparison of Gradient Descent Methods
| Feature | Standard Stochastic Gradient Descent | Differentially Private Stochastic Gradient Descent |
|---|---|---|
| Gradient Calculation | Computed collectively over the entire mini-batch | Computed individually for each specific sample in the mini-batch |
| Sensitivity Bound | Unbounded; anomalous inputs yield massive parameter shifts | Strictly bounded by the defined L2 norm clipping threshold |
| Noise Addition | None; parameter updates rely purely on the dataset's empirical loss | Calibrated Gaussian noise injected into the aggregate gradient per update step |
| Convergence Speed | Fast, dictated purely by learning rate and model architecture | Slower; noise injection reduces the signal-to-noise ratio during learning |
| Memory Overhead | Requires storing a single aggregate gradient matrix | Requires storing individual gradient matrices for every sample in the batch |
| Privacy Guarantee | None; highly vulnerable to data extraction and model inversion | Mathematically proven differential privacy against memorization attacks |
Table 1: Technical comparison highlighting the structural and mathematical differences between standard optimization and privacy-preserving optimization frameworks. 121011121113
Computational Overheads in Large Language Models
While the theoretical guarantees provided by differential privacy optimization are robust, its practical application to modern large language models has been severely bottlenecked by extreme computational and memory overheads 11141516.
Memory Constraints of Per-Sample Gradients
The requirement to compute per-sample gradients forces the training algorithm to instantiate and store distinct gradient vectors for every individual example in a batch simultaneously 2111417. In standard backpropagation algorithms, memory consumption for gradient computation is proportional to the size of the largest layer in the model. However, explicitly storing per-sample gradients before aggregation inflates memory consumption proportionally to the batch size multiplied by the parameter volume. For models possessing billions of parameters, this linear scaling rapidly exceeds the physical memory capacity of even the most advanced datacenter accelerators, resulting in catastrophic out-of-memory errors that prevent end-to-end pre-training 11131418.
Early libraries designed to handle these constraints utilized explicit instantiation or micro-batching methodologies. While these techniques allowed algorithms to run across all layer types without crashing, they sacrificed tremendous computational training speed 214. Ghost clipping emerged as an implicit alternative that reduced memory footprints by recalculating gradients multiple times to calculate norms without storing the full gradient matrix. However, this approach merely traded memory limitations for severe computational redundancy, increasing training durations exponentially 141719.
Implicit Computation and Optimization Techniques
Recent algorithmic breakthroughs have addressed these core engineering constraints. In 2024 and 2025, researchers introduced highly optimized training systems such as FlashDP, an innovative, cache-friendly implicit algorithm designed specifically to streamline the per-layer clipping process 11141719. FlashDP successfully consolidates the necessary gradient operations into a single computational task, calculating gradients in a fused manner that avoids intermediate storage.
By completely avoiding the explicit storage of per-sample gradients and eliminating the recalculation steps required by earlier implicit methods, this framework diminishes memory movement by up to 50 percent and reduces redundant computations by 20 percent 11141719. In rigorous benchmark testing involving the fine-tuning of a 13-billion parameter model on clustered graphical processing units, FlashDP achieved a remarkable 90 percent throughput compared to standard non-private algorithms.
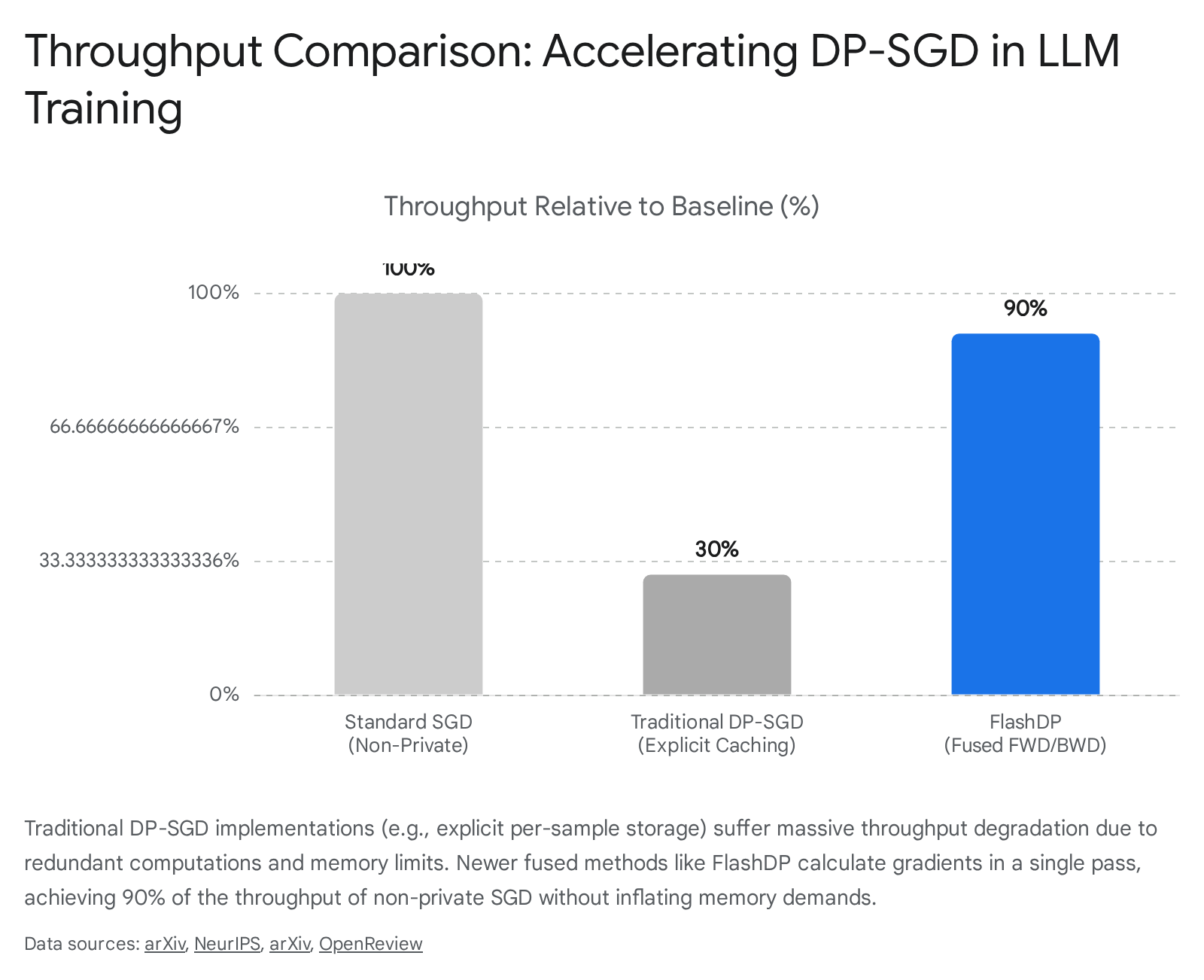
It operated without requiring any additional memory overhead while maintaining strict parity with the expected accuracy and privacy guarantees of traditional implementations 11141719.
Alternatively, specific sub-fields have explored zeroth-order optimization techniques to circumvent backpropagation entirely 1320. These methods approximate gradients by perturbing model weights with random vectors and calculating the corresponding difference in the forward pass loss function 13. Because zeroth-order optimization does not compute exact gradients via backpropagation, its memory reduction is highly significant, theoretically allowing large models to be fine-tuned on consumer-grade hardware. However, these methods historically suffer from a severe drop in utility and significantly slower convergence rates compared to first-order methods, requiring highly advanced algorithmic variants to reach viable privacy-utility tradeoffs in practical deployment 1320.
Parameter-Efficient Fine-Tuning and Differential Privacy
Due to the immense computational and financial cost of full parameter model training, the artificial intelligence industry has almost universally shifted toward parameter-efficient fine-tuning methodologies, particularly low-rank adaptation 4232125. Low-rank adaptation algorithms freeze the massive pre-trained weights of the model and inject small, trainable rank decomposition matrices into specific transformer layers 4122322. Applying differential privacy specifically to these parameter-efficient algorithms has become a highly active research domain with distinct mathematical advantages.
Noise Robustness in Low-Rank Subspaces
Algorithms explicitly designed for this paradigm inject statistical noise only into the gradient updates of the specific low-rank matrices 41223. This localized application generates a profound structural advantage regarding model degradation. Because the low rank heavily restricts the dimensionality of the trainable parameter space, the gradient perturbations caused by the Gaussian noise are distributed over a significantly smaller mathematical subspace 412.
In a fully fine-tuned model, the massive number of parameters requires a proportionately massive total noise magnitude to maintain the mathematical guarantee, which severely distorts the learned representations of the network 12. By utilizing low-rank adaptation, the total scale of the added noise is minimized, leading to vastly more stable optimization and higher end-state accuracy while satisfying identical privacy constraints 41224.
Inherent Privacy Guarantees via Random Sketching
Furthermore, recent theoretical research has uncovered that specific low-rank configurations offer inherent differential privacy properties without the strict necessity for additive Gaussian noise 232122. Theoretical analyses of specific matrix configurations, where one matrix is generated randomly and frozen while the other is iteratively trained, demonstrate that a single training step is mathematically equivalent to applying a random Wishart projection directly to the batch gradients 2122.
By treating the randomness of the projection matrix itself as the underlying privacy mechanism, researchers have proven formal privacy guarantees. In this random sketching paradigm, the noise variance acting upon the model is an intrinsic, decreasing function of the adaptation rank 232122. Consequently, lowering the matrix rank restricts both memory usage and potential privacy leakage simultaneously, offering a unique theoretical pathway to private fine-tuning that sidesteps the severe utility degradation traditionally caused by explicitly adding massive amounts of noise to gradient distributions 232122.
Disparate Impact on Model Accuracy
While differential privacy successfully guards against adversarial memorization, the fundamental mechanics of the algorithm introduce a highly documented and deeply problematic side effect: a severe and disparate degradation in model accuracy for underrepresented demographic groups and long-tail data distributions 162526272829.
Disproportionate Utility Degradation in Minority Data
The operational cost of differential privacy is fundamentally a reduction in model utility; however, empirical research proves this cost is not borne equally across the dataset. Models trained with mathematical privacy bounds consistently exhibit a dynamic where poorly represented data classes suffer the most severe degradation 162528. For example, in facial recognition tasks utilizing diverse global datasets, models trained via privacy algorithms exhibited much steeper accuracy drops for minority faces than for majority demographics when compared directly to baseline models 16252628. Similarly, in natural language processing tasks, private models tend to only output extremely popular vocabulary patterns, failing to generate rare text and disproportionately harming downstream users with localized dialects or unique linguistic profiles 2628.
If a standard, non-private neural network is already biased against a minority group due to dataset imbalances, applying privacy algorithms drastically amplifies that baseline unfairness 252728. This establishes a direct conflict between two major goals of trustworthy artificial intelligence deployment: securing user data privacy and ensuring algorithmic fairness 293031.
Structural Causes of Algorithmic Bias Amplification
The disparate impact of these privacy systems is not a flaw in software implementation, but a direct mathematical consequence of the algorithmic mechanisms themselves, specifically gradient clipping and noise addition 1625262728.
During gradient descent, the neural network learns features corresponding to the majority data class very quickly. Because the model rapidly learns to predict these common features accurately, the resulting prediction error is small, which in turn generates small per-sample gradients 2526. Conversely, data points from underrepresented groups or complex long-tail distributions are mathematically harder to learn and occur far less frequently. When the model encounters one of these minority data points, the predictive error is large, producing a correspondingly high-magnitude gradient vector intended to force the model to learn the new feature 2526.
Under a privacy-preserving framework, these large, informative gradients are aggressively scaled down by the mandatory clipping threshold 162528. This algorithmic clipping effectively chokes the learning rate for the minority groups, physically preventing the model from adjusting its weights to account for their unique features 25. Subsequently, the massive Gaussian noise injected into the aggregate batch gradient easily drowns out the clipped, infrequent signals of the minority class, while the abundant, consistent, unclipped signals of the majority class survive the noise injection 162526. Ultimately, the privacy algorithm heavily amplifies the model's natural bias toward the most central, popular elements of the data distribution 28.
Mitigation Strategies and Adaptive Frameworks
Addressing this mathematical deadlock requires heavily modifying standard optimization routines. Frameworks focusing on adaptive noise allocation propose moving away from a uniform noise distribution across all parameters. Instead, these algorithms measure specific parameter importance and dynamically adjust the noise injection to preserve the critical learning pathways required for complex, long-tail data 32.
Other algorithmic solutions attempt to apply coordinate-wise clipping to gradients specifically to address the heavy-tailed noise inherent in skewed datasets, providing mathematical stability without destroying the gradient signal 3334. Additionally, hybrid systems have been introduced that decouple the core privacy mechanisms from explicit data redaction filters. These systems offer adjustable privacy budgets - referred to conceptually as epsilon dials - that allow administrators to limit utility degradation on specific layers while maintaining overarching compliance controls 7.
Cryptographic Alternatives and Hybrid Synergies
Differential privacy is rarely deployed as an isolated system; it is part of a broader ecosystem of privacy-enhancing technologies. In enterprise and academic literature, it is routinely compared against, and increasingly combined with, homomorphic encryption and federated learning 3540363743.
Federated learning decentralizes the entire training architecture. Instead of centralizing raw user data in a single datacenter, the base model is sent directly to edge devices or distinct organizational silos. The individual devices train the model locally on their private data and only transmit the updated gradients back to a central server for aggregation 35403637. While this protocol protects raw data at rest, the shared gradients transmitted across the network can still be intercepted and reverse-engineered via model inversion attacks, necessitating further cryptographic or statistical protection 3540.
Homomorphic encryption provides a purely cryptographic solution by allowing mathematical computations to be performed directly on encrypted data ciphertexts. In a distributed context, clients send homomorphically encrypted gradients to the central server. The server can aggregate these gradients mathematically without ever holding the decryption key or viewing the underlying values 35403637.
Comparison of Privacy Enhancing Technologies
| Technology Framework | Core Security Mechanism | Primary Vulnerability Mitigated | Associated Computational Overhead | Impact on Model Output Accuracy |
|---|---|---|---|---|
| Federated Learning | Decentralized, local data processing; only gradient weights shared | Centralized raw data exposure and catastrophic single-point-of-failure breaches | Moderate (Relies heavily on network communication bandwidth and edge compute) | Negligible (Assuming distributed data is independent and identically distributed) |
| Homomorphic Encryption | Advanced cryptographic computation directly on ciphertext | Server-side interception of gradients during centralized aggregation | Extremely High (Encryption/decryption cycles cause massive latency delays) | None (Computations are mathematically exact, preserving full baseline utility) |
| Differential Privacy | Algorithmic statistical noise injection and strict gradient clipping bounds | End-state training data extraction, membership inference, and memorization | Low to Moderate (Optimized significantly via fused implicit algorithms) | High (Trades exact predictive accuracy for worst-case mathematical privacy guarantees) |
Table 2: Technical comparison analyzing the mechanics, operational costs, and accuracy impacts of the three primary privacy-enhancing technologies utilized in distributed machine learning. 3540363743
To achieve state-of-the-art security, sophisticated enterprise systems actively combine these disparate technologies into hybrid stacks. For instance, a secure architecture might utilize federated learning to distribute the physical training process, apply differential privacy on the client side to inject noise into the local gradients, and simultaneously utilize homomorphic encryption protocols to securely aggregate those noisy gradients on the server. This multi-layered approach ensures comprehensive protection against inquisitive central servers, intercepted network communications, and adversarial inference attacks against the final model 35403743.
Empirical Implementations and Practical Privacy Budgets
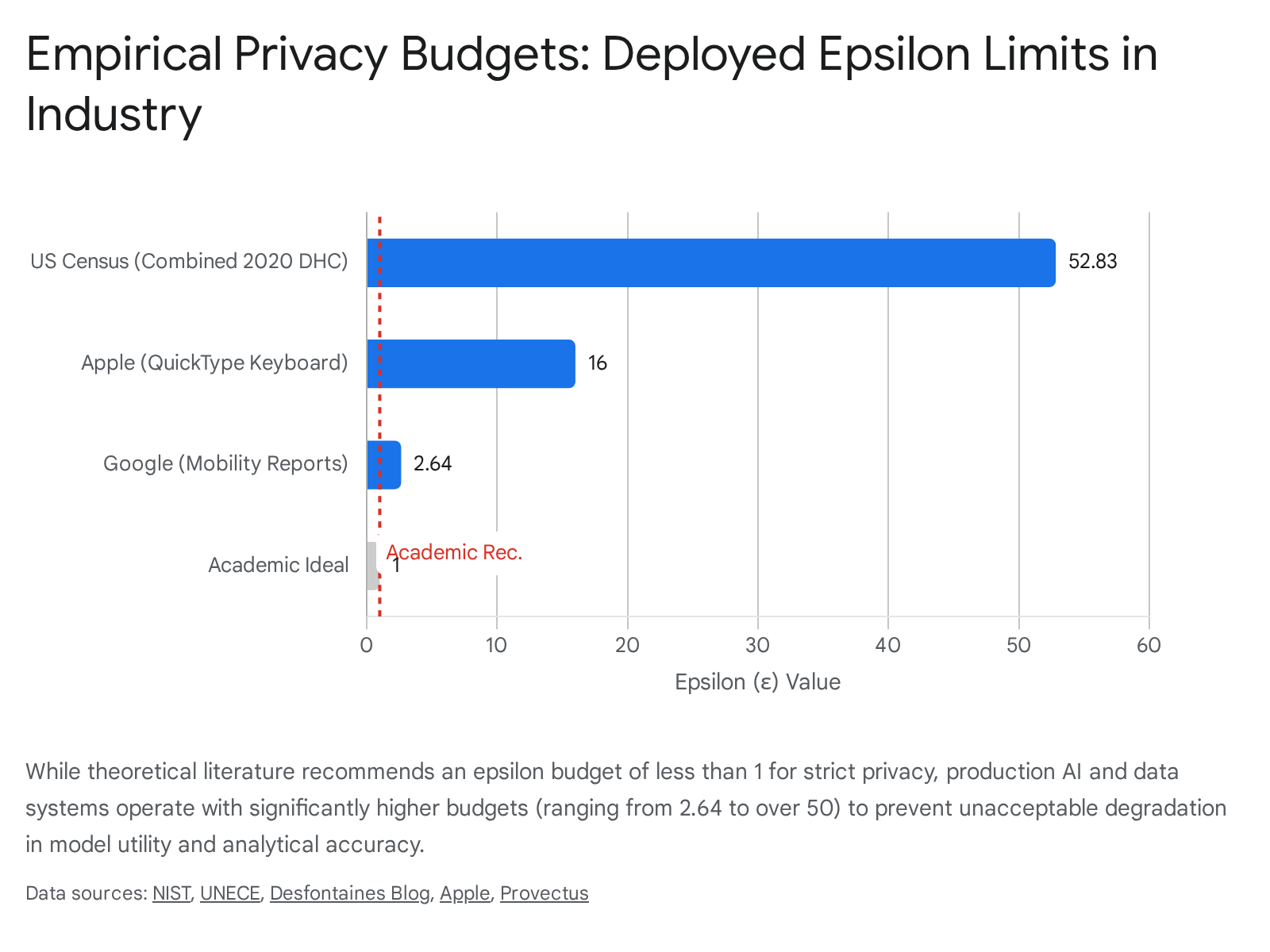
While academic literature generally argues that an epsilon value of $1$ or smaller represents the only truly robust privacy guarantee, real-world commercial deployments universally adopt much larger budgets. Operating at pure academic bounds causes unacceptable utility loss in high-dimensional analytical tasks like natural language generation and high-resolution computer vision 3838. Consequently, major technology firms rely on pragmatic engineering tradeoffs, utilizing values that theoretically appear loose, but which empirically defend against current sophisticated data extraction techniques 3838.
Production Configurations at Major Technology Firms
In commercial practice, acceptable privacy thresholds vary significantly based on the specific modality of the data and the required utility of the downstream application.
- Anthropic: For its production-scale privacy-preserving analytics system, which evaluates millions of user interactions, the firm operates with epsilon bounds between 3 and 8. External researchers have successfully fine-tuned large language models using an epsilon of 8, indicating that this specific mathematical threshold - meaning specific outputs can vary by thousands of times based on single records - serves as an acceptable empirical standard for large commercial models, offering highly bounded leakage when compared directly to unprotected networks 32439.
- Apple: The company relies heavily on local algorithms across its mobile and desktop ecosystems, with budgets allotted on a strict per-user, per-day basis. Emoji suggestion analytics operate at an epsilon of 4, web browser auto-play intent detection functions at an epsilon of 8, and predictive text models require an epsilon of 16 384041.
- Google: For its high-profile public mobility reports utilized heavily during the pandemic, the firm utilized a specific daily epsilon allowance of 2.64 per tracked user 3840.
- United States Census Bureau: To preserve the critical statistical utility of mandatory demographic tabulations, the 2020 redistricting data was released using custom algorithms operating with a much higher budget. Demographic person tables utilized an epsilon of 26.34, while separate housing unit tables utilized 34.33, resulting in a massive combined production privacy budget exceeding an epsilon of 50 83840.
Contextual Defenses and Synthetic Data Generation
The massive variance in acceptable epsilon tolerances directly highlights the deep context dependency of privacy bounds 938. Standard mathematical definitions assume that neighboring datasets differ by merely a single, isolated example. However, in modern machine learning training environments, a single user often contributes hundreds or thousands of distinct data points to the corpus. If algorithms only secure data at the individual example level, a sophisticated attacker might still infer a user's presence by cross-referencing multiple leaked examples that form a behavioral pattern 15.
To combat this systemic vulnerability, leading technology platforms strive to implement user-level guarantees, which redefine the mathematical boundary to ensure that the entire model remains statistically indistinguishable whether all of a specific user's aggregated data is included or completely removed 15. Learning under these user-level constraints is strictly harder and requires adding significantly larger volumes of statistical noise, which further explains the industry push toward higher epsilon allowances in proprietary deployments 15.
Alternatively, organizations with stringent privacy requirements are entirely bypassing complex internal training protocols by utilizing pre-trained foundation models through application programming interfaces to generate synthetic data. By wrapping rigorous algorithmic mechanisms around the generation process, firms can produce highly realistic, synthetic text corpora that share identical statistical insights with the underlying private data, allowing them to train downstream models or share analytical insights externally without directly handling user data or violating compliance frameworks 42434445.
Regulatory Frameworks and Technical Standards
As generative models consume exponentially more personal data from public and private domains, international regulatory bodies have increasingly scrutinized algorithmic data processing. In response, differential privacy is rapidly transitioning from an obscure theoretical security mechanism into a highly standardized corporate compliance requirement.
National Institute of Standards and Technology Guidelines
Driven by direct mandates from the United States Executive Order on Safe, Secure, and Trustworthy Artificial Intelligence, the National Institute of Standards and Technology formalized and published its guidelines for evaluating privacy guarantees in early 2025 6464748.
This framework establishes specific, formalized criteria for independently verifying the privacy claims made by commercial software vendors and artificial intelligence developers 646. The guidelines explicitly require organizations to conduct deep data sensitivity assessments prior to deployment and warn heavily against specific operational hazards, detailing scenarios where improperly calibrated mathematical noise either fails completely to mask the targeted data, triggering a catastrophic breach, or destroys the statistical validity of the database entirely 54647. Concurrently, the institute's guidelines regarding generative artificial intelligence explicitly require developers to manage output risks, highly recommending statistical noise injection as an active mitigation strategy against the unauthorized disclosure or subsequent de-anonymization of personally identifiable information 48.
International Organization for Standardization Updates
The International Organization for Standardization executed a massive architectural shift in privacy management with its highly anticipated 2025 revision 554957. Prior versions of this standard functioned merely as optional extensions to pre-existing information security management systems. The updated standard fundamentally restructures this dynamic, establishing a fully independent, standalone framework strictly dedicated to privacy information management 5549.
This critical decoupling allows modern artificial intelligence startups, cloud-native infrastructure providers, and extensive data processors managing complex training environments to actively certify their privacy frameworks and map data governance protocols directly to international regulations without being forced to audit entirely unrelated security verticals 554957. The standard explicitly defines the operational and legal responsibilities of data controllers and processors, directly implicating AI development firms that scrape the web or train models on user-provided data 555051.
European Union Artificial Intelligence Act Standardization
The European Union's comprehensive legislative framework governing artificial intelligence mandates rigorous transparency protocols, active risk management oversight, and highly documented bias mitigation strategies for any software system categorized as high-risk 525354. To successfully operationalize these broad legal mandates into enforceable technical specifications, European commissions mandated continental standardization bodies to draft and finalize specific harmonized standards through dedicated joint technical committees 525354.
Technology companies adhering strictly to these published harmonized standards will automatically be granted a legal presumption of conformity with the broader legislative act, drastically simplifying market access 52. However, the massively ambitious scope of these standards - which attempt to legally codify everything from cyber-robustness algorithms to complex dataset governance taxonomies - has caused significant bureaucratic delays. While initially targeted for finalization in early 2025, these critical harmonized standards are now expected to be completed toward the end of the year, severely narrowing the operational window for global enterprise compliance before general legal enforcement takes full effect across the continent in late 2026 525455. Furthermore, the inherent conflict between the legislative requirements for strict algorithmic fairness and the mathematically proven disparate impact introduced by privacy-preserving training algorithms remains a heavily debated tension point among standard-setting bodies 2954.
Global Data Protection Legislation
Beyond technical benchmarking, major economies are aggressively enforcing broad legal protections against data extraction that impact model training.
The regulatory landscape in India is currently defined by legislation enacted in 2023, which relies on a phased implementation structure extending deeply into 2026 and 2027. This framework imposes exceptionally severe financial penalties for algorithmic non-compliance and relies heavily on strict purpose limitation concepts, forcing organizations to route authorizations through registered consent managers 5657585960. In Japan, data protection acts apply strictly extraterritorially, with sweeping amendments extending through 2026 establishing stringent administrative monetary penalties for foreign businesses handling Japanese data, heavily restricting the cross-border transfer of any personally referable information 61626373. Similarly, frameworks in China mandate absolute data minimization protocols and demand localized, government-approved security assessments before any personal information can be legally processed or transferred internationally for training purposes 6465666768.
Multinational organizations deploying and training foundational models must navigate this highly fractured global landscape, driving the rapid adoption of localized, mathematically proven protections to satisfy extraterritorial requirements quantitatively rather than relying purely on procedural legal defenses.
Conclusion
Differential privacy has fundamentally transitioned from theoretical cryptography into the mandatory operational infrastructure required to build secure, enterprise-scale artificial intelligence. By introducing rigid mathematical constraints into the learning cycle - specifically relying on gradient clipping to bound individual sensitivity, combined with calibrated statistical noise to completely mask participation - these algorithms provide the only quantifiable defense against adversarial memorization and data extraction.
While the theoretical foundations securing the data are absolute, the actual operationalization of these concepts in deep neural networks requires navigating highly complex engineering tradeoffs. Early implementations of these algorithms effectively paralyzed the training of multi-billion parameter models through catastrophic memory inflation, though recent architectural breakthroughs involving fused computation and localized low-rank adaptation have successfully neutralized these severe computational bottlenecks. However, a far more persistent and mathematically ingrained challenge is the disparate impact this required noise inflicts on overall model fairness, structurally and disproportionately degrading the learning utility of minority demographics and long-tail distributions. Furthermore, bridging the vast operational gap between the highly stringent epsilon bounds demanded by academic theory and the practical, high-utility allowances required for commercial deployment continues to necessitate careful, highly documented engineering compromises. As sprawling global frameworks, ranging from federal technology guidelines in the United States to sweeping continental legislation in Europe, move rapidly to harmonize the legal definitions of privacy, the mathematical precision of these specific algorithms remains the most reliable mechanism for developers to definitively prove legal compliance and secure user trust in a heavily scrutinized technological era.