Delayed Generalization in Neural Networks
Introduction to the Grokking Phenomenon
In the standard paradigm of machine learning and statistical learning theory, optimization typically dictates that a neural network's performance on training data and unseen validation data improve in tandem. When training accuracy saturates and reaches near perfection, practitioners assume the model has extracted all available generalizable patterns; continued training beyond this point is widely expected to yield severe overfitting, driving up validation loss. However, the discovery of a counterintuitive learning dynamic - where a neural network achieves perfect training accuracy, plateaus with random-chance validation performance for thousands of epochs, and then suddenly leaps to perfect generalization - has challenged these core assumptions. This phenomenon is known as delayed generalization, or "grokking" 12312.
First formally described in 2022 by researchers at OpenAI, the term "grokking" was adopted from Robert A. Heinlein's science fiction novel Stranger in a Strange Land, where it denotes an understanding so profound that the observer becomes one with the observed concept 378. The phenomenon was initially detected during experiments utilizing small, decoder-only transformer architectures trained on algorithmic datasets, such as modular addition ($a + b \pmod p$) and division. In these canonical experiments, training accuracy typically reached 100% within the first $10^3$ optimization steps, while validation accuracy hovered at roughly chance levels. Yet, when the researchers allowed the optimization process to run extensively - often out to $10^5$ or $10^6$ steps - the validation accuracy spontaneously climbed to 100% 134.
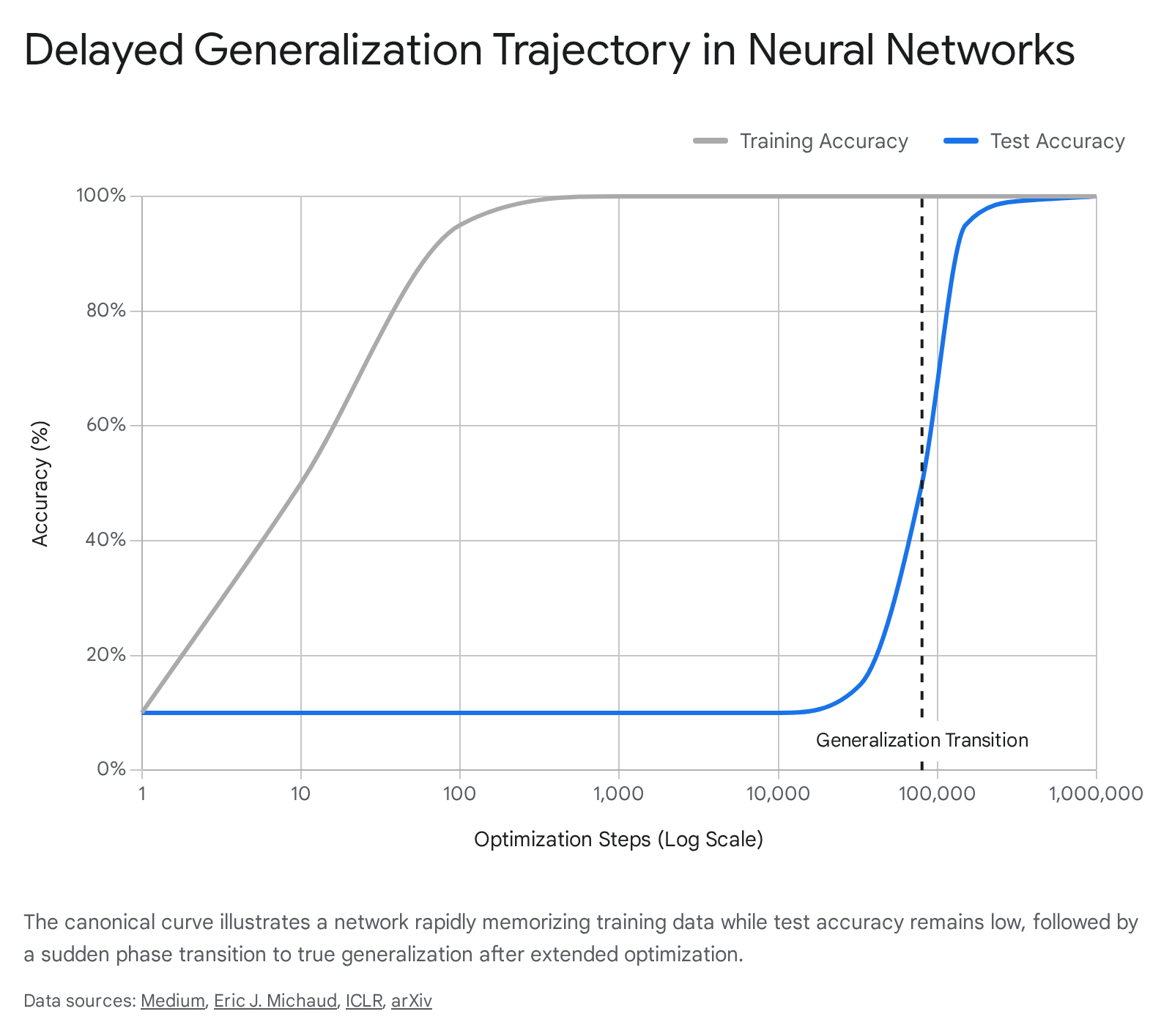
This stark temporal separation between the memorization of a finite training set and the subsequent acquisition of an underlying generative rule highlights a critical blind spot in classical deep learning intuition. The neural network's parameters do not remain static during the extended plateau. Instead, the model systematically explores the high-dimensional loss landscape, undergoing an invisible structural reorganization. Over time, the network abandons its fragile memorization strategies in favor of a highly compressed, efficient, and mathematically generalized solution 567. As research has advanced, delayed generalization has been observed not merely in algorithmic toy models, but across large-scale natural language pretraining, complex computer vision tasks, and hierarchical linguistic structures, making it a central subject of study for understanding how artificial systems learn to reason.
Theoretical Foundations and Network Dynamics
Circuit Competition: Memorization vs. Generalization
The dominant structural explanation for delayed generalization lies in the internal competition between two distinct classes of sub-networks, or "circuits," that form during gradient descent 8149. When a neural network is exposed to a dataset, it can satisfy the loss function through two mechanisms: rote memorization of the exact input-output pairs, or the extraction of the underlying mathematical logic.
Memorization circuits are highly accessible in the network's loss landscape and can be learned rapidly during early epochs. They effectively function as high-capacity, dense lookup tables. However, these circuits are deeply inefficient regarding parameter utilization. Because the network must allocate specific weight configurations for every individual data point it encounters, the parameter norm required to sustain memorization scales linearly as the dataset size grows 716.
Conversely, generalization circuits represent compressed, algorithm-like mechanisms. Because they require the precise alignment of multiple specific weight configurations to execute a logical operation, they take significantly longer to learn and develop very slowly. Crucially, once formed, the efficiency of a generalization circuit is entirely independent of the dataset size. The same core mechanism processes all data points without requiring additional parameter allocation 7917.
The transition between these two modes is dictated by a critical dataset size threshold. Below this threshold, memorization circuits are mathematically more efficient to maintain, and the model will stably overfit indefinitely 9. Above the critical dataset size, generalization circuits possess a structural and mathematical advantage. During training, the memorization circuit dominates initially, minimizing training loss. As optimization continues, regularization forces penalize the massive, inefficient parameter bloat of the memorization circuit. The optimizer slowly reallocates the parameter norm toward the nascent generalization circuit, culminating in a sudden outward spike in validation performance 7916.
| Characteristic | Memorization Circuit | Generalization Circuit |
|---|---|---|
| Learning Speed | Rapid; dominates early optimization steps. | Slow; requires extended training to align weights. |
| Parameter Efficiency | Low; parameter norm scales linearly with dataset size. | High; parameter usage is independent of dataset size. |
| Impact on Training Loss | Drives the initial, steep decline to near-zero. | Maintains low loss while improving robustness. |
| Validation Performance | Negligible; performance remains at random chance. | Near-perfect accuracy on unseen out-of-distribution data. |
| Response to Regularization | Degrades heavily under weight decay due to high parameter norm. | Strengthens and ultimately overtakes memorization. |
Optimization Stability and Weight Norm Thresholds
The shift from a memorized state to a generalized state is heavily governed by explicit regularization, most notably weight decay ($\ell_2$ regularization). Weight decay acts as the primary control parameter governing both the occurrence and the timing of delayed generalization, biasing the optimization process toward regions of the loss landscape characterized by lower weight norms, which correspond to generalizing solutions 418.
Empirical analyses demonstrate that delayed generalization occurs strictly within a narrow "Goldilocks zone" of regularization. If weight decay is too low, the model lacks the pressure required to abandon its memorization circuits and remains permanently trapped in an overfitted state 456. If weight decay is too aggressive, the penalization overwhelms the gradients entirely, causing the model to collapse and fail to learn either circuit 410.
Within this optimal regularization band, the phase transition is mathematically predictable. Studies utilizing width-512 multilayer perceptrons (MLPs) and dense Transformers indicate that generalization emerges consistently when the network's parameters decay to a highly specific root-mean-square (RMS) weight norm threshold. Across different architectures and activation functions, this critical threshold is tightly clustered at approximately 0.0219 410.
Furthermore, the choice of activation function (e.g., GELU versus ReLU) does not alter the fundamental geometry of the generalizing solution. Rather, the activation function strictly modulates the velocity of the weight norm decay. Models utilizing GELU activations achieve the critical RMS weight norm threshold significantly faster than those using ReLU (often up to four times faster), thereby accelerating the timeline of the phase transition without changing the underlying mathematical structure of the learned representation 410.
Mechanistic Interpretability and Reverse Engineering
The most definitive evidence for the structural reorganization driving delayed generalization is derived from the field of mechanistic interpretability. This subfield focuses on reverse-engineering learned neural behaviors into discrete, human-readable algorithmic components 111222.
When small transformers are trained on modular arithmetic tasks, they do not arrive at a fragmented patchwork of statistical heuristics. Instead, detailed analysis of their weight matrices reveals that vanilla gradient descent independently discovers the discrete Fourier transform 111223. The network effectively learns to map discrete integers into a circular topology, utilizing continuous trigonometric identities to process logical relationships. By converting inputs to frequencies, the model utilizes the mathematical identity $\cos(\omega(x+y)) = \cos(\omega x)\cos(\omega y) - \sin(\omega x)\sin(\omega y)$, transforming modular addition into a continuous rotation around a unit circle in the latent space 11122324.
Crucially, this elegant algorithmic structure does not materialize spontaneously at the exact moment validation accuracy spikes. Mechanistic analysis utilizing "excluded loss" metrics demonstrates that the Fourier-based generalizing circuit begins forming smoothly and continuously very early in the training process, entirely disproving the hypothesis that grokking is a random walk in model-space 112425. The outward suddenness of the generalization is an illusion caused by the circuit competition: the clean algorithmic solution only gains control of the model's output logits during a late-stage "cleanup" phase. This occurs when weight decay finally succeeds in pruning the dense, high-norm memorization pathways that had been masking the already-formed generalizing circuit beneath them 122225.
Thermodynamic and Information-Theoretic Perspectives
Synergy, Redundancy, and the Phase Transition
To capture the transition without relying on manual circuit reverse-engineering, researchers have turned to information-theoretic progress measures. By analyzing the multivariate mutual information among neurons, the learning process can be quantitatively mapped through the evolution of two distinct properties: "synergy" and "redundancy" 132728.
Synergy is defined as the cooperative behavior among variables, where the combined statistical interactions of a group of neurons yield predictive information that strictly exceeds the sum of their individual, isolated contributions. Redundancy, conversely, represents the shared, overlapping information distributed widely across multiple neurons 132714. Tracking these metrics reveals that the training dynamics partition into highly distinct thermodynamic phases:
| Training Phase | Information-Theoretic Signature | Network Behavior |
|---|---|---|
| 1. Feature Learning | Dominated by high redundancy; extremely low synergy. | The network extracts low-level, dataset-specific patterns, engaging in rote memorization without complex logic. |
| 2. Emergence | Rapid and sharp surge in synergy. | The network begins forming a localized, generalizing sub-network relying on higher-order neuronal interactions. |
| 3. Divergence/Overfitting | Temporary stagnation in synergy if weight decay is inadequate. | The network explores the loss landscape but struggles to compress the learned features. |
| 4. Decoupling and Compression | Synergy stabilizes; redundancy increases as pruning occurs. | The generalizing circuit assumes control. Memorization pathways are pruned, consolidating the generalized logic. |
These information-theoretic measures serve as highly reliable leading indicators. Anomalous, early-training peaks in synergy can accurately predict whether a model will eventually experience delayed generalization, long before any improvements are visible in the standard test loss 1314. This transition operates precisely like a physical phase change, with synergy functioning as a rigorous order parameter that signals the macro-level shift from a disordered, memorized state to a highly ordered, systematic state 14.
Computational Glass Relaxation and Entropy Landscapes
An alternative physical interpretation models delayed generalization as "computational glass relaxation" within an entropy landscape 5. In this framework, the neural network's parameters are viewed as degrees of freedom, and the training loss functions as the system's energy.
Experimental sampling of the network's Boltzmann entropy (the density of states) reveals that the initial memorization phase mimics the rapid cooling of a liquid into a non-equilibrium glassy state. The gradient descent optimizer aggressively drives the parameters into poor, narrow local minima to minimize immediate error 5. The subsequent plateau and delayed generalization phase is identified as a slow, structural kinetic relaxation toward a much more stable, higher-entropy configuration 5.
Crucially, experimental results in transformers suggest there is no actual "entropy barrier" separating the memorization state from the generalization state. This finding challenges earlier theories that modeled delayed generalization as a first-order phase transition requiring the system to cross a free-energy barrier 5. Because the macroscopic order parameter (equilibrium test accuracy) is continuous as a function of training loss, the network benefits from a massive "high-entropy advantage," where the sheer volume of solutions in the generalized parameter space inevitably pulls the system toward generalization if permitted to explore 5. This physics-inspired view has led to the development of novel optimizers - such as the Wang-Landau Molecular Dynamics (WanD) optimizer - which inject Langevin dynamics to encourage exploration of high-entropy states, effectively eliminating the delayed grokking gap and forcing the model to generalize rapidly without requiring explicit weight decay regularization 5.
Scaling Delayed Generalization to Complex Architectures
Local and Asynchronous Grokking in Large Language Models
Early research largely confined the study of delayed generalization to small multi-layer perceptrons or shallow transformers operating on synthetic, algorithmically generated datasets. However, recent empirical evidence confirms that the phenomenon scales to massive architectures, directly impacting the pretraining runs of Large Language Models (LLMs) 153132.
In the single-pass pretraining of 7-billion-parameter Mixture-of-Experts (MoE) foundation models (e.g., OLMoE), the transition from memorization to generalization is robustly verifiable, but it operates differently than in controlled toy models. Because real-world pretraining corpora are massively heterogeneous - containing distinct domains such as mathematics, code generation, logic puzzles, and commonsense reasoning - generalization does not occur synchronously across the entire network. Instead, the network exhibits local grokking 153233. Different data clusters enter their respective phase transitions asynchronously, depending heavily on the inherent complexity of the specific domain and its distributional representation in the training data 1534.
This local transition can be tracked mechanistically through the dynamics of the routing pathways in the MoE layers. Early in pretraining, expert routing for specific training instances is essentially random, non-smooth across sequential layers, and highly instance-specific - a clear structural signature of memorization. As local domains begin to generalize, the routing pathways evolve dramatically, becoming highly structured, predictable, and shareable across conceptually similar samples. Novel metrics evaluating "pathway similarity" between samples and "pathway consistency" across layers show that the effective complexity per sample decreases despite a converged overall pretraining loss. These pathway metrics provide a zero-cost, test-free indicator of emerging downstream reasoning capabilities, reducing reliance on expensive benchmark evaluations 153134.
Multi-Hop Factual Reasoning and Data Augmentation
The implications of delayed generalization also extend to the acquisition of implicit multi-hop factual reasoning in real-world Natural Language Processing (NLP) tasks. Standard, dense transformer architectures frequently struggle to reliably compose internalized facts unless they are explicitly guided by external structures like chain-of-thought prompting 1617. When evaluating tasks where the model must deduce a secondary logical conclusion from disparate primary facts (e.g., determining a historical event's timing by triangulating the lifespans of related figures), models exhibit a strong baseline tendency to memorize specific contextual pathways rather than learning generalized relational rules 3718.
However, researchers have found that inducing delayed generalization through targeted data augmentation can force the transformer to develop implicit reasoning circuits 16. By injecting carefully designed synthetic data into training knowledge graphs, researchers can manipulate the ratio of inferred facts to atomic facts ($\phi_r$). Once this critical ratio crosses a specific threshold, the transformer experiences a phase change, transitioning from fact-specific, localized memorization to near-perfect multi-hop generalization 163719.
Surprisingly, the content of the synthetic data is less important than its structure. Even if the synthetic data used to cross the threshold is factually incorrect, it still successfully catalyzes the formation of the reasoning circuit. This occurs because the sheer volume of interconnected nodes forces the model to prioritize the overarching relational structure of the graph rather than relying on the memorization of individual node attributes 1640.
Structural Grokking in Linguistics and Computer Vision
In the domain of syntax and linguistics, language models are tasked with generalizing linearly (learning simple sequential probabilities) or hierarchically (understanding nested, grammar-based sentence structures). For sequence models that lack explicit structural biases, linear memorization is significantly easier to learn and dominates early training phases 202122.
Prolonged training of vanilla transformers on complex linguistic data yields "structural grokking." Long after the models have completely saturated their in-domain accuracy utilizing shallow linear heuristics, they eventually undergo a delayed phase transition to deep hierarchical generalization 82023. This structural generalization demonstrates an inverted U-shaped correlation with network depth; models of intermediate depth achieve hierarchical structures much more reliably than extremely shallow or extremely deep networks 820. The onset of this transition is tightly correlated with internal metrics characterizing "tree-structuredness," rather than simple attention sparsity, suggesting that overparameterized networks eventually align their internal computational geometry with the syntactic complexity of human language solely through extended gradient descent 82022.
A highly parallel phenomenon is observed in computer vision. Standard convolutional neural networks (CNNs) rely on strict inductive biases - namely, translation invariance and locality - to learn spatial features efficiently. Vision Transformers (ViTs), lacking these inherent biases, historically required massive datasets (e.g., ImageNet-21k containing 14 million images) to avoid catastrophic overfitting and match standard CNN performance 2446. In data-constrained settings, pure Vision Transformers exhibit delayed generalization dynamics that precisely mirror those seen in NLP 24. The model initially treats 2D image patches as an unstructured sequence of visual words, fitting the training set through brute-force memory 24. However, with extended optimization and carefully tuned regularization, the ViT eventually extracts global spatial relationships and invariant feature structures 4625. The transition corresponds to the stabilization of spatial autocorrelation tokens, signaling that the network has ceased memorizing local noise and has generalized the topological structure of the visual data, allowing it to compete with highly optimized CNNs on standard benchmarks like ImageNet-1K 2526.
Late-Stage Pathologies and Optimization Instabilities
The Slingshot Effect
The phase transition toward generalization is rarely perfectly smooth; it is often preceded and accompanied by severe optimization instability. This instability, frequently termed the "slingshot effect," manifests as massive, cyclical spikes in both training and validation loss just before the generalizing circuit takes permanent hold of the network 418.
The slingshot mechanism is fundamentally driven by a mechanical tension between the gradient updates of an adaptive optimizer (such as AdamW) and the continuous pressure of weight decay. As the optimizer attempts to scale logits to aggressively minimize cross-entropy loss on memorized data points, weight decay simultaneously counteracts this expansion. This inherent tension repeatedly ejects the model from shallow, memorization-heavy local minima, forcing the parameters to traverse the loss landscape violently until they happen to fall into the broader, flatter, and more stable basin associated with the generalization circuit 4. Attention-based models, such as Transformers, exhibit a significantly higher variance in delayed generalization timing compared to standard MLPs precisely due to their acute sensitivity to these oscillatory weight-norm dynamics during the slingshot phase 418.
Anti-Grokking: Catastrophic Generalization Collapse
While extended training is necessary to induce delayed generalization, unbounded training in the absence of proper regularization introduces severe, late-stage failure modes. If a model is trained far past the point of initial generalization - for instance, up to $10^7$ optimization steps on the identical dataset without explicit weight decay - it risks entering a previously unreported third thermodynamic phase known as catastrophic generalization collapse, or anti-grokking 2728.
During anti-grokking, the model maintains perfect training accuracy, but test accuracy abruptly collapses from near 100% back down to random chance levels 275152. Because the $\ell_2$ weight norm continues to increase monotonically in unregularized settings, standard parameter norm metrics completely fail to predict or explain this collapse 2728.
The collapse can be diagnosed using Heavy-Tailed Self-Regularization (HTSR) theory, which evaluates the empirical spectral density of the network's weight matrices. The primary indicator of impending anti-grokking is a deviation of the heavy-tailed power-law exponent ($\alpha$) dropping significantly below 2.0. This spectral shift signals the emergence of "correlation traps" - anomalously large eigenvalues that separate from the Marchenko-Pastur bulk distribution 285152. These traps correspond directly to prototype memorization, a state where specific layers of the network become pathologically hyper-specialized to individual training instances. This hyper-specialization effectively destroys the previously learned generalized representation, causing the model to become fundamentally confused and fail completely on out-of-distribution test data despite retaining perfect recall of the training set 5152.
Skepticism and the Metric Illusion Debate
Hyperparameter Artifacts and Architectural Independence
Despite the extensive theoretical framing surrounding delayed generalization, there is a vocal subset of machine learning research arguing that the perceived mystery of the phenomenon is heavily inflated by hyperparameter imbalances. Early studies suggested that certain complex architectures, notably Transformers, were fundamentally more prone to massive delays in generalization compared to fully connected MLPs 4.
Recent systematic replication studies have largely dismantled this architecture-centric interpretation. When MLPs and Transformers are subjected to rigorously matched and grid-searched optimization regimes - carefully aligning learning rate, batch size, initialization scale, and weight decay - the apparent architectural gap virtually disappears. Under strict controls, the discrepancy reduces from a previously estimated 2.18 delay difference to a negligible 1.11 difference 4. These findings indicate that delayed generalization is not a mystical property of attention mechanisms or specific structural inductive biases, but rather a universal artifact of the interaction between optimization stability and regularization. When evaluated at their respective optimal regularizations, diverse models navigate the phase transition similarly, underscoring that previously reported structural advantages were largely confounds of suboptimal hyperparameter tuning 4.
Softmax Collapse and Numerical Precision
Further skepticism focuses on the mechanical realities of floating-point arithmetic. In what is known as "softmax collapse," a network that achieves 100% training accuracy will continually scale its output logits to drive the cross-entropy loss infinitesimally closer to zero. Because computational hardware relies on limited precision floating-point numbers, if the logits grow excessively large, the corresponding gradients shrink to absolute floating-point zero 2753.
This precision failure effectively halts meaningful representational updates. The network sits in a numerical dead zone, inflating parameters along a "naive loss minimization direction" without actually learning anything new 53. Only when random variance, batch dynamics, or adaptive momentum manages to jolt the network out of this logit-scaling trap does the model resume updating its core representations. From the outside, this presents the illusion of a sudden cognitive breakthrough, when in reality, the model was simply stalled by numerical instability for thousands of epochs 53.
Continuous Metrics Versus Discrete Thresholds
A broader epistemological debate questions whether sudden phase transitions in neural networks - including both grokking and the widely reported "emergent abilities" seen in scaled LLMs - are genuine structural shifts or simply statistical mirages generated by the researcher's choice of evaluation metrics 145455.
Critics point out that researchers frequently rely on discrete, non-linear metrics (such as exact-match accuracy, pass/fail coding tests, or multiple-choice accuracy) to evaluate model performance. In classification tasks, accuracy remains at exactly zero until the network's internal probability for the correct token crosses a specific majority threshold, at which point it instantly registers as a 100% success 5455. If the network's internal capability and confidence are actually growing linearly and smoothly over time, a discrete accuracy metric will inevitably cast that smooth growth as a sudden, discontinuous leap 5455.
When researchers re-evaluate the exact same models using continuous, fine-grained metrics - such as cross-entropy loss, log-loss, Brier scores, or edit distance - the abruptness of the phase transition often dissolves entirely into a smooth, predictable, and continuous improvement curve that was present from the beginning of training 5455. This suggests that what appears to be a sudden moment of "understanding" may simply be the continuous accumulation of statistical confidence finally breaching an arbitrary evaluation threshold.
Conclusion and Future Trajectories
Understanding the intricate interplay between memorization and generalization has shifted from a theoretical curiosity to a practical engineering imperative. If delayed generalization represents the reliable discovery of highly compressed, systematic reasoning circuits, modern AI training paradigms must find reliable methods to induce this state without incurring the massive computational waste associated with extended, post-overfitting optimization 1829.
Emerging algorithmic interventions aim to accelerate this phase transition directly. Methods such as NeuralGrok utilize bilevel optimization through auxiliary network modules to dynamically modulate gradient components during training. These methods actively penalize gradient directions that favor dense memorization and selectively amplify the gradient components that contribute to generalization, thereby forcing the network to bypass the plateau phase 29. Similarly, optimization techniques focusing on low-frequency gradient amplification seek to mitigate the slingshot effect entirely, shepherding networks directly into the parameter regimes associated with high test accuracy 414. As these techniques mature, the ability to explicitly monitor, predict, and control the shift from rote memorization to true algorithmic representation will be central to developing more reliable, interpretable, and computationally efficient artificial intelligence systems capable of deep logical reasoning.