Debate on Power Laws in Real-World Networks
Emergence of the Scale-Free Paradigm
For more than two decades, the study of complex systems has been profoundly shaped by the concept of scale-free networks. Originating in the late 1990s with the seminal work of Albert-László Barabási and Réka Albert, the scale-free paradigm posited that diverse real-world networks - spanning the World Wide Web, social interaction graphs, biological cellular structures, and power grids - share a universal topological architecture 12. Prior to this formulation, network science relied heavily on the Erdős-Rényi model of random graphs, wherein the presence of edges is determined by a uniform probability, resulting in a binomial or Poisson degree distribution 34. In such random networks, the degrees of almost all nodes cluster tightly around a well-defined mean, rendering extreme deviations exponentially rare 35.
The observation of empirical networks revealed a stark departure from the Poisson distribution. In these networks, the distribution of node connections does not possess a typical scale or average number of connections. Instead, the degree distribution follows a power law, a mathematical relationship characterized by a heavy tail. In this topology, a vast majority of nodes have very few connections, while a highly select minority of nodes, known as hubs, possess an extraordinarily large number of connections 678.
The initial appeal of the scale-free hypothesis was deeply rooted in complexity science. It provided an elegant, unifying principle of emergence, suggesting that independent of the underlying system's identity or the nature of its constituents, universal mechanisms drive the structural evolution of the network 129. A network characterized by a power-law degree distribution exhibits scale invariance, meaning that its relative abundance of node connections remains consistent regardless of the scale at which the network is observed 1910. This structural architecture has profound implications for network dynamics, predicting extreme robustness against random failures but acute vulnerability to targeted attacks on central hubs 111213. Furthermore, theoretical analyses suggested that infinite scale-free networks lack an epidemic threshold, implying that pathogens or information can spread comprehensively regardless of transmission rates 19.
However, the assertion that scale-free networks are a ubiquitous, universal property of nature has recently faced severe empirical and statistical scrutiny. Advanced statistical analyses of extensive network datasets, particularly those utilizing the Index of Complex Networks (ICON), suggest that strict power-law distributions are exceptionally rare in empirical data 141516. Alternative heavy-tailed distributions, such as the log-normal distribution, frequently provide a superior statistical fit to real-world network topologies 1417. This discrepancy has ignited a robust debate within the scientific community regarding the definitional boundaries of scale-freeness, the validity of statistical testing methodologies applied to finite datasets, and the broader epistemological challenge of inferring generative mechanisms solely from observational network topologies 6111819.
Mathematical Foundations of Network Topologies
Statistical Mechanics of Degree Distributions
A network is fundamentally defined by a set of vertices (nodes) and the edges (links) that connect them. The degree $k$ of a node represents the total number of links it possesses. The macro-scale topology of a network is most commonly analyzed through its degree distribution, $P(k)$, which denotes the probability that a randomly selected node in the network possesses exactly $k$ links 51013.
In classic random network models, the probability of connection between any two nodes is an independent constant $p$. The resulting degree distribution is binomial, which for large networks approximates a Poisson distribution:
$$P(k) = \frac{e^{-\langle k \rangle} \langle k \rangle^k}{k!}$$
where $\langle k \rangle$ is the average degree 34. This distribution features an exponential decay in its tail, meaning that the probability of finding a node with a degree significantly higher than the mean drops off exceptionally quickly 2021.
Conversely, a network is classified as scale-free if its degree distribution asymptotically follows a power-law form. Mathematically, the probability $P(k)$ decays as a power of $k$:
$$P(k) \sim k^{-\gamma}$$
where $\gamma$ is the scaling parameter or degree exponent 822. For empirical complex networks, the exponent is typically observed to fall within the range of $2 < \gamma < 3$ 2822.
The mathematical properties of this distribution dictate the unique characteristics of scale-free networks. When the scaling parameter is bounded between 2 and 3, the first moment (the mean degree) is finite, but the second moment (the variance) mathematically diverges to infinity as the network size approaches infinity 4823. Because the variance is undefined, the network lacks a characteristic scale, rendering the mean degree fundamentally uninformative as a representative metric 223. Fluctuations around the mean can be arbitrarily large, enabling the existence of massive hubs that connect to a significant fraction of the network 1723.
To properly normalize a discrete power-law distribution over a bounded domain $k \ge k_{min}$, a normalization constant is required. This constant is derived using the Hurwitz zeta function, $C = 1/\zeta(\gamma, k_{min})$, ensuring the area under the probability density curve equals one 24. For ideal continuous formulations, the power law is not normalizable over the full domain from zero to infinity; it strictly requires an "ultraviolet" (UV) cutoff at small values of $k$ to remain mathematically coherent 11.
Comparison of Statistical Degree Distributions
The following table summarizes the mathematical forms and topological implications of the primary distributions debated in network science:
| Distribution Type | Mathematical Form | Tail Behavior | Topological Implications |
|---|---|---|---|
| Poisson (Random) | $P(k) = e^{-\langle k \rangle} \langle k \rangle^k / k!$ | Exponential decay | Nodes cluster tightly around the mean; hubs are virtually non-existent. Lacks heavy tails. |
| Power Law (Scale-Free) | $P(k) \propto k^{-\gamma}$ | Polynomial decay | Scale-invariant; extreme hubs exist. Variance diverges when $2 < \gamma < 3$. |
| Power Law with Cutoff | $P(k) \propto k^{-\gamma} e^{-\lambda k}$ | Polynomial bounded by exponential | Generates hubs but respects finite capacity constraints of the system (e.g., physical limits). |
| Log-Normal | $P(k) \propto \frac{1}{k \sigma} \exp(-\frac{(\ln k - \mu)^2}{2\sigma^2})$ | Heavy-tailed but finite | Mimics power laws over finite ranges due to small log-squared terms; arises from multiplicative proportional growth. |
Generative Mechanisms for Heavy-Tailed Architectures
The observation of power-law patterns in real-world systems inherently demands a theoretical explanation for their physical or social generation. While static graph theory focuses on the final state of a network, dynamic network theory seeks to identify the time-dependent mechanisms that reliably produce specific topological outcomes 21. Over the past two decades, several distinct generative models have been proposed to explain the widespread appearance of heavy-tailed and scale-free architectures.
Growth and Preferential Attachment
To explain the emergence of power laws, Barabási and Albert introduced a model based on two fundamental dynamics: network growth and preferential attachment 128.
Classical random graphs assume a static number of nodes. Real networks, however, are open systems that expand sequentially over time 2125. When a new node enters the Barabási-Albert (BA) network, it connects to existing nodes. Rather than selecting these targets uniformly at random, the new node connects to existing nodes with a probability $\Pi_i$ that is linearly proportional to the existing node's current degree $k_i$ 826.
$$\Pi_i = \frac{k_i}{\sum_j k_j}$$
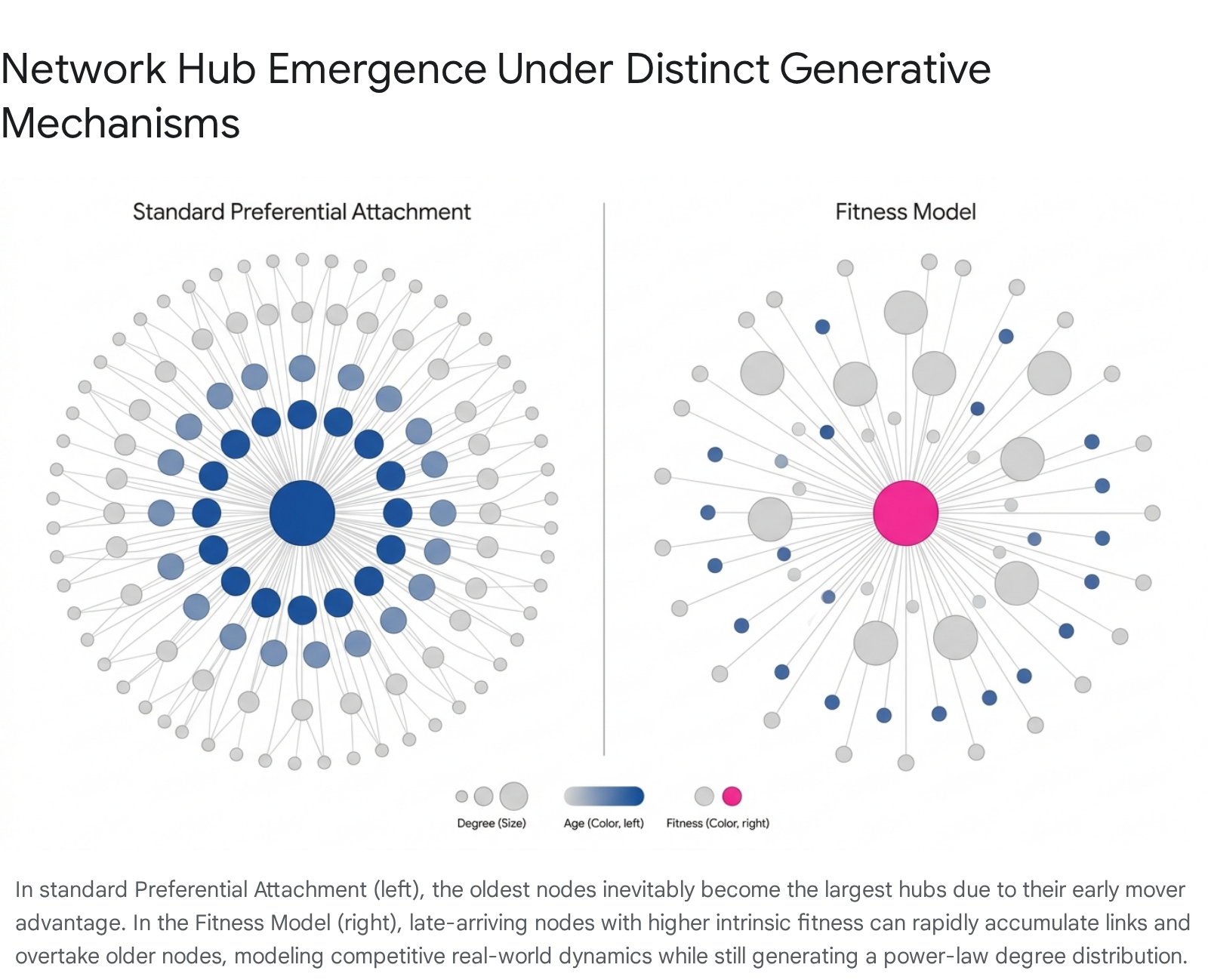
This mechanism formalizes the "rich-get-richer" phenomenon observed in economics and sociology. Nodes that acquire more links increase their mathematical probability of acquiring even more links in subsequent timesteps 122127. Because older nodes have enjoyed a longer duration to accumulate links, preferential attachment naturally produces a strong correlation between a node's chronological age and its degree 28. In the continuum limit, the rate of change of a node's degree follows a predictable trajectory, resulting in a stationary power-law degree distribution with a fixed scaling exponent of $\gamma = 3$ 2128.
The Bianconi-Barabási Fitness Model and Condensation
While elegant, pure preferential attachment struggles to explain empirical anomalies, specifically the phenomenon of "latecomer" hubs. Under the standard BA model, the oldest nodes inevitably achieve hub status due to an insurmountable first-mover advantage 2528. In reality, younger nodes frequently overtake older nodes - for instance, the rapid ascent of Google over older search engines, or the viral dominance of new social platforms over established incumbents 252829.
To resolve this limitation, Ginestra Bianconi and Albert-László Barabási developed the Fitness Model in 2001 252930. In this theoretical extension, every node $i$ is assigned an intrinsic, time-independent "fitness" parameter $\eta_i$, drawn from an arbitrary probability distribution $\rho(\eta)$. Fitness acts as a proxy for the node's inherent quality or intrinsic capacity to attract links, functioning independently of its entry time or current connectivity 252629.
The attachment probability is mathematically modified to be proportional to the product of the node's degree and its fitness:
$$\Pi_i = \frac{\eta_i k_i}{\sum_j \eta_j k_j}$$
In this regime, a node with a high fitness parameter possesses a larger dynamic exponent $\beta(\eta)$, enabling it to accumulate links at an accelerated rate and effectively outcompete older, less-fit nodes 2831. The degree distribution of the network remains scale-free, but its precise scaling exponent $\gamma$ becomes variable, strictly dependent on the underlying fitness distribution $\rho(\eta)$ 2531.
A remarkable consequence of the Bianconi-Barabási model is its mathematical isomorphism to the statistical physics of a Bose gas. By mapping a node's fitness to discrete energy levels, the model predicts a topological phase transition 2532. In the standard "fit-get-richer" phase, multiple highly fit nodes compete for connectivity, yielding a conventional power-law tail. However, if the network crosses a critical threshold - dictated by the shape of the fitness distribution - it enters a "winner-takes-all" phase. This transition directly corresponds to Bose-Einstein condensation, wherein a single, supremely fit node monopolizes a macroscopic fraction of all available links in the entire system, fundamentally altering the network topology 252932.
Vertex Copying and Duplication-Mutation Models
In domains such as molecular biology (specifically protein interaction and gene regulation networks) and information retrieval (the World Wide Web), heavy-tailed distributions are frequently explained by "vertex copying" or "duplication-mutation" frameworks, initially formalized by Jon Kleinberg, Ravi Kumar, and colleagues 3334.
Vertex copying models recognize that new nodes often lack the global visibility required to calculate preferential attachment probabilities across an entire network 33. Instead, a new node entering the network randomly selects one existing "prototype" vertex and effectively copies a fraction of its outgoing links 3334.
Mathematically, this process functions via a stochastic coin flip: with a probability $p$, the new node creates a link uniformly at random to an existing node, and with probability $1-p$, it copies an edge directly from a randomly chosen prototype node 33. Because high-degree nodes serve as the endpoints for many connections, they are statistically far more likely to be the target of a copied edge. If an existing vertex $i$ has degree $k_i$, the probability that a randomly chosen vertex is connected to $i$ scales proportionately with $k_i$. Thus, the local act of copying implicitly reproduces the global rich-get-richer dynamics without requiring omniscience of the network state 33.
This mechanism is particularly powerful for modeling biological networks, where gene duplication events create biological nodes with identical connection profiles, followed by random mutations that alter specific links. The copying model generates a distinct power-law degree distribution $P(k) \sim k^{-c}$, where the exponent depends solely on the fidelity of the copying process, determined by the formula $c = 1 + \frac{1}{1-p}$ 3335.
Statistical Methodologies for Distribution Fitting
While generative models easily produce perfect power laws in theoretical limits, confirming the existence of power laws in finite, empirical datasets introduces substantial statistical complexities 1122. For years, the standard practice in network science for identifying scale-free networks relied heavily on rudimentary graphical techniques. Researchers would plot the observed degree distribution on doubly logarithmic (log-log) axes and fit a straight line using ordinary least squares (OLS) regression 722.
Fallacies of Logarithmic Linear Regression
The reliance on log-log OLS regression is predicated on the algebraic property that if a relationship follows a power law, $P(k) = ck^{-\gamma}$, taking the logarithm of both sides linearizes the equation:
$$\log P(k) = -\gamma \log k + \log c$$
This linear equation exhibits a slope of $-\gamma$ 36. Consequently, an empirically observed straight line on a log-log plot was widely accepted as sufficient evidence of scale-free behavior.
However, modern statistical literature fundamentally rejects this heuristic. Observing a straight line on a log-log plot is a necessary, but vastly insufficient, condition for validating a power-law relationship 736. Numerous heavy-tailed distributions that lack scale-free properties can convincingly masquerade as straight lines over several orders of magnitude on logarithmic scales 737.
Furthermore, applying OLS regression directly to log-transformed probability distributions is statistically invalid. OLS assumes that the errors are normally distributed and possess constant variance. In network degree distributions, the extreme upper tail (representing the rarest, largest hubs) is subject to massive statistical fluctuations 22. These massive fluctuations in sparse data bins heavily skew the coefficient estimates, yielding substantially inaccurate parameters and generating false confidence in the power-law fit 22.
Maximum Likelihood Estimation and the KS Statistic
To resolve these severe methodological flaws, Aaron Clauset, Cosma Shalizi, and Mark Newman (2009) established a rigorous, mathematically sound statistical framework for discerning and quantifying power-law behavior in empirical data 122. Their framework replaces linear regression with Maximum Likelihood Estimation (MLE) to derive the scaling parameter.
Assuming the empirical data is drawn from a power law strictly for values greater than or equal to a minimum bound $x_{min}$, the MLE for the continuous scaling parameter $\hat{\gamma}$ is analytically defined as:
$$\hat{\gamma} = 1 + n \left( \sum_{i=1}^n \ln \frac{x_i}{x_{min}} \right)^{-1}$$
where $x_i$ represents the observed degree values greater than $x_{min}$, and $n$ is the total count of such observations 2238.
Crucially, estimating the exponent does not prove the model fits the data. The Clauset-Shalizi-Newman framework mandates a subsequent goodness-of-fit test based on the Kolmogorov-Smirnov (KS) statistic 2238. The KS statistic measures the maximum absolute distance between the empirical cumulative distribution function (CDF) of the observed data and the theoretical CDF of the fitted power-law model 2238. A $p$-value is then derived via a bootstrapping procedure: generating synthetic datasets from the fitted power-law model and comparing their KS statistics to the empirical measurement. If the resulting $p$-value is sufficiently high (conventionally $p \ge 0.1$), the power-law hypothesis cannot be rejected, indicating that a power law remains a mathematically plausible generative model for the network's tail 182240.
Likelihood Ratio Tests and the Log-Normal Confusion
Establishing mathematical plausibility is not equivalent to establishing supremacy. Even if a power law yields a passing KS test, an alternative distribution may explain the data better. The final procedural step involves Likelihood Ratio Tests (LRT) to directly compare the power-law model against alternative heavy-tailed distributions, including the log-normal, exponential, and stretched exponential (Weibull) distributions 1422.
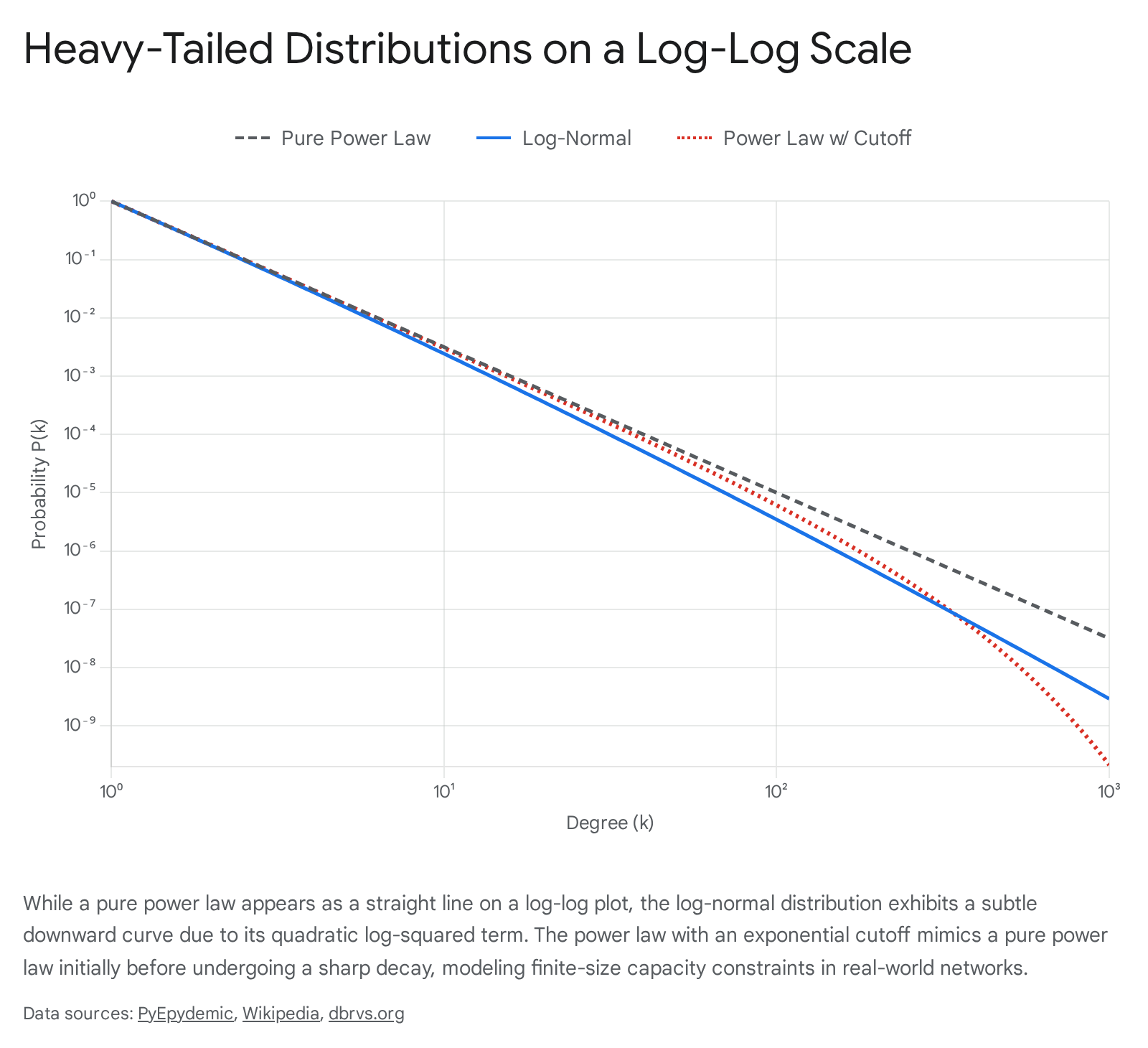
The log-normal distribution is of particular importance in the scale-free debate. A random variable follows a log-normal distribution if its logarithm is normally distributed. While standard normal distributions emerge from the additive aggregation of many independent random variables (per the Central Limit Theorem), the log-normal distribution emerges from the multiplication of independent, positive random variables 37. Networks driven by multiplicative proportional growth processes - often referred to as Gibrat's law - naturally yield log-normal degree topologies 737.
When analyzing the mathematical formulation of the log-normal probability density function in logarithmic space, the resulting equation contains a constant term, a linear logarithmic term, and a quadratic log-squared term ($\log^2 x$) 737. If the variance of the underlying multiplicative process is exceedingly large, the coefficient multiplying the log-squared term becomes incredibly small. For the vast majority of the network's degree distribution, this quadratic curve will appear visually linear on a log-log plot 737. It is only in the extreme upper bounds - examining the absolute largest hubs - that the log-squared term finally dominates, causing the line to visually bow downward and revealing the distribution's non-power-law nature 737. Consequently, without rigorous likelihood ratio testing, log-normal networks are routinely misclassified as scale-free networks 740.
The Broido-Clauset Analysis of the ICON Corpus
Utilizing the rigorous statistical framework developed by Clauset et al., a pivotal 2019 study by Anna Broido and Aaron Clauset executed a severe empirical test of the universality of the scale-free hypothesis 141516. The study aimed to resolve whether scale-free topologies are truly ubiquitous across all complex systems or if they are relatively isolated phenomena 141516.
Composition of the Index of Complex Networks
A foundational vulnerability of early network science literature was selection bias. Researchers frequently analyzed a narrow subset of easily accessible datasets - such as early crawls of the World Wide Web, specific router topographies, or singular scientific citation networks - and extrapolated those findings into universal laws 141639.
To overcome this, Broido and Clauset utilized the Index of Complex Networks (ICON), a comprehensive database indexing research-quality complex network datasets from virtually all scientific disciplines 144041. The resulting analytical corpus comprised 928 diverse network datasets 14. The composition reflected broad multidisciplinary representation: roughly 50% were biological networks (e.g., metabolic pathways, connectomes), 33% were social and technological networks, and 17% were informational and transportation networks 14.
The selected networks varied across five orders of magnitude in size, ranging from a few hundred nodes to millions of interacting entities, and featured a mean degree that fluctuated broadly across the corpus 14. Because the mathematical definition of a degree distribution applies precisely to simple graphs, complex datasets featuring multigraphs, bipartite structures, or temporal weights were projected into simple graph formats through systematic data transformations prior to analysis 1416.
Taxonomy of Scale-Free Evidence
Recognizing that the term "scale-free" had been deployed with highly varying degrees of statistical rigor across the literature, Broido and Clauset constructed a unified taxonomy to grade the strength of scale-free evidence 141519. They categorized empirical networks into five nested tiers of evidence, evaluated through the KS goodness-of-fit and Likelihood Ratio Tests:
| Evidence Category | Statistical Requirements | Empirical Frequency |
|---|---|---|
| Super-Weak | For $\ge 50\%$ of the simple graphs derived from the network, no alternative heavy-tailed distribution is statistically favored over the power law. | ~52% |
| Weakest | For $\ge 50\%$ of graphs, the power-law hypothesis cannot be rejected by the KS test ($p \ge 0.1$). | ~29% |
| Weak | Meets "Weakest" requirements, plus the scaling region tail contains at least 50 nodes. | ~11% |
| Strong | Meets "Weak" requirements, the scaling parameter falls within $2 < \hat{\gamma} < 3$, and no alternative distribution is favored. | < 6% |
| Strongest | Meets "Strong" requirements for $\ge 90\%$ of graphs, and "Super-Weak" requirements for $\ge 95\%$ of graphs. | < 4% |
Data aggregated from the Broido and Clauset (2019) structural analysis corpus 1418.
Empirical Findings on Power Law Rarity
The analytical results generated a paradigm shift within the field. Broido and Clauset demonstrated that, contrary to the dominant narrative of the preceding two decades, genuinely scale-free networks are remarkably rare 14151644. Fewer than 4% of the networks within the diverse corpus met the "Strongest" criteria for scale-free structure 14154442. Even under the highly permissive "Weakest" criteria - where a power law is simply a mathematically plausible model for the upper tail of the degree distribution without outperforming any alternatives - only 29% of the networks qualified 14.
Crucially, the likelihood ratio tests revealed that alternative non-scale-free distributions routinely provided a superior fit to the empirical data. The log-normal distribution fit the node degree data as well as or better than the power law in the vast majority of cases across the corpus 141517. Even the exponential distribution, characterized by a relatively thin tail, was favored over the power law in 41% of instances, compared to the power law being favored just 33% of the time 1417.
Furthermore, the strength of the evidence was highly heterogeneous across different scientific domains 16. Social networks, frequently popularized as standard examples of scale-free behavior due to the presence of highly connected influencers, were found to be at best only weakly scale-free. The absolute strongest evidence for scale-free structures was highly isolated, found predominantly in a small handful of specific technological systems and biological pathways 141516. These findings highlight profound structural diversity in complex systems, implying that a singular universal mechanism like preferential attachment is insufficient to capture the full topological realities of the interconnected world 14151642.
Theoretical Rebuttals and Definitional Ambiguities
The assertion that scale-free networks are empirically rare triggered immediate and intense theoretical rebuttals from the physicists and mathematicians who pioneered the original models 1918. The controversy largely centers not on the mathematical execution of the MLE and KS statistics, but on the epistemological definition of "scale-freeness" and the limits of analyzing finite physical systems 1917.
Finite-Size Constraints and Exponential Cutoffs
Albert-László Barabási issued a comprehensive response, arguing that Broido and Clauset's rigorous search for a "pure" power law represents a misapplication of network theory to empirical reality 18. Barabási contended that "by 2001 it was pretty clear that there is no one-size-fits all formula for the degree distribution for scale-free networks. A pure power law only emerges in simple idealized models, driven only by growth and preferential attachment, and free of any additional effects" 18.
In real-world networks, physical, geographic, and cognitive constraints inherently impose finite limits on the capacity of nodes to accumulate links 142446. A human being possesses a finite neurological and temporal capacity for maintaining social relationships, limiting social network hubs. An internet router possesses a hard physical limit on its maximum number of fiber-optic port connections. These real-world capacity constraints introduce an exponential cutoff in the extreme upper tail of the degree distribution, truncating the infinite variance predicted by theoretical power laws 142438.
A power law with an exponential cutoff is modeled by multiplying the underlying power-law function by an exponential decay factor:
$$P(k) \propto k^{-\gamma} e^{-\lambda k}$$
where the parameter $\lambda$ dictates the specific transition point where the exponential cutoff begins to dominate and override the underlying power-law behavior 71438. The constant of proportionality required to normalize this distribution utilizes a polylogarithm, taking the form $C = Li_\gamma(e^{-1/\kappa})$ 2438.
Barabási highlighted that Broido and Clauset's own supplementary analytical tables demonstrated that 51% of the networks they explored actually favored the distribution of a power law with an exponential cutoff 18. From the perspective of classical network physics, this finding does not refute the scale-free hypothesis; it validates it. It provides statistical proof that scale-free preferential attachment mechanisms are actively driving the network's growth, but their idealized topological output is simply bounded by secondary, finite-size physical constraints 18.
Asymptotic Limits versus Empirical Realities
The debate highlights a profound methodological divide regarding the origins of network theory in statistical physics. In theoretical physics, concepts such as emergent phase transitions, critical universality classes, and scale invariance are strictly and mathematically well-defined only in the thermodynamic limit - meaning an infinite system size where the number of particles (or nodes) approaches infinity ($N \to \infty$) 1911.
Because empirical datasets are intrinsically finite, an empirical network can only ever be approximately scale-free 11. The ideal continuous power-law degree distribution cannot be normalized over the full mathematical domain; it regains true, unadulterated scale invariance only asymptotically in the "infrared" limit as $k \to \infty$ 11. Critics of the Broido-Clauset methodology argue that enforcing strict statistical adherence to an asymptotic theoretical property on finite, noisy, empirical datasets is an inappropriate and overly restrictive application of complexity theory 1917.
According to this theoretical perspective, a network should be classified as scale-free if its underlying generative mechanism would cause the degree distribution to approach a power law as the network grows infinitely 19. Consequently, minor data fluctuations that cause a finite network to fail a rigorous Kolmogorov-Smirnov statistical test do not invalidate the presence of scale-free generative dynamics 19.
Equifinality and Network Inference
The controversy is further complicated by the scientific principle of "equifinality" - the concept that identical mathematical distributions can be produced by entirely divergent underlying generative processes 27. Even when a rigorous statistical test definitively confirms a pure power-law degree distribution, it does not act as definitive proof that the network was generated by growth and preferential attachment 1427.
The shape of a degree distribution imposes only modest constraints on overall macro-network topology. Therefore, the presence of a power law serves as relatively weak evidence for distinguishing between specific generative mechanisms 142743. Researchers have demonstrated that power laws can arise from optimization processes, random walks, or merging networks, completely devoid of preferential attachment mechanisms 284445. Because of equifinality, network scientists emphasize that inferring the cause (preferential attachment) strictly from the outcome (a heavy-tailed distribution) is analytically problematic 2743.
Domain-Specific Manifestations of Network Architectures
As the controversy over universality has matured, a broader scientific consensus has emerged that sweeping generalizations - whether claiming that all networks are scale-free or that scale-free networks are entirely mythical - fail to capture domain-specific topological realities 141617.
Biological networks, encompassing protein-protein interactions, metabolic pathways, and gene regulatory networks, frequently exhibit highly robust scale-free architectures that survive rigorous statistical testing 141633. These structures are likely driven by evolutionary duplication-mutation events (accurately modeled by vertex copying mechanisms), wherein the scale-free topology provides vital biological resilience against random genetic mutations and environmental failures 141633. Technological systems engineered for optimal, decentralized routing, such as specific infrastructural layers of the internet, also demonstrate definitive power-law behavior 1416.
Conversely, social networks are increasingly viewed as heavy-tailed but fundamentally non-scale-free 1416. Human social interactions are bounded by finite temporal constraints, cognitive load limits, and physical geography, invariably inducing exponential cutoffs and log-normal degree distributions rather than infinite-variance power laws 14243746.
Re-evaluating Citation Networks with Outlier Analysis
Even within specific academic domains, the analytical methodologies utilized can drastically alter conclusions regarding scale-freeness. Scientific citation networks - where new research papers cite previously published papers - have historically been modeled using preferential attachment, heavily relying on the "first-mover advantage" phenomenon 2846. Following the widespread skepticism generated by the Broido-Clauset study, the scale-free nature of citation networks was deeply questioned, as many failed standard MLE and KS tests 46.
However, recent empirical methodologies have re-examined citation networks using highly nuanced outlier-handling frameworks. A 2024 study by Zhong and Liang analyzed citation distributions by employing a merged rank distribution, which segmenting empirical data into three distinct mathematical portions: extreme upper outliers, the primary power-law segment, and the non-power-law body 46. By employing a Random Sample Consensus (RANSAC)-based algorithm - a technique highly effective at interpreting data containing gross errors and noise - they successfully isolated the underlying power-law segments from the raw data 46.
When these isolated segments were subjected to Kolmogorov-Smirnov testing, they definitively exhibited scale-free properties 46. This suggests that previous skepticism regarding the scale-freeness of citation networks was largely attributable to the confounding presence of extreme, anomalous outliers or artificial sampling noise, rather than a failure of the underlying preferential attachment mechanism. The study confirms that scientific visibility acts as a true scale-free process, albeit one deeply embedded in noisy real-world data constraints 46.
Conclusions
The controversy over scale-free networks stands as a definitive example of the analytical friction that occurs when pristine theoretical physics collides with the messy, finite reality of empirical data. The sweeping claim that "scale-free networks are universal" is undeniably overblown. As demonstrated by the exhaustive analysis of the Index of Complex Networks, true, unadulterated power-law degree distributions are mathematically rare. Log-normal distributions and capacity-constrained exponential cutoffs frequently provide superior statistical explanations for empirical network structures 141822.
However, the counter-claim that "scale-free networks do not exist" is equally reductive. The mathematical framework of the power law remains the most powerful baseline null model for understanding the heavy-tailed, hub-centric architecture that dominates modern interconnected systems 1718. The generative mechanisms proposed by scale-free theory - whether preferential attachment, vertex copying, or fitness-driven accumulation - accurately capture the fundamental "rich-get-richer" dynamics that verifiably organize the World Wide Web, genetic regulatory pathways, and scientific citation networks 1253346. Ultimately, the scale-free network is not an infallible, universal empirical law, but rather a theoretical asymptote - an idealized topological state that real-world networks approach, constrained only by the physical, temporal, and biological limits of their respective domains.