Catastrophic forgetting in neural networks
Theoretical Foundations and the Stability-Plasticity Dilemma
The development of artificial neural networks has been fundamentally constrained by the stability-plasticity dilemma, a theoretical construct that dictates the behavior of learning systems in dynamic and non-stationary environments 123. The dilemma describes the inherent computational tension between two opposing operational requirements: "plasticity," which is the network's capacity to integrate new information and adapt to novel tasks rapidly, and "stability," which is the system's ability to retain and consolidate previously acquired knowledge over long periods without degradation 23.
In a perfectly balanced biological or artificial system, incoming data streams inform and update internal representations without destroying the foundation of past learning. However, modern deep learning architectures predominantly suffer from an extreme imbalance on this spectrum. Lookup tables and connectionist networks lie on opposite extremes: lookup tables represent perfect stability but zero generalization plasticity, while deep neural networks possess massive plasticity but extreme sensitivity to novel information 1. When exposed to new sequential information, neural networks frequently exhibit an excess of plasticity and a critical deficit in stability. This radical manifestation of the dilemma results in the rapid, involuntary overwriting of historical data, a phenomenon formally known as catastrophic interference or catastrophic forgetting 1345. Resolving this dilemma remains the primary hurdle to achieving lifelong, continual learning in artificial intelligence, preventing models from accumulating knowledge in a stable, persistent manner 679.
The issue of catastrophic interference when modeling memory with connectionist models was originally brought to the attention of the cognitive science and scientific communities by the seminal research of McCloskey and Cohen in 1989, followed closely by Ratcliff in 1990 and French in 1999 14811. Investigating the viability of connectionist models to simulate human memory, McCloskey and Cohen constructed a standard three-layer feedforward backpropagation network consisting of 28 input units, 50 hidden units, and 24 output units 4.
The experimental design required the network to learn basic arithmetic sequentially. In the first phase, the network was trained extensively on a single training set of 17 "ones addition facts" (e.g., $1+1$ through $9+1$, and $1+2$ through $1+9$) until it achieved a flawless representation of the target outputs, steadily minimizing the error between actual and desired responses 19. Once the network mastered this domain, the researchers initiated the second phase: training the same network exclusively on "twos addition facts" (e.g., $1+2$ through $9+2$, and $2+1$ through $2+9$) 9.
The results demonstrated a severe limitation in the backpropagation paradigm. Learning the second task rapidly and completely deteriorated the acquired knowledge of the first task. The interference was not gradual or mild; it was abrupt and catastrophic, with the network effectively erasing its ability to calculate the "ones addition facts" 149. McCloskey and Cohen concluded that catastrophic interference is an inevitable outcome whenever new learning fundamentally alters the shared weights involved in representing old learning. They noted that the severity of the disruption scaled directly with the volume of new learning and was particularly destructive during sequential, non-concurrent training regimes 14. Because human biological memory is highly resistant to this type of abrupt overwriting - humans typically exhibit only moderate interference in episodic memory tasks - the phenomenon highlighted a fundamental divergence between standard connectionist models and biological cognition 14.
To analyze catastrophic forgetting effectively within the broader context of machine learning failures, it must be distinguished from other forms of model degradation. While the symptoms often manifest similarly as a drop in predictive accuracy, the underlying mathematical causes and generalization impacts are strictly distinct.
| Phenomenon | Primary Cause | Network Behavior and Symptoms | Generalization Impact |
|---|---|---|---|
| Catastrophic Forgetting | Sequential gradient updates overwrite shared parameters critical for past tasks 410. | Generalizes well on the newly learned task or domain but suffers a near-total collapse in accuracy on older, previously mastered domains 11. | Cross-domain generalization fails sequentially; historical capabilities are lost 11. |
| Overfitting | Network capacity is too high relative to the training data, capturing noise instead of signal; lack of regularization 1112. | Memorizes the specific training dataset perfectly but fails to generalize even within the immediate target domain on unseen data 11. | Intra-domain generalization fails immediately 11. |
| Concept Drift | The statistical properties of the target variable change over time in a non-stationary real-world environment 13. | The model's baseline knowledge becomes obsolete because the external reality has changed, not because internal weights collapsed 13. | Gradual decay in real-world accuracy across all previously trained paradigms 13. |
| Capacity Saturation | Inadequate parameter count to mathematically represent the complexity of a combined multi-task dataset 12. | Simultaneous training on multiple tasks results in high loss across all tasks because the model simply cannot hold the requisite information 12. | Uniform underperformance and high error rates across all tasks concurrently 12. |
Mathematical Mechanisms of Knowledge Erasure
The deterioration of prior knowledge during sequential training is not a programmable bug but the direct, mathematical consequence of gradient-based optimization operating on distributed representations 1014. Analyzing the architecture of neural networks reveals several distinct, interacting mechanisms that drive this destruction across different layers and training phases.
Overlapping Distributed Representations
In classical localist or propositional models, specific pieces of knowledge are stored in isolated, independent nodes 4. In contrast, modern neural networks utilize distributed representations, meaning that a single concept is encoded as a complex pattern of activation across a large, shared array of hidden units and connection weights 1410.
Because features and concepts overlap, individual weights become multi-functional, participating in the decision boundaries of numerous disparate tasks 91015. When a network is subjected to a new dataset, gradient descent calculates the optimal weight updates to minimize the loss function strictly for the new data. If the tasks utilize overlapping latent directions or share decision boundaries, the optimization process forcibly repurposes the same neurons 1015. The gradients will push the weights in directions that maximize current performance, indiscriminately overwriting the delicate mathematical configurations that supported the prior representations 101415. This representational overwrite implies that tasks fundamentally compete for finite network capacity.
Gradient Interference and Weight Manifold Drift
During sequential fine-tuning, catastrophic forgetting manifests mechanically as weight drift within the network's parameter space. Pre-trained networks converge on an optimal manifold - a low-dimensional hyperplane within the high-dimensional parameter space where historical knowledge is effectively encoded and structured 101516. The intrinsic dimension of this manifold is often much smaller than the nominal parameter count 1617. Even minor gradient steps applied during a new training phase can push the model off this pretraining-optimal manifold, warping the internal geometry that encoded older abilities 10.
The severity of this drift is heavily influenced by gradient collisions or gradient interference 1819. This occurs when the gradient vectors required to minimize loss on the new task point in directions that actively conflict with the parameter states necessary for the old task. In complex rendering tasks, such as 3D Gaussian Splatting (3DGS) or Neural Radiance Fields (NeRF), gradient collisions occur when "evil twins" - different augmentations applied to the same image, or severe geometric distortions from panoramic Equirectangular Projections (ERP) - yield conflicting gradients that destructively interfere in weight space 192021.
In transformer-based architectures, empirical analyses indicate that when gradient cosine similarity between tasks falls into negative values (e.g., below -0.3), the rate of forgetting accelerates dramatically, acting as an early predictive signature of catastrophic interference 1822.
As the data illustrates, the attention mechanism in transformers is highly susceptible to this interference. Up to 67% of parameters in attention query and key projection matrices experience conflicts during sequential updates, compared to roughly 29% in feedforward weights 22.
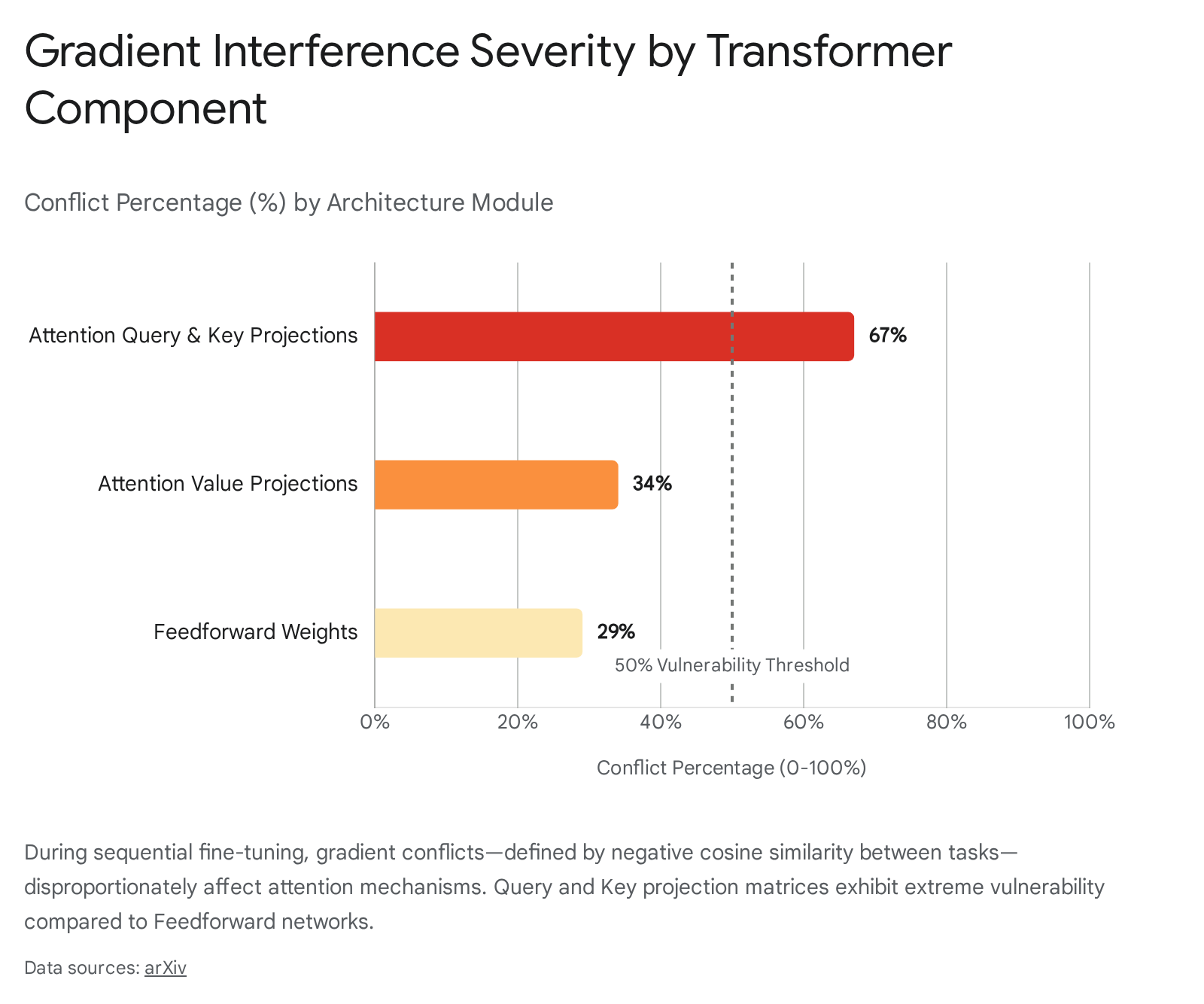
Consequently, between 15% and 23% of attention heads, predominantly in the lower layers of the network, undergo severe disruption during early fine-tuning epochs, directly correlating with subsequent forgetting 1822.
Loss Landscape Flattening and Subspace Distortion
Recent mechanistic analyses of large language models, scaling from 109 billion to 1.5 trillion parameters, have identified loss landscape flattening as a critical, long-term driver of irreversible forgetting 182226.
When a network learns an initial task, it locates a distinct minimum in the loss landscape characterized by specific curvature and sharp geometric boundaries 22. However, sequential fine-tuning on subsequent tasks drastically alters this local geometry. Measurements of the Hessian matrix - which describes the local curvature of the loss function - reveal profound structural degradation. For instance, the maximum Hessian eigenvalue associated with a first task may drop from a sharply defined 147.3 at initial convergence to a mere 34.2 after the model is trained on three subsequent tasks 22.
Simultaneously, the loss landscape for earlier tasks becomes increasingly linear, with linearity indices rising significantly (e.g., from 0.28 to 0.71) 22. This geometric flattening is catastrophic because it obliterates the mathematical "restoring forces" within the parameter space.
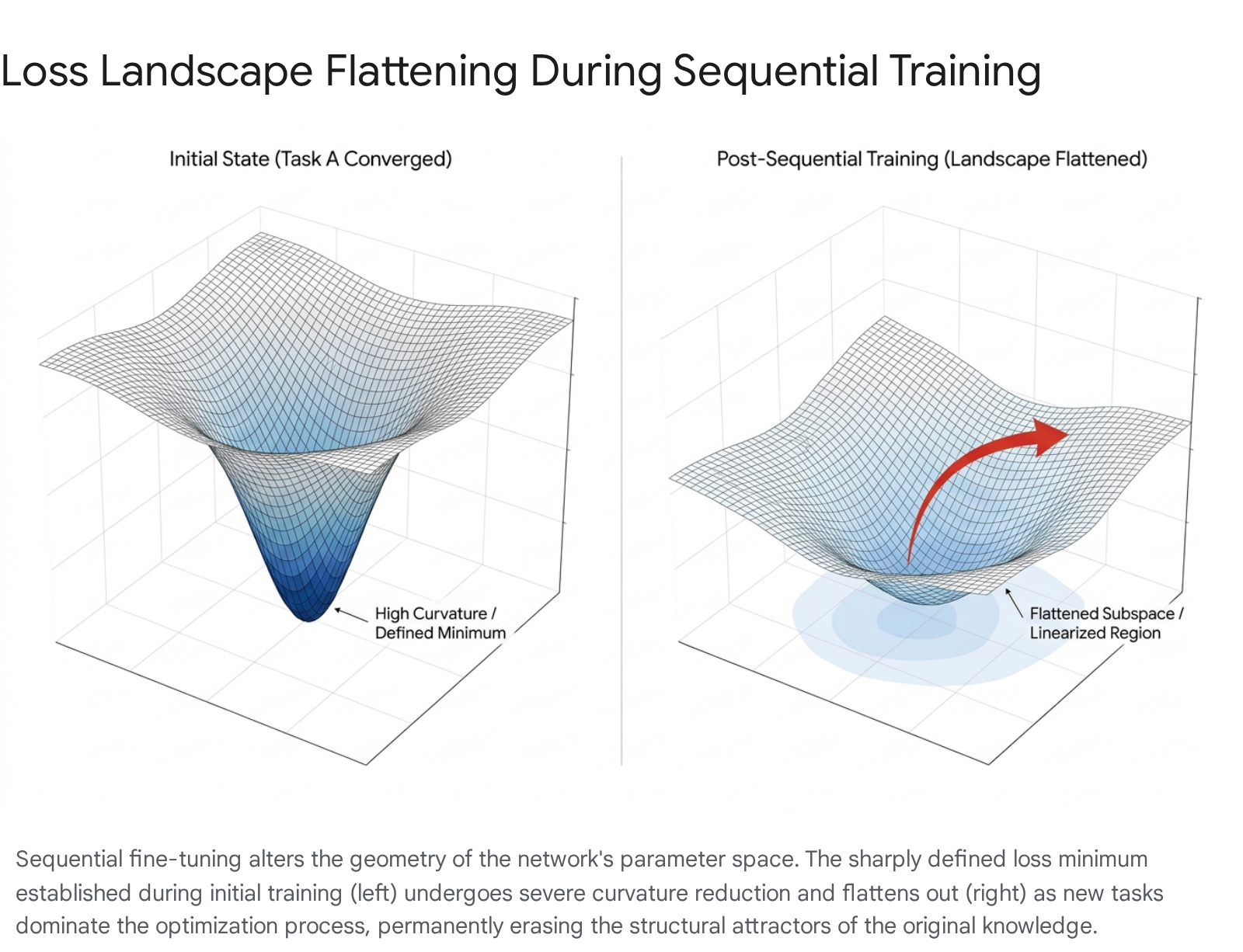
Without a well-defined minimum, the network loses the structural attractors that encoded the prior knowledge. The old abilities become effectively unrecoverable without full retraining, as the network lacks the gradient signals necessary to return to the previously optimal state 1022.
Inter-layer Relation Drift
Beyond individual weight shifts and loss curvature, catastrophic forgetting manifests as inter-layer relation drift 23. A neural network operates sequentially, passing feature representations from one layer to the next. The relationships among these layer-wise representations are finely tuned during initial training. When new tasks are introduced, the continued optimization induces representational drift, rotating dominant representational subspaces and degrading previously learned feature encodings 22.
Centered kernel alignment (CKA) metrics, which measure the similarity of representations before and after fine-tuning, show significant decreases (dropping by 0.32 to 0.47) in intermediate layers during sequential updates 22. Furthermore, the principal components of these representations - accounting for 60% to 75% of the variance - can rotate by an average of 35 to 52 degrees 22. As this drift increases, the classification margins of previously learned tasks shrink rapidly, causing the model to confuse classes from old and new tasks, thereby degrading the overall performance 623.
Forgetting Dynamics in Large Language Models
As the machine learning industry transitions toward massive foundation models and Large Language Models (LLMs), the mechanisms of catastrophic forgetting have scaled accordingly. Modern deployment architectures rarely rely on static, one-time training; models are expected to adapt continually to new domains, specialized instructions, tool use, and shifting factual landscapes over long lifecycles 15182224.
Continual Post-Training (CPT) versus Supervised Fine-Tuning (SFT)
Integrating new knowledge into an LLM generally involves distinct phases, primarily Continual Post-Training (CPT) and Supervised Fine-Tuning (SFT) 2930. CPT involves revisiting the training loop to expose the pre-trained model to large volumes of unstructured, domain-specific text (e.g., millions of medical documents or legal contracts) to deepen its expertise in a specific sector 293031. SFT, conversely, is an alignment phase utilizing curated, labeled instruction-response pairs to dictate behavioral formatting and instruction-following 30.
Both approaches induce catastrophic forgetting if unconstrained. Full fine-tuning - where all billions of weights across the model are updated simultaneously - yields the highest performance gains on the new target task but is highly susceptible to representational overwrite. As the model adapts deeply to the specific syntax and semantics of the new domain, its general knowledge structures collapse 112526. For instance, an LLM fully fine-tuned on specialized medical query datasets frequently loses its ability to answer basic, general-knowledge questions it could easily handle prior to adaptation, demonstrating a severe overwrite of original capabilities 11. Mitigating this requires careful curriculum strategies, such as determining optimal data mixture ratios (e.g., Additional Language Mixture Ratio) and employing cyclic precision training, where quantization precision varies during learning to improve convergence stability 29.
Parameter-Efficient Fine-Tuning (PEFT) and the Evolution of LoRA
To combat both the massive computational costs of updating 100% of parameters and the severe forgetting associated with full updates, researchers developed Parameter-Efficient Fine-Tuning (PEFT) techniques. Low-Rank Adaptation (LoRA) and its quantized counterpart (QLoRA) dominate this paradigm 252728.
The central hypothesis of LoRA is that the weight changes needed for task adaptation exhibit a low intrinsic rank 1729. Instead of altering the core network, LoRA freezes the vast majority of the pre-trained base model's weights and injects small, trainable low-rank matrices into the transformer layers (specifically targeting the attention and feedforward modules) 262829. The mathematical update is represented as $\Delta W = BA$, where $B$ and $A$ are the low-rank matrices 1728. Because the foundational weights remain untouched, the core capabilities of the model are theoretically preserved 2528.
However, PEFT mitigates, rather than solves, catastrophic forgetting. Studies demonstrate that while LoRA generally forgets less than full fine-tuning, significant capability degradation still occurs, particularly over long sequences of tasks or when scaling to higher learning rates 1729. The low-rank matrices act as localized distortions to the network's processing pipeline; if the new matrices force the activations down paths that conflict with older tasks, performance drops 10. Furthermore, LoRA's compressed structure can create a mismatch between optimizer running statistics (e.g., AdamW's first and second moments) and the updates a full fine-tuning step would normally compute 26.
This persistent vulnerability has led to the rapid development of advanced, specialized PEFT variants designed to explicitly curb interference.
| PEFT Methodology | Core Mechanism and Hypothesis | Impact on Catastrophic Forgetting |
|---|---|---|
| Standard LoRA | Freezes base weights; trains low-rank adapter matrices ($\Delta W = BA$). Updates ~0.5-5% of parameters 2528. | Moderate risk. Preserves the base manifold, but adapter interference still causes noticeable forgetting over extended task sequences 1129. |
| QLoRA | Base model is quantized to 4-bit precision and frozen; LoRA adapters are trained on top to minimize VRAM 2527. | Moderate risk. Similar forgetting profile to LoRA, with minor additional accuracy degradation due to quantization 252728. |
| DeLoRA (Decoupled LoRA) | Explicitly decouples the direction of a weight update from its strength (magnitude) using a learnable scalar, establishing a bounded deviation 17. | High resistance. Prevents catastrophic overwriting that plagues standard LoRA at high learning rates by bounding how far weights can deviate from the base 17. |
| SR2-LoRA (Self-Rectifying) | Constrains inter-layer relation drift by applying Singular Value Decomposition (SVD) to align relation matrices from old and new tasks 23. | High resistance. Empirically improves average accuracy on continual learning benchmarks by preserving stable decision boundaries 23. |
| GainLoRA (Gated Integration) | Expands a new LoRA branch for each task but uses a gating module to minimize the new branch's contribution when processing old tasks 30. | High resistance. Reduces interference by routing task-specific data away from disruptive adapter weights 30. |
| CaLoRA (Causal-Aware LoRA) | Utilizes parameter-level counterfactual attribution to estimate causal effects, adjusting gradients to enable backward knowledge transfer rather than just preventing forgetting 31. | High resistance. Uniquely facilitates positive transfer, where learning a highly correlated new task actually improves performance on old tasks 31. |
Empirical Case Studies in Applied Artificial Intelligence
The theoretical vulnerabilities of neural networks translate into severe operational risks when AI systems are deployed in dynamic, high-stakes environments. Catastrophic forgetting is not merely an academic benchmark issue; it dictates the boundaries of commercial AI viability, safety, and scalability 1439.
Medical Diagnostic Artificial Intelligence
Healthcare AI relies entirely on continuous adaptation. Diagnostic models must evolve to recognize novel pathogens, integrate new imaging hardware protocols, and adjust to shifting demographic data over time 144041. However, sequential updates introduce life-threatening risks. If a model trained to detect a broad spectrum of lung diseases is subsequently fine-tuned exclusively on data for a novel respiratory virus, catastrophic forgetting may cause the model to lose its capacity to accurately diagnose the original conditions 1442.
The consequences of this phenomenon are measurable and alarming. In clinical evaluations, LLMs utilized for medical triage and differential diagnosis have exhibited dangerous fragility. In the landmark 2025 NOHARM benchmark study from Stanford and Harvard, 31 leading language models tested against 100 real patient cases produced severely harmful recommendations in 22.2% of instances 43. Crucially, 76.6% of these harms were omissions - the models simply failed to recommend essential, standard-of-care tests and treatments because their general clinical grounding had been overwritten or was inherently unstable 43.
Similarly, researchers at Mass General Brigham analyzed 21 AI models across 29 standardized medical case scenarios (representing 16,254 responses) and found that leading AI chatbots failed to accurately generate a differential diagnosis from initial symptoms more than 80% of the time 32. The study noted that conversing more with the chatbots did not reliably improve the probability of a correct diagnosis, highlighting the difficulty these models have in retaining robust, generalized clinical reasoning when context shifts 3233. In real-world emergency triage simulations, OpenAI's ChatGPT Health was shown to under-triage 52% of genuine medical emergencies, failing to grasp the gravity of atypical presentations outside its immediate fine-tuned distribution 43.
Medical Image Segmentation and Data Silos
In the field of medical imaging, continual learning models face severe "domain shift" challenges 413435. Data generated by different hospitals utilizes disparate MRI, OCT, or CT scanner calibrations, causing the underlying image distributions to vary 413548. Continual medical image segmentation requires handling Domain-CL (cross-center domain shifts), Class-CL (incremental anatomical structure learning), and Organ-CL (cross-organ segmentation) 41.
When developers attempt to adapt a centralized model (e.g., for prostate cancer detection in T2-weighted MRI using the PI-CAI dataset) to a new hospital's unique data stream, standard training erases the model's proficiency on the original hospitals' data 3548. Retraining the model from scratch on a combined dataset is often legally and practically impossible due to strict patient data privacy regulations that prohibit the pooling and long-term storage of raw medical records 414836. Therefore, continual learning techniques - such as Knowledge Distillation (KD) using generated synthetic images from past tasks - are a mandatory prerequisite for scalable clinical AI 483637.
Autonomous Driving Systems and Robotics
Autonomous vehicles (AVs) and robotic systems operate in highly non-stationary, physics-bound environments 751. An AV perception system must continuously adapt to new topographies, changing weather patterns, and novel object classes, commonly referred to as the "long-tail" problem 7. If an autonomous system utilizes standard backpropagation to learn a new environment - for instance, adjusting its visual weights to navigate heavy snowfall in a new geographic region - it risks catastrophic interference with its previously established driving competencies 1439.
A model might adapt to the snow but abruptly lose the accuracy of its pedestrian detection algorithms or forget how to interpret standard traffic signs from its original training city 914. In simulated robotics environments (e.g., ecorobots operating in physics engines), researchers note that a robot's mechanical design heavily influences the loss surface of the weight manifold. Changes in sensor distribution or morphology can drastically alter the likelihood of the neural controller falling into local optima that trigger catastrophic interference during multitask learning 5152. The inability to accumulate knowledge stably forces AV developers to rely on computationally massive, slow retrains of the entire system from scratch, delaying deployment and driving up immense environmental and financial costs 39.
Architectural and Algorithmic Mitigation Strategies
To overcome catastrophic forgetting, researchers have developed various algorithmic and architectural interventions. These Continual Learning (CL) strategies aim to explicitly manage the stability-plasticity dilemma by protecting old knowledge while accommodating the new 393538.
Regularization Methods and Elastic Weight Consolidation (EWC)
Regularization approaches operate by adding mathematical constraints to the loss function, explicitly penalizing the network for altering parameters that are deemed important to previously learned tasks 91354. This approach mimics neurobiological models of "synaptic consolidation," where mammalian brains protect memories by rendering crucial synapses less plastic over long timescales 3940.
The most prominent algorithm in this class is Elastic Weight Consolidation (EWC), developed by Kirkpatrick et al. (2017) 5440. After the network learns an initial task, EWC assesses the importance of every individual weight by computing the diagonal of the Fisher Information Matrix 1354. When the network begins training on a subsequent task, a quadratic penalty term is appended to the standard loss function 5440. This penalty acts as an elastic, spring-like anchor: it pulls the weights back toward their optimal values for the first task, with the "stiffness" of the spring constraint directly proportional to the weight's Fisher importance score 543940.
Through a Bayesian interpretation, EWC applies a prior over the parameters based on the posterior distribution of the previous tasks 39. This enables fast learning rates on parameters that are poorly constrained by previous tasks and slow learning rates for those that are crucial, forcing the optimization algorithm to seek compromises in the weight manifold that satisfy multiple tasks simultaneously 3940. Other regularization strategies, such as the Information Maximization (IM) regularizer, apply class-agnostic constraints based on expected label distributions to preserve knowledge streams, proving particularly useful in memory-intensive domains like video continual learning 384142.
Rehearsal and Generative Replay Mechanisms
Rehearsal methods take a data-centric approach to stabilize the network. To prevent the network from overwriting old tasks, the system continuously interleaves a subset of data from previous tasks into the training batches of the new task 1152441. By periodically revisiting historical data, the network approximates a joint probability distribution, forcing the gradient updates to balance the demands of both old and new information 14142.
When storing actual raw data is impossible due to memory constraints or privacy laws, systems utilize "pseudo-rehearsal" or generative replay 12442. In this paradigm, an auxiliary generative model (e.g., a GAN) is trained alongside the main network. When learning a new task, the generative model synthesizes artificial data representing the old tasks, which is then used for rehearsal 423637.
Architecture and Parameter Isolation
Architectural approaches circumvent catastrophic forgetting by dedicating separate physical capacity to different tasks. By manipulating the network's structure, these methods explicitly prevent the overlapping of representations, isolating skills mechanically 1324. * Progressive Neural Networks (PNN): Instead of altering existing weights, PNNs instantiate an entirely new, separate column of neural network layers for every new task 54. Lateral connections are established to transfer features from the old frozen networks to the new network, allowing the system to leverage past knowledge without ever risking interference 54. * IF2Net (Innately Forgetting-Free Networks): Keeps the weights relative to each seen task strictly untouched before and after learning a new task, ensuring total preservation at the cost of expanding memory 59. * Hard Attention and Masking: Certain neurons or pathways are physically masked and frozen after learning a task, ensuring that subsequent gradient updates cannot access or alter them 61013.
Activation Function Engineering: Elephant Activation Functions
Recent research has begun addressing catastrophic forgetting not just through algorithmic add-ons, but by fundamentally redesigning the lowest-level neural building blocks. Studies indicate that forgetting is tightly linked to the gradient sparsity of the activation functions 434445. Standard activation functions (like ReLU or Tanh) allow dense gradient flow, which facilitates widespread, unchecked weight changes across the network, leading to high interference 44.
In response, researchers have proposed a new class called "Elephant Activation Functions" 434463. These functions are mathematically designed to generate both sparse representation values and sparse gradients simultaneously 4344. By utilizing these functions, a network naturally limits the number of parameters updated during any given learning step, preventing neural crosstalk. In reinforcement learning tasks (e.g., utilizing Deep Q-Networks or Rainbow algorithms) and sequential supervised tasks, simply replacing classical activation functions with Elephant functions significantly improves resilience to catastrophic forgetting, without requiring memory buffers, rehearsal, or complex task-boundary information 434446.
Computational Trade-Offs in Continual Learning
The selection of a continual learning strategy is governed by strict engineering and infrastructural trade-offs. The pursuit of perfect stability often incurs unacceptable costs in memory, processing time, or data privacy compliance 244142.
| Continual Learning Strategy | Core Mechanism for Preventing Forgetting | Computational / Training Overhead | Memory Overhead | Primary Limitations |
|---|---|---|---|---|
| Rehearsal / Experience Replay | Interleaves historical data with new data streams during training 2441. | High. Requires multiple training epochs over large combined datasets, increasing processing time significantly 4142. | High. Requires dedicated, scalable storage buffers for raw historical data. In video data, a single minute of 30fps video occupies the memory of 1800 images 4142. | Violates strict data privacy constraints; scales poorly over long lifespans 2436. |
| Regularization (e.g., EWC, IM) | Constrains parameter updates using calculated importance matrices (e.g., Fisher Information) 92454. | Low to Moderate. Calculating importance matrices takes compute, but overall training speed is largely maintained 3640. | Low. Requires storing only the importance matrices and old parameter states, yielding $O(1)$ scaling . | Less effective than rehearsal on highly dissimilar tasks; prone to capacity saturation over time 4142. |
| Architecture Isolation / Branching | Expands the network physically by adding new sub-networks or adapters for new tasks 243654. | Moderate. Training remains fast as only specific modules are updated 1324. | Very High (Unbounded). Network size grows linearly or exponentially with the number of tasks introduced 4154. | Results in massive, unwieldy models; requires explicit knowledge of task boundaries during inference 1341. |
As detailed in the computational comparison, rehearsal remains the empirical gold standard for retaining accuracy, but its intense computational overhead and fundamental incompatibility with data privacy laws render it unviable for many commercial applications 243641. Conversely, regularization methods like EWC provide a lightweight, privacy-compliant alternative, but they struggle to maintain strict separation between features when tasks become highly complex and numerous 364142.
The phenomenon of catastrophic forgetting represents a foundational bottleneck in the evolution of artificial general intelligence. As long as models rely on distributed representations updated via unconstrained gradient descent, the acquisition of new skills will continually threaten the stability of prior knowledge 4101439. Advancing toward true lifelong learning systems requires moving beyond brute-force retraining, demanding the integration of advanced regularization techniques, constrained parameter routing, and novel network architectures designed specifically to bridge the gap between artificial plasticity and biological stability 3944.