Benchmark contamination in large language models
Introduction to Evaluation Vulnerabilities
The rapid acceleration of capabilities in large language models and vision-language models relies fundamentally on the vast scale of their pre-training corpora and the mathematical sophistication of their neural architectures. To quantify these architectural and scaling advancements, the artificial intelligence research community utilizes standardized evaluation benchmarks designed to measure discrete cognitive and computational capabilities, ranging from reading comprehension and factual recall to advanced mathematical reasoning and multi-step code generation. However, the integrity of this evaluation paradigm is increasingly compromised by a structural vulnerability known as benchmark contamination.
Benchmark contamination, frequently referred to as data leakage, occurs when the specific test sets of an evaluation benchmark are inadvertently or deliberately incorporated into a model's pre-training or post-training data 12. When a language model possesses prior exposure to the specific questions and solutions it is meant to be evaluated against, its subsequent high scores reflect rote memorization rather than generalized reasoning 3. This artificial inflation of test scores distorts the perceived trajectory of artificial intelligence progress, creating an illusion of competence that frequently fails to translate into real-world production environments 34.
Accurate capability evaluation carries significant operational consequences. As language models are increasingly deployed in high-stakes domains - such as medical diagnostics, legal analysis, and automated software engineering - an overestimation of deductive reasoning ability due to data contamination presents severe operational, ethical, and security risks 45. Furthermore, for the academic and commercial research communities, benchmark contamination obfuscates the true efficacy of novel architectural modifications, optimization algorithms, and training techniques, as apparent performance gains may simply be an artifact of test set leakage rather than genuine algorithmic improvement 12.
Mechanisms of Training Data Leakage
To accurately diagnose and mitigate benchmark contamination, it is necessary to examine the data ingestion pipelines utilized to construct modern frontier models. Contemporary language models are trained on internet-scale datasets of unprecedented magnitude. For example, Alibaba's Qwen 2.5 architecture was trained on a corpus encompassing up to 18 trillion tokens 678. At this scale, the pre-training data captures a vast cross-section of the digitized world, indiscriminately absorbing academic repositories, software version control platforms, open forums, and digitized literature.
Because standard evaluation benchmarks - such as the Massive Multitask Language Understanding (MMLU) suite, the Grade School Math (GSM8K) dataset, and the HumanEval coding benchmark - are publicly hosted and discussed on these identical internet platforms, they are systematically ingested by automated web scrapers during the foundational construction of pre-training corpora 911.
Unintentional Data Ingestion
Information science researchers categorize benchmark contamination into two primary vectors: unintentional and deliberate 9. Unintentional contamination is an unavoidable byproduct of the sheer volume of internet-scale data collection. When compiling a dataset of trillions of tokens, manual curation and perfect filtration are impossible. Data filtering techniques, such as deduplication and n-gram collision detection, are routinely employed by developers to sanitize data 71011.
However, these programmatic filters often fail to isolate sophisticated or subtle manifestations of benchmark data. A test question might appear in a modified format, translated into a different language, or discussed implicitly within an academic forum thread. In these instances, the underlying semantic content and logical structure of the benchmark are absorbed into the model's parametric memory without ever triggering exact-string-match filters 212. Consequently, the model learns the specific heuristic required to solve the benchmark question without necessarily learning the generalized rule.
Deliberate Benchmark Exploitation
Conversely, malicious or deliberate contamination occurs when model developers knowingly inject benchmark test sets, or synthetically altered variations thereof, into the pre-training or fine-tuning data mixtures to artificially boost the model's leaderboard rankings 915. As open-source leaderboards heavily influence the commercial adoption, venture capitalization, and perceived prestige of artificial intelligence models, the financial and reputational incentives to overfit to public benchmarks are substantial.
This practice renders the resulting evaluation scores entirely meaningless as a diagnostic tool for generalized intelligence. The complexity of distinguishing between genuine capability breakthroughs and deliberate benchmark manipulation has led to increasing demands for standardized transparency reporting within the machine learning industry 13.
The Memorization Versus Generalization Paradigm
The core epistemological challenge in modern artificial intelligence evaluation is distinguishing between a model that has genuinely learned a generalized problem-solving heuristic and a model that has merely memorized a specific input-output sequence 14. Memorization occurs when the gradient descent optimization process drives the negative log-likelihood of a specific sequence close to zero, ensuring that the model will reproduce the text almost verbatim when prompted with the appropriate context.
In the context of autoregressive language models, memorization is not strictly binary; it exists on a spectrum ranging from verbatim lexical recall to structural and stylistic imitation. When a language model is exposed to a benchmark during training, the exposure fundamentally alters the probability distribution of the model's outputs. A contaminated model will assign unusually high probabilities to the specific phrasing of the correct answer, bypassing the complex, intermediate chain-of-thought reasoning steps that an uncontaminated model would normally be required to generate 215. Research indicates that fact-heavy tasks, such as specific trivia questions or entity recall, are highly vulnerable to strict memorization, whereas deeper reasoning tasks exhibit partial contamination where the model memorizes the structural template of the solution rather than the exact text 14.
Recent studies propose robust theoretical frameworks, such as Contamination Detection via Context (CoDeC), to formally disentangle memorization from true generalization. The CoDeC methodology measures how in-context learning environments affect a model's output confidence. For an unseen, uncontaminated dataset, providing in-context examples typically boosts the model's predictive confidence, as it allows the model to infer the task pattern dynamically. Conversely, if a model has already memorized the dataset during pre-training, adding novel in-context examples acts as disruptive noise. This noise breaks the rigid, learned sequences and paradoxically reduces the model's confidence 19. This measurable bifurcation in behavior highlights the brittle nature of memorized benchmark performance compared to genuine cognitive generalization.
Theoretical Detection Methodologies
Because the pre-training datasets of proprietary frontier models, and increasingly many open-weight models, are not publicly accessible, independent researchers cannot simply conduct string searches within the training data to prove benchmark inclusion. Consequently, the field of artificial intelligence auditing has developed sophisticated "closed-data" or "black-box" detection methodologies. These advanced techniques infer the presence of training data based solely on the model's post-training output behaviors, response consistency, and token probability distributions 11617.
Lexical Overlap and N-Gram Matching
Historically, model developers assessed data leakage by measuring the exact string overlap between test sets and pre-training corpora. For instance, the original GPT-2 technical report calculated contamination based on the collision of 8-gram tokens between the evaluation sets and the WebText training corpus 117. Similarly, contemporary models like the Qwen-2.5-Coder architecture attempt to mitigate leakage by removing any training data points that share a 10-gram collision with known test sets 17.
While N-gram matching is computationally efficient, it is widely recognized as a highly fragile and easily circumvented defense. It is trivial to bypass lexical filters through simple data augmentation. If a benchmark test question is paraphrased by a synthetic data generator, translated into a different language, or syntactically restructured, a standard N-gram filter will fail to flag it 1218. The semantic core of the problem successfully leaks into the training set undetected. Consequently, models evaluated on superficially "decontaminated" datasets can still achieve drastically inflated performance by exploiting the memorized semantic concepts, rendering simple lexical matching insufficient for rigorous auditing.
Probabilistic Detection via Min-K% Prob
To address the severe limitations of exact string matching, computational linguists developed probabilistic detection methods that operate on the fundamental principles of autoregressive language modeling. During pre-training, a large language model optimizes its neural parameters to maximize the likelihood of the specific sequences in its training corpus. Therefore, text that the model has observed during training will consistently be assigned higher generation likelihoods than completely novel, out-of-distribution text 15.
The Min-K% Prob method operationalizes this theoretical insight. The underlying hypothesis states that a completely unseen example will naturally contain a few "outlier" words or tokens that possess very low generation probabilities under the language model's learned distribution. Conversely, an example that the model has memorized directly from its training data is far less likely to feature such extreme low-probability outliers 16. By mathematically isolating and measuring the probability of the least likely tokens (the bottom K%) in a given sequence, auditors can determine with high statistical accuracy whether the text was part of the original training set.
Experiments conducted on dynamic, timestamped benchmarks like WikiMIA demonstrated that the Min-K% Prob method achieved a 7.4% improvement in detection accuracy over reference-model baselines 16. An advanced iteration of this technique, designated as Min-K%++, normalizes the individual token probabilities against the statistical variance of the categorical distribution across the model's entire vocabulary. This normalization accurately reflects the relative likelihood of the target token compared to other candidate tokens, improving state-of-the-art contamination detection rates by an additional 6.2% to 10.5% 1516. These probabilistic methods allow for highly reliable contamination auditing even when the target model's training data is locked behind corporate secrecy 16.
Output Distribution Peakedness and Self-Critique Probing
Beyond foundational pre-training, modern language models undergo extensive post-training fine-tuning, typically involving Reinforcement Learning from Human Feedback (RLHF) or Direct Preference Optimization. Contamination occurring at this specific post-training stage requires distinct detection methods, as the reinforcement learning phase fundamentally alters the model's response distribution rather than just the likelihood of the prompt 23.
Methods such as Contamination Detection via output Distribution (CDD) examine the stochastic consistency of a model's generated answers. Given the vast vocabulary of a large language model, standard generation under high temperatures should theoretically exhibit significant semantic diversity. However, if a model has formed a strict memorization pathway during its training phases, its output distribution becomes abnormally "peaked" or collapsed 2. If an auditor samples multiple generated responses for a single benchmark prompt and observes unusually long sequences of identical tokens across the diverse samples, it acts as a strong statistical signal of policy collapse and data contamination 2.
Further innovations in this domain, such as Self-Critique probing, utilize complex entropy metrics to detect this reinforcement-learning-induced policy collapse. By analyzing the entropy of the response distribution, these detectors achieve Area Under the Curve (AUC) improvements of up to 30% over standard perplexity baselines 1523.
Contextual Perturbation and Time Travel Attacks
Another highly effective methodology for exposing memorization in black-box models is the "Time Travel" or guided completion attack. This approach involves prompting the language model with the first half of a known benchmark question and forcing it to generate the exact remainder. If a model can auto-complete a complex benchmark question verbatim without being provided the full context, it serves as undeniable proof of training set memorization. This method achieved between 92% and 100% accuracy in detecting contamination in proprietary models across specific datasets 312.
Furthermore, multi-modal semantic perturbation has been proposed for Vision-Language Models. By utilizing diffusion algorithms to subtly alter the visual semantic composition of an image while strictly preserving the core question's difficulty, auditors can expose vision models that have merely memorized an image-text pairing. A contaminated model's performance will completely collapse on the perturbed variant, whereas a genuinely capable model will maintain its accuracy 1925.
Model-Specific Audits and Case Studies
The extent of benchmark contamination across both open-weight architectures and proprietary commercial models has been the subject of extensive, independent academic auditing. Utilizing natural temporal experiments and newly commissioned, highly encrypted datasets, researchers have documented significant inflation in reported artificial intelligence capabilities across the industry.
OpenAI Architecture Evaluations
One of the most definitive early proofs of benchmark contamination leveraged the natural chronological cutoff dates inherent to model training data. In early evaluations, researchers audited GPT-4 on programming challenges sourced from the Codeforces platform. Because GPT-4 possessed a strict, publicly documented training data cutoff of September 2021, competitive programming problems published after this specific date were guaranteed to be unseen by the model.
The subsequent evaluation revealed a stark performance cliff. The model successfully solved 10 out of 10 "easy" difficulty problems published before the 2021 temporal cutoff, but solved 0 out of 10 "easy" problems published after the cutoff 3. This extreme temporal disparity provided incontrovertible evidence that the model's proficiency on the earlier programming problems was derived entirely from training data memorization rather than an inherent, generalized capability to execute complex programming logic 3. Similar guided-completion attacks confirmed contamination in proprietary models regarding standard natural language processing datasets, including AG News, WNLI, and XSum 312.
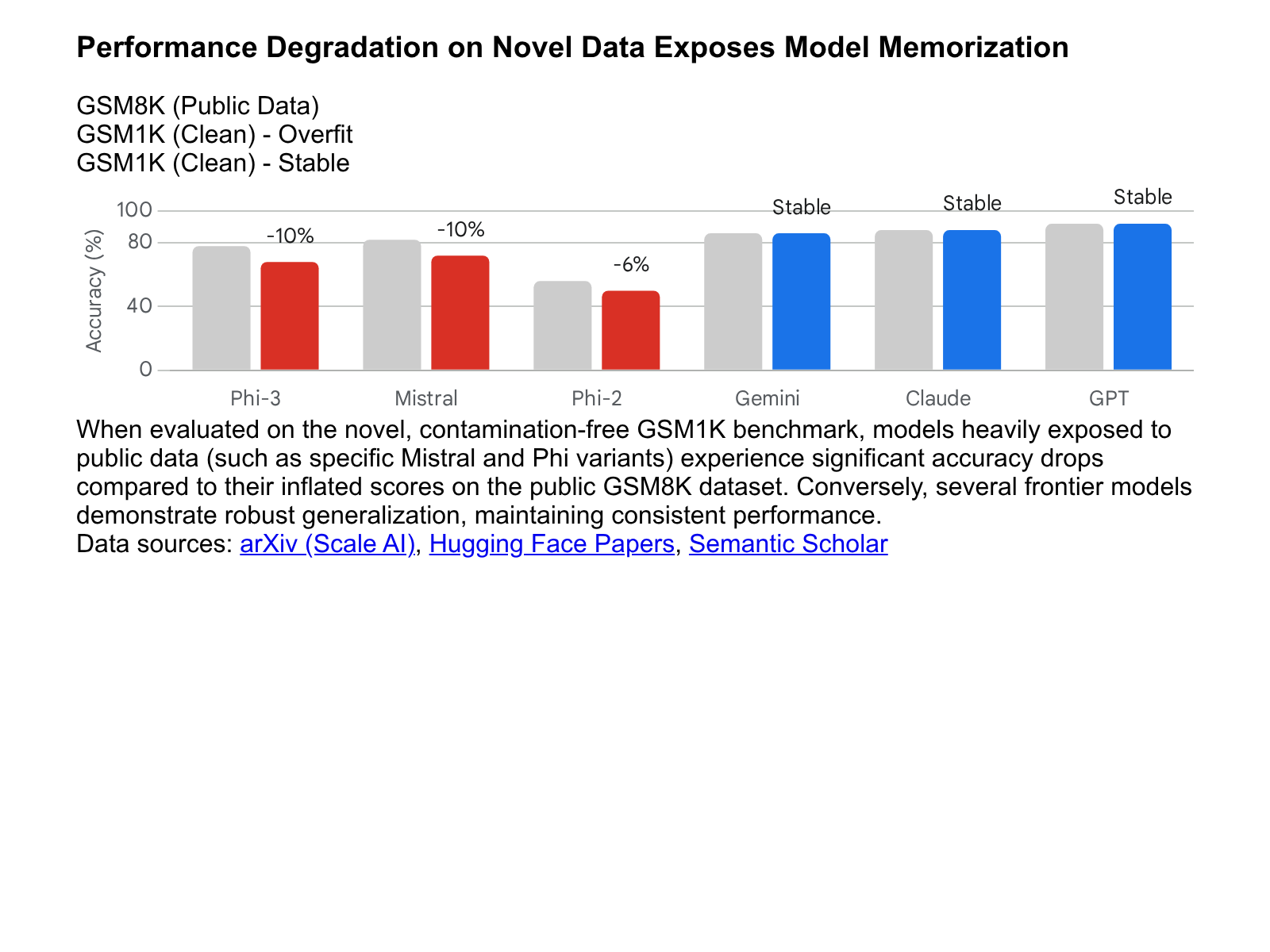
The GSM8K to GSM1K Performance Discrepancy
The Grade School Math 8K (GSM8K) dataset has served as the prevailing industry standard for evaluating the elementary mathematical reasoning capabilities of large language models. As models have scaled in parameters and data volume, performance on GSM8K has heavily saturated, with leading models routinely scoring above 90% accuracy. To determine precisely how much of this apparent mathematical mastery was attributable to data contamination, researchers commissioned a novel dataset, GSM1K 202122.
GSM1K was designed to perfectly mirror the complexity, average step-count, and semantic structure of GSM8K. However, it was generated entirely post-2024 by human annotators without synthetic assistance, guaranteeing its absolute absence from any existing model's pre-training data 2324.
When evaluated on GSM1K, significant performance degradation was observed across multiple widely deployed language model families. The Mistral and Phi model families exhibited severe accuracy drops ranging from nearly 10% to 13% compared to their heavily inflated GSM8K scores 2223. Advanced statistical analysis utilizing the ConStat methodology confirmed these high contamination levels, demonstrating a statistical significance of p < 0.005 for models like Mistral-7B on both the GSM8K and Hellaswag benchmarks 3.
Furthermore, researchers identified a distinct positive relationship (yielding a Spearman's correlation coefficient between 0.32 and 0.36) between a specific model's propensity to generate GSM8K-like text unconditionally and the overall size of its performance gap between the contaminated GSM8K benchmark and the clean GSM1K benchmark 202122. This strong correlation implies that models suffering the largest accuracy drops had actively memorized vast portions of the original public benchmark.
Conversely, certain frontier models - including variations of GPT-4o, Claude 3.5 Sonnet, and Gemini - demonstrated minimal evidence of mathematical overfitting. These specific architectures maintained consistent accuracy between GSM8K and GSM1K, indicating a robust, generalized capacity for mathematical reasoning that does not rely on benchmark memorization 2223.
Alibaba Qwen and Synthetic Perturbation Failures
The Qwen 2.5 series of models, despite achieving apparent state-of-the-art results on mathematical and coding benchmarks following exposure to 18 trillion pre-training tokens, has similarly been scrutinized for severe underlying contamination. During audits of the MATH-500 benchmark, researchers discovered that Qwen 2.5's high performance was heavily reliant on the specific response templates and structural cues present in the public dataset 625.
To test the true depth of the model's numerical reasoning, researchers generated a "RandomCalculation" dataset composed of fully synthetic arithmetic problems created strictly after Qwen 2.5's release date 25. Furthermore, they deliberately altered the standard response templates of the original MATH-500 problems to remove recognizable formatting cues. Under these controlled perturbations, Qwen 2.5's completion rate collapsed entirely to zero on specific subsets, and its overall accuracy fell to merely two percent 25.
This severe performance degradation indicates that the model was likely pre-trained on extensive online repositories containing the benchmark problems and their exact solutions, allowing it to shortcut true mathematical reasoning via sophisticated pattern matching 25. When the formatting deviates from the memorized template, the underlying lack of generalizable logic is immediately exposed.
Open-Weight Ecosystem Vulnerabilities
Contamination is particularly problematic within the open-weight ecosystem, where transparency regarding the specific contents of pre-training corpora is frequently lacking. Independent audits have consistently flagged open models for high contamination. For example, analyses of the Meta Llama 2 and Llama 3 families identified statistically significant contamination on the Hellaswag and ARC-Challenge benchmarks 3.
Furthermore, the proliferation of models that rely on synthetic data generated by larger frontier models creates a cascading contamination effect. If a 7-billion parameter open model is trained on outputs generated by GPT-4, and GPT-4 has memorized a benchmark, the smaller model will indirectly inherit that benchmark contamination, resulting in artificially high scores that fail to reflect its true, limited parameter capacity 12.
The Evolution of Contamination-Resistant Benchmarks
The widespread revelation of benchmark contamination has triggered a crisis of confidence within the artificial intelligence evaluation ecosystem. A benchmark score is only mathematically meaningful if it serves as a reliable proxy for out-of-distribution generalization. When public benchmarks like GSM8K or MMLU become thoroughly saturated - with models achieving near 90% accuracy largely through partial memorization - they cease to be useful diagnostic tools for assessing model utility 426.
In response to this systemic failure, the machine learning industry is transitioning toward dynamic, encrypted, and structurally robust evaluation frameworks explicitly designed to resist data leakage.
Comparing Evaluation Frameworks
The following table summarizes the primary contamination-resistant evaluation frameworks currently utilized to provide accurate assessments of language model capabilities.
| Evaluation Framework | Primary Testing Paradigm | Contamination Mitigation Strategy | Structural Strengths |
|---|---|---|---|
| LiveBench | Objective Ground-Truth Testing | Continuous, time-stamped data rotation (updated monthly/bi-annually); entirely novel questions sourced from current events 2734. | Immune to static pre-training leakage; removes LLM-as-judge grading biases 2728. |
| MMLU-CF | Static, Closed-Source Multiple Choice | Deep semantic rewrites of existing questions; strict encryption and access control of the 10,000-question test set 936. | Highly calibrated for broad domain knowledge; forces zero-shot reasoning without training cues 15. |
| Chatbot Arena (LMSYS) | Crowdsourced Human Preference Rating | Dynamic, user-generated prompts evaluated via real-time blind A/B testing 343729. | Captures subjective conversational fluency, style, and adherence to highly complex, novel instructions 29. |
| Humanity's Last Exam (HLE) | Extreme Difficulty Edge-Case Analysis | 2,500 highly specific, expert-level academic questions designed to be strictly beyond current AI capabilities 4. | Prevents benchmark saturation entirely; effectively un-memorizable due to immense conceptual complexity 4. |
Systematically Decontaminated Static Test Sets
The Massive Multitask Language Understanding (MMLU) benchmark has historically served as the definitive standard for evaluating general world knowledge and reasoning across 57 distinct academic disciplines 36. However, due to its public ubiquity, standard MMLU questions are deeply embedded in the pre-training datasets of nearly all frontier models.
To reclaim the utility of this metric, researchers engineered MMLU-CF (Contamination-Free). The rigorous construction of MMLU-CF involved screening over 200 billion public documents to curate 20,000 completely novel multiple-choice questions spanning 14 diverse fields 91530.
Crucially, MMLU-CF combats both unintentional and malicious leakage vectors. To prevent unintentional leakage, the dataset designers apply systematic decontamination rules to the question phrasing - such as complex statement rephrasing, option shuffling, and the injection of logical "None of the above" options. These perturbations ensure that automated web scrapers cannot easily map the data to existing internet text patterns 93630. To prevent malicious, deliberate leakage by model developers, the 10,000-question test set remains strictly closed-source and encrypted, requiring specific API calls for evaluation rather than open downloading 915.
The empirical results of evaluating frontier models on MMLU-CF are highly revealing. While advanced models like GPT-4o score approximately 88.0% on the standard, contaminated MMLU benchmark, their performance drops substantially to 71.9% (zero-shot) on the strictly isolated MMLU-CF test set 915. This massive performance degradation - frequently reflecting a loss of 14 to 16 accuracy points for top models - strips away the illusion of mastery, revealing the actual, uninflated reasoning capabilities of contemporary artificial intelligence systems 36.
Dynamic and Temporal Evaluation Frameworks
Because any static dataset, regardless of encryption, will eventually leak or become trivially solvable by subsequent model generations, the ultimate defense against contamination is temporal dynamism. The LiveBench framework represents a paradigm shift toward continuous, rolling evaluation.
LiveBench assesses language models across multiple cognitive categories - including mathematical reasoning, algorithmic coding, data analysis, and complex instruction following - using a strictly contamination-resistant methodology 3428. The benchmark achieves this defense by sourcing its test questions exclusively from recently published, time-stamped information streams, such as the latest mathematics competition results, newly published arXiv pre-prints, and current news articles 2837.
To maintain continuous integrity, LiveBench refreshes its entire question bank on a monthly or bi-annual basis 2734. By continually shifting the target data forward in time, it becomes mathematically impossible for a model trained prior to the current month to have encountered the test data. Furthermore, LiveBench scores generated answers automatically based on objective, mathematically verifiable ground truths rather than relying on "LLM-as-a-judge" grading architectures 2731. This design explicitly eliminates the well-documented bias wherein an LLM evaluator preferentially scores responses that match its own stylistic outputs, ensuring a purely capability-based evaluation 2731.
The rigor of the LiveBench framework is reflected in its scores: while top proprietary models easily surpass 90% on static legacy benchmarks, the leading architectures achieved below 60% to 65% accuracy on LiveBench's rigorous, uncontaminated problem sets 2728.
Human-Preference and Conversational Arenas
While automated, programmatic benchmarks like LiveBench provide verifiable metrics for mathematical and coding capabilities, they are effectively complemented by human-in-the-loop systems such as the LMSYS Chatbot Arena.
The Chatbot Arena utilizes blind pairwise comparisons driven by real user prompts. This framework naturally defends against data contamination because the "test set" is generated organically in real-time by the global user base, guaranteeing that the exact sequence of instructions has not been encountered during pre-training 3429. The Arena provides an Elo rating system that captures the subjective nuances of conversational fluency, instruction adherence, and formatting that rigid mathematical benchmarks cannot measure. Together, these complementary frameworks provide a more holistic, honest, and robust reflection of a language model's true operational utility in production environments.
Strategic Implications for Artificial Intelligence Auditing
The pervasive nature of benchmark contamination fundamentally alters the economics and strategic deployment of artificial intelligence. For the enterprise sector, relying blindly on public leaderboard scores to drive major software procurement decisions is increasingly hazardous. A language model that achieves a 95% pass rate on an open-source coding benchmark may fail disastrously when deployed on a company's proprietary, localized codebase if that initial public score was merely a product of memorizing vast swaths of public GitHub repositories rather than learning generalized syntax 4.
As the performance convergence among frontier artificial intelligence labs tightens, the distinction between open-weight models (such as Meta's Llama 3 or Mistral's Large 3 architectures) and proprietary models (such as Anthropic's Claude 3.5 Sonnet) becomes heavily dependent on evaluating true, out-of-distribution generalization 32. The documented instances of specific models dropping significantly in capability when test questions are semantically altered highlight the critical necessity for aggressive, independent auditing prior to deployment 253343.
The DCR Framework and Standardized Reporting
The phenomenon of data leakage emphasizes that the current industry trajectory of simply scaling parameter counts and data volume is insufficient if the foundational evaluation metrics are mathematically compromised. As the machine learning industry matures, the adoption of closed-source verification sets, dynamic temporal benchmarks, and rigorous probabilistic detection algorithms will be imperative 1916.
To standardize this process, researchers advocate for the implementation of frameworks like DCR (Detect, Quantify, Adjust). The DCR framework mandates that developers systematically detect benchmark data contamination, quantify the specific overlap between the pre-training corpus and the test sets, and mathematically adjust the final evaluation metrics to account for the detected leakage risk 13. Transparency reporting standards, akin to Mistral's comprehensive environmental Life Cycle Assessments 34, must be expanded across the industry to include mandated disclosure of dataset overlap. Only through contamination-aware evaluation and rigorous public auditing can the artificial intelligence community ensure that the models being deployed are genuinely intelligent, rather than merely encyclopedic databases.