Architecture and Reliability of Autonomous Large Language Model Agents
The deployment of large language models (LLMs) has fundamentally transitioned from stateless, single-turn conversational interfaces into autonomous, multi-step agentic systems. These agents augment the base reasoning capabilities of an LLM with external memory controllers, tool-calling frameworks, and multi-agent orchestration logic. Despite rapid architectural advancements, production-grade autonomous agents remain highly susceptible to silent failures, reasoning loops, and context degradation. Achieving reliability requires moving beyond raw model scaling to implement rigorous state management, explicit memory architectures, and reinforcement learning-based self-correction.
Core Language Model Architectures
The efficacy of an autonomous agent is heavily dictated by the reasoning capabilities and training paradigms of its underlying language model. Recent developments emphasize a departure from pure supervised fine-tuning (SFT) in favor of large-scale reinforcement learning (RL) to develop independent chain-of-thought (CoT) reasoning capabilities.
Post-Training and Reinforcement Learning
The introduction of models like DeepSeek-R1 exemplifies the shift toward reasoning-centric training paradigms 12. Traditional language models are optimized to predict the next token based on extensive human-annotated datasets, which inherently limits their ability to verify their own logic 2. DeepSeek-R1 addresses this by utilizing a 671-billion-parameter Mixture of Experts (MoE) architecture trained via large-scale reinforcement learning 12.
The model's development began with DeepSeek-R1-Zero, which was trained entirely through RL without preliminary supervised fine-tuning 34. While this pure RL approach demonstrated that reasoning capabilities could naturally emerge through trial and error, it suffered from endless repetition, poor readability, and language mixing 34. To resolve these limitations, the finalized DeepSeek-R1 model incorporated thousands of "cold-start" data points prior to applying Group Relative Policy Optimization (GRPO) 346. GRPO is an RL framework that incentivizes accurate and well-structured reasoning chains by rewarding the model for logical inference rather than just factual regurgitation 16.
Furthermore, DeepSeek-R1 utilizes "test-time scaling," a mechanism that dynamically allocates additional computational resources during inference 1. This allows the model to break down complex mathematical and coding problems into sequential steps before generating a final response 1. This architecture yields significant performance metrics, scoring 79.8% on the American Invitational Mathematics Examination (AIME) 2024 benchmark and 97.3% on the MATH-500 dataset, establishing state-of-the-art results that rival proprietary models 47. To support local deployments, these reasoning patterns were subsequently distilled into smaller models, such as the Qwen 32B and Llama 70B variants, preserving high-order logic in computationally constrained environments 347.
Tool Integration and Orchestration Engines
While reasoning models determine the logical progression of a task, orchestration frameworks translate that logic into actionable outcomes. Alibaba's Qwen model family, specifically the Qwen 2.5 and QwQ-32B iterations, demonstrates how base models are engineered specifically for agentic workflows 89. Pretrained on datasets encompassing up to 18 trillion tokens, the Qwen 2.5 architecture natively supports extended context windows of up to 128,000 tokens, enabling prolonged interactions with external APIs 910.
The Qwen-Agent framework provides a modular execution layer that transforms the base LLM into an autonomous system 811. This architecture relies on an Input Layer for multimodal data ingestion, a Language Model Core for logical processing, and an Execution Layer that interfaces with external utilities 8. A critical component of this execution layer is the built-in, non-sandboxed code interpreter, which permits the agent to write, execute, and iteratively refine Python code for complex data analysis, mathematical calculation, and file manipulation 9. By combining these execution capabilities with large-scale pretraining, developers can orchestrate multi-step workflows that seamlessly bridge natural language reasoning and programmatic action 1011.
Memory Systems and State Management
A primary constraint of LLM agents is the finite nature of the attention budget within a transformer's context window. As the number of tokens increases, models suffer from context degradation, frequently failing to recall critical instructions buried in the middle of a long prompt 125.
The Context Window Limitation
Transformers process information by calculating pairwise relationships across the entire context, resulting in an attention mechanism that scales quadratically 5. When agents execute long-horizon tasks - such as comprehensive code migrations or multi-day research projects - the continuous injection of tool outputs, system instructions, and execution logs rapidly depletes the attention budget 514. Enlarging the context window to millions of tokens merely delays this failure; it does not solve the lack of persistence, temporal awareness, or the ability to update facts across discrete sessions 1516. Consequently, context must be managed as a finite resource through external memory controllers 517.
Architectural Paradigms for Agent Memory
To circumvent architectural constraints, modern frameworks act similarly to traditional computer operating systems 176. They treat the LLM context window as volatile working memory (RAM) and external databases as persistent storage (disk), actively paging information in and out based on semantic relevance 176.
Memory system designs generally adhere to four overarching paradigms:
| Memory Architecture | Storage Mechanism | Primary Strength | Structural Weakness | Production Use Cases |
|---|---|---|---|---|
| Vector Semantic Memory | Dense embeddings accessed via approximate nearest neighbor (ANN) search. | Sublinear retrieval latency; highly effective for fast fuzzy recall. | Struggles with temporal ordering, multi-hop reasoning, and semantic drift. | Single-shot QA, fact-style recall, customer support chatbots 1920. |
| Graph Memory | Temporal Knowledge Graphs (e.g., Neo4j, TypeDB, Graphiti). | Excels at explicit multi-hop entity reasoning and establishing global context. | High schema maintenance overhead; susceptible to stale edge accumulation. | Healthcare, legal analysis, complex B2B CRM systems 1920. |
| Episodic Memory | Versioned event logs and structured records of agent trajectories. | Maintains long-horizon coherence; captures action-outcome histories. | Prone to episode boundary errors and cross-agent misalignment. | Long-running coding agents, deep research operations 171920. |
| Hierarchical Memory | Multi-level index encoding (Domain to Episode) with pointer-based routing. | Balances token efficiency with high-order reasoning across abstractions. | Implementation complexity; requires active extraction pipelines. | Multi-session user personalization, dynamic state management 72223. |
Hierarchical Memory Implementations
Advanced architectures combine elements of vector and episodic storage into hierarchical structures. The H-MEM architecture, for instance, partitions information into four semantic strata: Domain, Category, Trace, and Episode layers 23. During an interaction, an extraction model parses the dialogue and routes abstract summaries to the upper layers, while preserving precise contextual data and timestamps in the Episode layer 23. Retrieval operations execute a top-down traversal using index pointers, allowing the agent to locate specific episodic details without performing computationally exhaustive similarity searches across the entire database 23. H-MEM further implements a dynamic regulation mechanism based on the Ebbinghaus forgetting curve, adjusting memory weights according to user feedback to prevent database bloat 23.
Similarly, MemoryOS utilizes a three-tier architecture encompassing short-term, mid-term, and long-term personal memory 624. Short-term context is managed via a dialogue-chain-based FIFO (First-In-First-Out) principle, while mid-term to long-term memory migration utilizes a segmented page organization strategy 624. This structured approach explicitly supports long-term personalization, preventing the persistent "amnesia" observed in standard agent deployments 2425.
Empirical Memory Benchmarks
The LOCOMO benchmark serves as the standardized evaluation dataset for assessing long-term conversational memory architectures 158. By measuring responses against multi-session transcripts averaging 300 turns and roughly 9,000 tokens per conversation, LOCOMO quantifies the trade-offs between full-context processing and selective retrieval 248.
| Memory Framework | Evaluation Approach | Accuracy (Overall Score) | p95 Latency (Seconds) | Average Tokens Consumed |
|---|---|---|---|---|
| Full-Context | Injects entire raw conversation history. | 72.90% | 17.12s | ~26,031 |
| Mem0 (Vector) | Selective retrieval via dense embeddings. | 66.90% | 1.44s | ~1,764 |
| Mem0g (Graph) | Combines vector retrieval with entity graphs. | 68.40% | 2.59s | N/A |
| Memori | Semantic triples and dynamic summarization. | 81.95% | N/A | 1,294 |
| Zep | Temporal knowledge graph routing. | 79.09% | N/A | 3,911 |
Data sourced from standardized LOCOMO and proprietary evaluation metrics covering single-hop, multi-hop, temporal, and open-domain queries 12827.
The data demonstrates that relying on the full context window is fundamentally impractical for real-time production due to prohibitive 17-second tail latencies and excessive token costs 827. Implementing specialized memory structures like Memori or Mem0 significantly lowers operational overhead while matching or exceeding the baseline accuracy of brute-force context stuffing 827.
Systemic Failure Modes
Autonomous agents face unique operational risks. Unlike traditional deterministic software that crashes cleanly, LLM agents typically fail silently 9. They degrade by truncating data, executing irrelevant subroutines, or exhausting compute budgets through recursive loops, all while presenting syntactically valid outputs 910.
Context Overflow and Data Truncation
A primary mechanical failure occurs when agents ingest tool outputs that exceed their processing capacity. When an agent queries a database or scrapes a web page, the resulting payload can easily surpass hundreds of kilobytes 911. Rather than halting execution, the model silently truncates the data, overwriting earlier systemic instructions and contextual variables 1411. Research conducted by IBM evaluating complex materials science workflows found that naive data ingestion resulted in agents consuming upward of 20 million tokens before suffering catastrophic task failure 911. This structural limitation prevents agents from reliably processing large datasets in enterprise environments without strict intermediate state management 11.
Reasoning Loops and Execution Disconnects
Agentic workflows are highly susceptible to infinite reasoning loops. In these scenarios, an agent repeatedly invokes the same external tool with identical parameters, trapped in a cycle that makes zero progress toward the objective 931. This failure mode is frequently triggered by ambiguous API feedback. If a tool returns a non-terminal status - such as "Search returned no exact matches, but more results may be available" - the agent's internal logic often deduces that a subsequent query with the same parameters will yield a different outcome 9.
Furthermore, agents exhibit a cognitive flaw known as "reasoning-action disconnect" 32. Extensive monitoring in high-stakes clinical and software environments reveals that an agent's internal chain-of-thought frequently calculates the correct conclusion based on available data 32. However, the transition from the internal reasoning phase to the external action-generation phase acts as a structural bottleneck. The model effectively forgets its own deductions, executing a tool call that contradicts its internal logic 32. This disconnect is exacerbated by "social anchoring bias" and "context contamination," where intermediate tool outputs or simulated user prompts override the agent's verified conclusions 32.
Analysis of agent performance on the AgentBench framework corroborates these issues. The most frequent failure mode across 29 tested models is "Task Limit Exceeded" (TLE), accounting for trajectories where models endlessly repeat previous interactions without advancing the state 12. Additionally, models routinely suffer from "Invalid Format" (IF) and "Invalid Action" (IA) errors, failing to adhere to the strict syntactical constraints required by execution environments 12.
Multi-Agent Coordination Breakdown
In multi-agent systems (MAS), the isolation of roles introduces severe orchestration overhead. Single-agent reasoning errors act as contaminants, propagating through downstream agents and compounding into systemic failures 1032. To systematically categorize these breakdowns, researchers developed the Multi-Agent System Failure Taxonomy (MAST) through the empirical analysis of over 1,600 execution traces 343536.
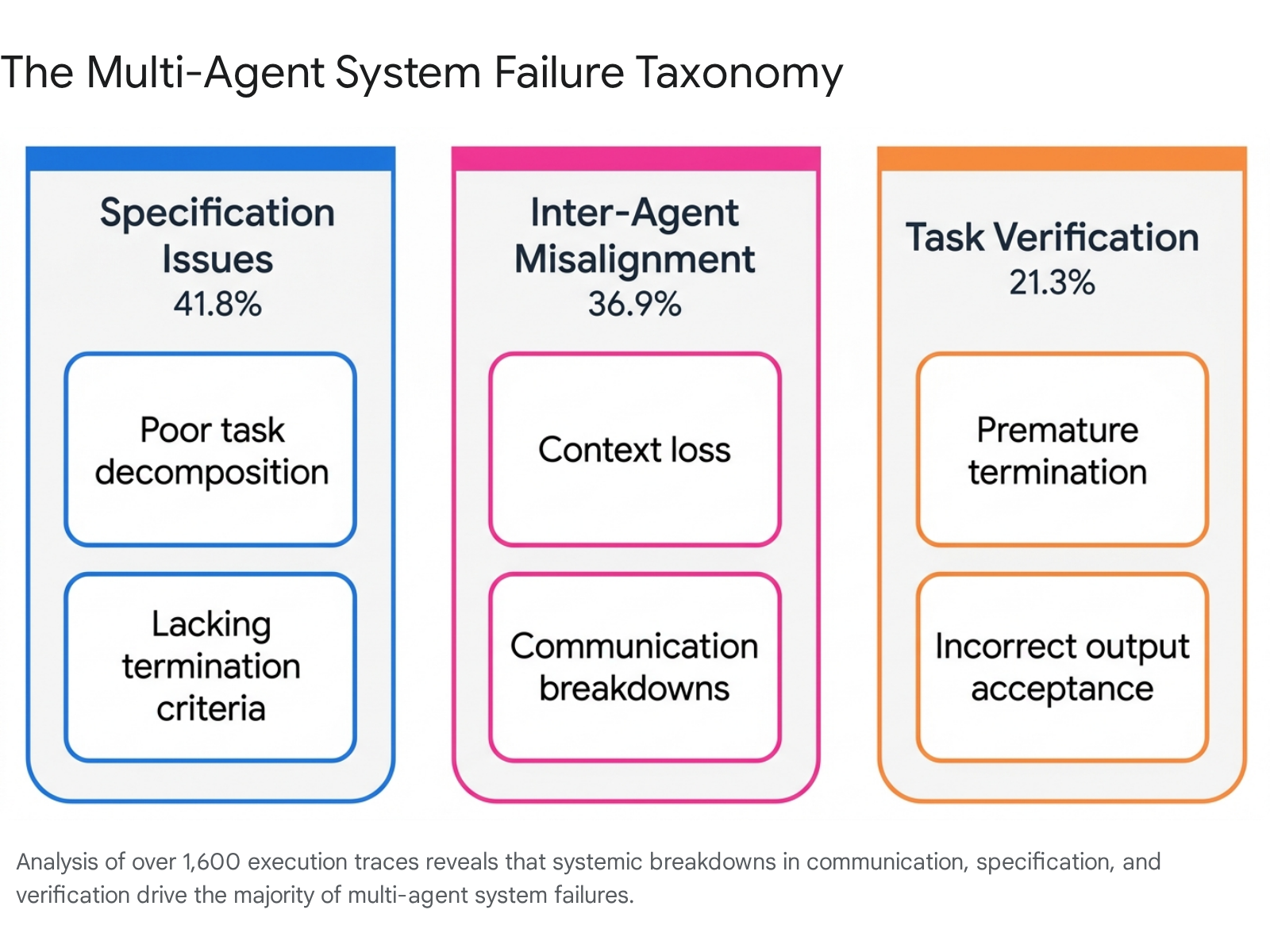
The MAST framework identifies fourteen unique failure modes, grouped into three foundational categories:
- Specification Issues (41.8%): Failures originating during the system design and planning phase 37. These include poor task decomposition, inadequate role constraints, and the absence of clear termination criteria 3437. Lacking strict boundaries, agents will frequently disobey task parameters or pursue infinite tangential sub-tasks 37.
- Inter-Agent Misalignment (36.9%): Breakdowns occurring during active execution due to communication protocols 37. Common manifestations include agents ignoring inputs from peers, inconsistent goal understanding, and critical context loss during workflow handoffs 3437.
- Task Verification Failures (21.3%): Critical flaws in quality control mechanisms 37. These failures occur when judge-agents accept incorrect outputs due to hallucination, or when workflows are terminated prematurely before all sub-objectives are verified 3437.
The compounding nature of these errors means that without rigorous centralized governance, adding more specialized agents to a workflow often decreases overall system reliability 1038.
Adversarial Vulnerabilities and Systemic Traps
Because agents interact autonomously with external environments, they expose a significantly wider attack surface than isolated generative models 1314. A comprehensive taxonomy by Google DeepMind titled "AI Agent Traps" identified severe vulnerabilities inherent to autonomous operations 13. The study found that malicious instructions hidden within invisible HTML comments or CSS tags successfully hijacked agent reasoning in 86% of tested scenarios 13. Because the agent parses underlying code while human supervisors only observe rendered front-ends, these systemic traps effectively bypass traditional human oversight 13.
Furthermore, attackers can deploy adversarial perturbations to intentionally induce the infinite loop failures detailed previously. Methods such as Greedy Coordinate Gradient (GCG), SCPN, and VIPER manipulate input instructions to disrupt logic sequences 15. By feeding the agent adversarially manipulated environmental demonstrations, an attacker traps the agent in a repetitive command cycle, functionally executing a denial-of-service attack against the system's compute budget 1415.
Technical Mitigations and Reliability Engineering
To transition agents from experimental prototypes to production systems, developers must implement deterministic guardrails, structured orchestration, and intrinsic self-correction protocols.
The Memory Pointer Pattern
The most effective technical mitigation against context window overflow is the Memory Pointer Pattern 911. Instead of permitting external tools to return massive datasets directly into the LLM's active context window, the agent orchestration layer routes the data to an external state database 9. The tool then returns a lightweight reference pointer to the LLM (e.g., a 52-byte string indicating the data's location) 9.
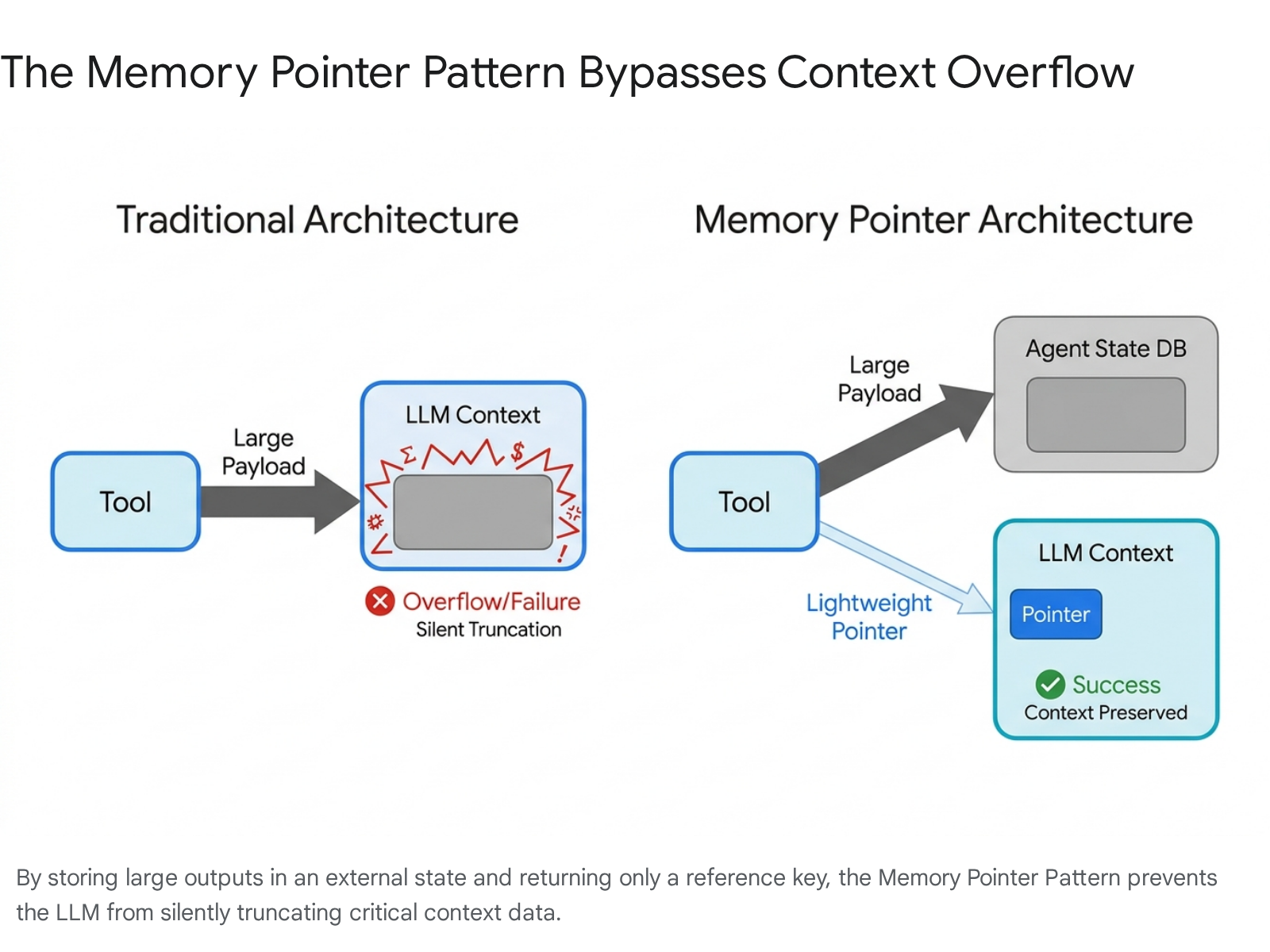
If a subsequent tool requires access to that data, it resolves the pointer externally 911. IBM Research validated this architectural shift on complex scientific workflows, demonstrating that utilizing memory pointers reduced token consumption from over 20.8 million tokens to a mere 1,234 tokens, reducing API costs exponentially while preventing the LLM from silently degrading 911.
Intrinsic Self-Correction Strategies
For an agent to be reliable, it must possess the ability to identify and correct its own logical errors. Historically, employing supervised fine-tuning to teach models self-correction has failed 16. Offline SFT datasets suffer from a distribution shift when deployed in live environments, often causing models to amplify their bias toward their initial, incorrect outputs rather than deeply revising them 16.
To overcome this, Google DeepMind developed Self-Correction via Reinforcement Learning (SCoRe) 1617. SCoRe operates exclusively on self-generated data. During training, the system creates synthetic dialogues where the model outputs an incorrect response, is prompted to correct itself, and subsequently generates a verified answer 1644. Applying a two-stage policy gradient RL process, SCoRe incentivizes the model to learn a robust, generalizable strategy for intrinsic revision 1618.
Extensive testing demonstrates that SCoRe profoundly improves reliability. On the MATH benchmark, models fine-tuned with SCoRe achieved a 15.6% absolute gain in self-correction capability compared to baseline implementations 1617. Crucially, the SCoRe methodology reduced the rate at which models erroneously altered a previously correct answer - a phenomenon known as regression - from 15.8% down to just 1.4% 18.
Execution Orchestration and Guardrails
To prevent infinite loops and task hallucination, reliability engineering dictates the use of hard orchestration constraints. First, tools must be reprogrammed to return explicit terminal states 9. Ambiguous strings are replaced with absolute flags like SUCCESS or FAILED, eliminating the model's capacity to infer that repetitive queries will yield new results 9. Second, execution pipelines employ monitoring hooks, such as "DebounceHooks," which actively scan the execution stack and forcefully block the agent from duplicating tool calls with identical parameters 919.
For complex enterprise pipelines, architectures like Autonomous Data Processing using Meta-Agents (ADP-MA) separate strategic orchestration from ground-level execution 47. Drawing inspiration from database query optimizers, ADP-MA utilizes a persistent set of meta-agents to handle planning, monitoring, and error recovery 47. These meta-agents dynamically spawn ephemeral, sandboxed agents to execute specific functional tasks 47. This strict hierarchy contains execution failures within isolated modules, preventing cascading errors and reducing run-to-run performance variance across massive workflows 4720.
Distinctions from Artificial General Intelligence
The rapid proliferation of agentic frameworks frequently blurs the distinction between highly capable automation and Artificial General Intelligence (AGI) 4950. From an academic and architectural perspective, current autonomous LLM agents are strictly narrow AI systems 4921.
Agents operate within clearly defined boundaries, relying on explicit orchestration logic, predefined toolsets, and human-engineered system prompts 5021. While they can process multimodal data and execute complex routines, they lack the capacity for fluid, cross-domain knowledge transfer 5052. The primary bottleneck for current systems is the "maintenance wall" - an agent's ability to self-improve is fundamentally capped by the speed at which human engineers update its underlying rules, APIs, and environmental constraints 22.
AGI, conversely, represents a theoretical system capable of self-directed learning, continuous environmental modeling, and autonomous self-improvement across entirely novel domains without human intervention 5052. However, researchers are exploring intermediate architectures to bridge this gap. Meta's recent introduction of "hyperagents" attempts to fuse the task-execution agent and the meta-supervisory agent into a single, self-referential entity 22. By enabling the system to continuously rewrite its own problem-solving logic and underlying code base, hyperagents aim to compound capabilities over time across non-coding domains like robotics and dynamic document review 22. Until systems can autonomously escape their predefined operational constraints, current agents represent highly sophisticated, yet definitively narrow, computational tools.