Architecture and Creative Questions in AI Music Generation
Generative Audio Architecture
The transition from symbolic music generation to the synthesis of raw acoustic waveforms represents a fundamental evolution in computational audio. For decades, algorithmic music composition relied on symbolic representations, such as Musical Instrument Digital Interface (MIDI) sequences or piano rolls, which were processed by recurrent neural networks or Long Short-Term Memory architectures 1. While these systems could generate mathematically coherent melodies, they required external virtual instruments or human performers to render the actual sound. Modern artificial intelligence music generation systems bypass this limitation entirely by directly synthesizing complex acoustic signals. This capability relies on an intricate pipeline encompassing extreme data compression, sophisticated latent space representation, and precise cross-modal alignment between natural language prompts and acoustic tokens 234.
Acoustic Compression and Latent Representations
Raw audio waveforms are overwhelmingly dense. A standard audio file sampled at 44.1 kilohertz in stereo contains over eighty-eight thousand individual data points per second. Processing this volume of continuous data directly through self-attention mechanisms in transformer models is computationally unfeasible. To resolve this structural bottleneck, modern generative music models employ neural audio codecs, such as EnCodec, or highly compressed Variational Autoencoders to project the raw waveform into a lower-dimensional, discrete latent space 125.
These neural encoders compress the continuous audio signal into a sequence of discrete acoustic tokens. The encoding process relies heavily on techniques like Residual Vector Quantization, which maintains high perceptual audio quality while keeping file sizes and token sequence lengths manageable 26. The resulting tokens capture essential acoustic properties - such as pitch, timbre, spatial positioning, and rhythm - while discarding imperceptible frequency fluctuations and redundant data 37. By operating exclusively within this compressed latent space, transformers can model long-term musical dependencies and macro-structures spanning several minutes without exceeding memory constraints, ultimately decoding the tokens back into listenable waveforms via a sophisticated vocoder 17.
Text-to-Audio Alignment Mechanisms
Translating text prompts into musical outputs requires the seamless bridging of two vastly different computational modalities: natural language and audio. This bridging is predominantly achieved using an encoder-decoder transformer architecture. Initially, a pretrained large language model, such as BERT, FLAN-T5, or a LLaMA tokenizer, processes the user's text prompt to generate dense text embeddings that capture the semantic intent of the request 4910.
To effectively align these semantic text embeddings with the acoustic tokens, systems employ complex cross-attention mechanisms. Specialized architectures, frequently designed as Query-transformers (Q-formers), act as audio aligners bridging the language model and the audio decoder.
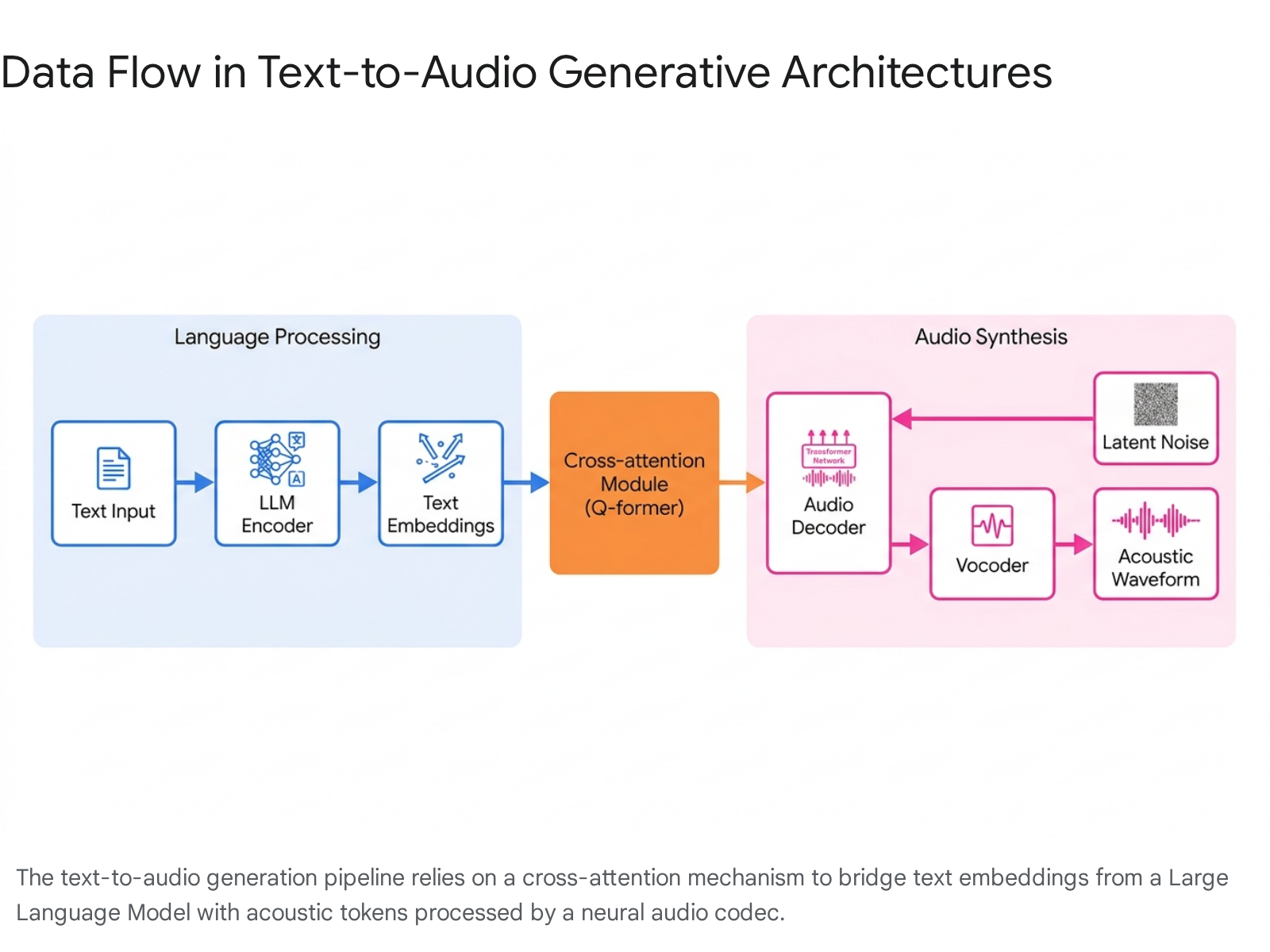
These aligners process the text prompt alongside acoustic feature maps extracted from the audio encoder. Learnable query tokens extract relevant auditory information from these feature maps via cross-attention, effectively resampling variable-length audio embeddings into a fixed number of acoustic embeddings 1011. This bidirectional mapping is what allows the generative model to understand highly specific semantic instructions and map them to corresponding sonic textures and temporal structures 612.
Autoregressive Models versus Latent Diffusion
The generation of the actual acoustic tokens within the latent space is handled primarily by two competing algorithmic paradigms: autoregressive transformers and latent diffusion models.
Autoregressive models, utilized by platforms like Meta's MusicGen and Suno, generate audio sequentially. Similar to how a text-based large language model predicts the next word in a sentence, an autoregressive music model predicts the next acoustic token in a sequence based on the context of all previously generated tokens 26. This sequential approach excels at maintaining long-term structural coherence, ensuring that a track maintains a consistent tempo, recurring melodic themes, and a logical verse-chorus-bridge structure across several minutes 1.
Conversely, latent diffusion models, utilized by systems like Stable Audio Open, begin with a field of random Gaussian noise in the latent space. The model iteratively refines and denoises this space into a structured acoustic representation, guided continuously by the text prompt 2313. Diffusion models are widely praised for producing highly realistic textures, complex sound design elements, and nuanced timbral variations. Historically, diffusion architectures struggled with long-form temporal coherence compared to autoregressive methods, but advancements in transformer-diffusion hybrids have begun to close this gap, enabling the generation of high-fidelity tracks that last nearly five minutes 279.
Memorization and Probabilistic Generation
A critical technical and ethical challenge in training generative music models is the phenomenon of data memorization. In probabilistic generative models, memorization occurs when the algorithm exhibits an artificially high probability of generating a sample that closely resembles a specific piece of training data . This differs fundamentally from mode collapse, where a model only generates a narrow variety of outputs, or simple overfitting.
Research indicates that models tend to memorize specific training observations in regions of the input space where the algorithm has not encountered sufficient diverse data to enable true generalization. Highly memorized audio samples are often atypical edge cases that are essential for the model to properly map a specific, niche musical genre or unique vocal technique . The capacity for probabilistic generative models to inadvertently reproduce copyrighted melodies or distinct artist timbres poses massive legal risks and complicates the evaluation of whether a model is genuinely creating novel compositions or merely retrieving compressed training data 6.
Commercial Generation Platforms
As of early 2026, the commercial landscape for artificial intelligence music generation is heavily consolidated, dominated by systems capable of producing end-to-end songs complete with instrumentation, coherent lyrics, and human-like vocals. While the underlying text-to-audio architectures share common foundational principles, the leading platforms - Suno and Udio - diverge significantly in their engineering priorities, output characteristics, and integration capabilities for professional users 15817.
Output Characteristics and Structural Limits
Suno has aggressively positioned itself as the consumer and semi-professional market leader, reaching a valuation of over two billion dollars and generating hundreds of millions in annualized recurring revenue by early 2026 179. Suno's primary engineering strength lies in its vocal generation and genre versatility. The platform produces highly naturalistic vocals that capture subtle human imperfections, including breathiness, vocal cracks, and dynamic emotional shifts, rendering it particularly effective for pop, rock, country, and vocal-centric tracks 810. Structurally, Suno permits the generation of tracks up to four minutes in length in a single pass, which can be extended to eight minutes. This long-context capability allows users to generate a complete, structurally sound pop song with distinct verses, choruses, and bridges immediately 158.
Udio favors peak audio fidelity and complex harmonic accuracy over long-form structural generation. Udio outputs are generated at a 48kHz sample rate, yielding superior instrumental separation and a pristine mix that mitigates the frequency bleed or "muddiness" frequently observed in Suno's denser multi-instrument arrangements 1710. Udio demonstrates superior adherence to advanced music theory prompts, reliably generating specific extended jazz voicings (such as minor seventh to major seventh progressions) rather than simplifying complex prompts into basic triads 10. However, Udio imposes a much stricter generation cap, limiting initial outputs to two minutes per pass, which requires users to manually extend and stitch together sections to build a full track 15.
Ecosystem Integration and Workflow Restrictions
The utility of these platforms extends far beyond raw audio quality into how effectively they integrate into professional production workflows. Suno has expanded its feature set to resemble an AI-native Digital Audio Workstation. The platform includes native stem extraction, MIDI export functionality, and multi-track editing, allowing users to granularly manipulate outputs within the browser environment 1517.
Udio's workflow was initially heavily favored by traditional electronic and hip-hop producers due to its high-fidelity stem exports, which allowed producers to extract clean vocal or drum tracks for external use in professional software 17. However, following a major licensing settlement with Universal Music Group in late 2025, Udio temporarily disabled audio, video, and stem downloads across all its commercial tiers 20. This action essentially transformed Udio into a closed, walled-garden ecosystem where users could prompt and iterate on licensed catalog data but could not extract the raw WAV files for external publishing or professional integration, significantly altering its value proposition for working producers 20.
Commercial Platform Feature Comparison
The following table summarizes the operational and technical differences between the leading platforms, highlighting the trade-offs between audio quality, structural generation limits, and commercial licensing viability.
| Feature / Metric | Suno (v5) | Udio (v2) | ElevenLabs Music | Stable Audio 2.0 |
|---|---|---|---|---|
| Primary Engineering Strength | Vocal emotion, long structures, genre versatility 810 | Pristine audio fidelity, instrument separation, advanced harmony 10 | Clean commercial licensing, safe for enterprise/agency use 1112 | Sound design, audio-to-audio remixing, instrumental beds 217 |
| Maximum Initial Track Length | Up to 4 minutes (extendable to 8+ minutes) 158 | 2 minutes (extendable up to 15 minutes) 158 | Approximately 3 minutes 15 | Up to 3 minutes 2 |
| Vocal Realism | High (captures breath, cracks, dynamic emotional shifts) 10 | Moderate-High (polished but can sound mechanical/MIDI-like) 10 | Moderate (clean but lacks complex emotional variance) 11 | Low (primarily focused on instrumental/electronic generation) 2 |
| Stem Export Capability | Native, integrated directly via Suno Studio 1517 | High quality, but heavily restricted/disabled during 2026 licensing transition | Not natively supported for isolated stems 15 | Not natively supported 15 |
| Commercial Rights Status | Granted to Pro users (subject to ongoing Sony litigation risks) 817 | Granted to Pro users (subject to UMG walled-garden download restrictions) 820 | Fully cleared commercial licensing from day one 1112 | Fully cleared (trained entirely on licensed AudioSparx data) 217 |
Creative Integration and Production Workflows
The introduction of end-to-end generative models has fundamentally disrupted traditional music production pipelines. While traditional composition demands deep knowledge of music theory, digital audio workstations, hardware synthesizers, extensive acoustic recording, and manual mixing, AI-assisted workflows compress this entire timeline. These new pipelines replace manual instrumentation and engineering with iterative textual prompting, audio curation, and targeted arrangement logic 241326.
Traditional versus AI Production Pipelines
The differences in workflow architecture highlight a shift from manual asset creation to algorithmic curation. The table below outlines how specific production stages have evolved.
| Production Stage | Traditional Workflow | End-to-End AI Workflow |
|---|---|---|
| Pre-Production | Human concept ideation, manual key selection, writing sheet music or MIDI 27. | Defining genre, tempo, key, emotional arc, and negative prompts ("no-go" sounds) via text 1228. |
| Composition & Arrangement | Manually recording or programming drums, bass, chords, and melodies track-by-track 2413. | Generating full structural layouts instantly, building energy lanes, and utilizing "smart stem swaps" to iterate 2428. |
| Vocal Production | Hiring session singers, recording multiple takes, manual comping, timing correction, and pitch tuning 1328. | Prompting lyric delivery, generating vocal stems, and relying on AI for inherent timing and pitch accuracy 2829. |
| Mixing & Polish | Manual gain staging, equalization, compression, space creation, and automation 1328. | Algorithmic mixing based on statistical models, followed by minor volume or filter automation passes 2829. |
| Mastering | Analyzing translation, targeting loudness, applying limiters, and dithering 2830. | Automated target loudness matching and algorithmic balancing (frequently via hybrid AI mastering tools) 2830. |
Prompt Engineering and Audio-In Bridging
Communication with a generative audio model requires a specialized syntax. Music producers are developing "prompt engineering" as a core competency, learning to translate abstract auditory concepts into precise textual descriptors 1214. Effective prompting requires defining multiple layers of musical intent simultaneously. A prompt must establish the overarching genre and mood, specify the desired textures and instrumentation, direct the arrangement flow with structural cues, and describe the psychological or emotional triggers the track should evoke 1214.
Beyond text, the development of "audio-in prompting" allows users to supply a few seconds of raw audio - such as a hummed vocal melody, a rhythmic beatbox loop, or a simple guitar chord progression - which the model then extends, harmonizes, or fully orchestrates 2291533. This cross-modal fusion works by encoding both the audio input and the text prompt into a joint latent space, preserving the producer's original melodic contour while generating the desired instrumental texture specified by the text 534. Advanced implementations, such as Hybrid Text-to-Music Transformers, can extract melodic descriptors directly from the text prompt to provide a structural scaffold, ensuring the generated audio adheres to strict musical rules without requiring formal musical input from the user 16.
Producer-Directed versus Fully Prompted Generation
The professional integration of these tools has bifurcated into two distinct operational philosophies: "fully prompted" and "producer-directed" workflows 17.
In a fully prompted workflow, the artificial intelligence leads the creative direction. The user provides a text prompt, and the system generates the entire composition, arrangement, and mix autonomously. This approach is highly efficient for rapid prototyping, generating mood boards, creating reference vibes for a brief, or supplying background tracks for content creators 1737. However, professional artists note that this method surrenders the foundational identity and emotional trajectory of the song to the algorithm, resulting in tracks that, while technically proficient, often lack deep emotional resonance or a cohesive point of view 1317.
In a producer-directed workflow, the human artist maintains strict control over the composition's core identity. The producer writes the underlying chord progression, records a seed vocal or rhythm, and imports it into the AI system. The artificial intelligence acts as an advanced studio assistant, generating alternate hook lines, swapping out specific stems, or filling out dense orchestral arrangements 281737. This hybrid approach ensures the final track retains the unique acoustic signature and intent of the producer, while leveraging the speed and scalability of the machine learning model to execute complex production tasks 291718.
Evaluation of Synthetic Mixing and Mastering
As generative tools increasingly encroach on the final stages of audio production, audio engineers are continuously comparing AI-generated mixes and masters against human-engineered tracks. Blind A/B testing reveals that AI mastering algorithms excel at rapidly matching commercial loudness targets and executing broad frequency balancing 30.
However, AI instruments and synthetic mixes often lack the natural acoustic variance, room reflections, and dynamic expressiveness found in actual human performances 18. Traditional recordings capture complex harmonic distortions from microphones, preamps, and physical spaces that AI tools must artificially simulate 2918. To bridge this critical gap, producers frequently process AI-generated stems through analog saturation plugins, apply subtle harmonic enhancement, and utilize varying compression attack and release times to introduce the organic imperfections necessary to make the track feel physically real 29. Furthermore, subjective evaluations indicate that while objective reference-based metrics (such as the Fréchet Audio Distance or Kernel Audio Distance) can assess baseline audio fidelity, they frequently fail to correlate with human aesthetic preferences, highlighting the ongoing necessity of human judgment in achieving true emotional depth 1339.
Cultural and Industry Impact
The rapid commercialization of generative artificial intelligence has triggered widespread adoption - and significant friction - across the global music industry. The implications are most acutely visible in highly industrialized and centralized music markets, notably the South Korean K-Pop ecosystem, which has aggressively integrated these tools at an enterprise level.
Commercial Deployment in the K-Pop Ecosystem
Major South Korean entertainment agencies have embraced artificial intelligence as a core component of both artist development and music production, viewing it as essential to maintaining the intense output required by the global market. Hybe, the agency behind global phenomenon BTS, acquired the AI audio startup Supertone in 2023, signaling a strategic shift toward becoming an "Enter-Tech" company that fuses entertainment and technology 19. Hybe has utilized Supertone's voice-cloning technology to launch Syndi8, a virtual pop group whose vocals are entirely AI-generated. The group's narrative is explicitly built around artificial intelligence, operating within a fictional universe where voices are generated entities and sources of power 1920.
Other major agencies, such as SM Entertainment, have integrated AI narratively through metaverse avatars (such as the group Aespa), while JYP Entertainment has initiated large-scale recruitment dedicated to developing AI artists 1920. Industry executives argue that technological innovation is an existential necessity to overcome the physical limitations of human artists and to sustain the extreme productivity demands of the contemporary music industry 19.
Audience Perception and Authenticity Concerns
Despite enthusiastic corporate adoption, the integration of AI voices has provoked severe audience backlash. K-Pop fan culture is heavily predicated on parasocial relationships, where the perceived effort, authenticity, and physical presence of the idol are the primary drivers of value and engagement 21.
Studies investigating fan reactions to AI voice cloning - such as "AI Private Call" services that simulate personal phone conversations using an idol's synthesized voice - reveal that fans experience a profound sense of deception 21. The substitution of a genuine human voice with a machine-generated approximation blurs the authenticity of the emotional connection, conflicting directly with the socio-cultural expectations of the fandom 21. Furthermore, analysis of social media responses to AI-altered tracks indicates that fans who are aware a song utilizes voice-changing AI generally have a measurably more negative perception of the music, demonstrating that the knowledge of artificial intervention actively degrades the listener's appreciation of the art 22.
Diversity and Dataset Representation
A secondary, yet deeply systemic, cultural concern involves the homogenization of global music. The performance, versatility, and stylistic output of generative AI systems are intrinsically linked to the composition of their training data. An extensive analysis of over one million hours of audio datasets used in AI music generation research reveals a stark geographical and cultural imbalance: approximately eighty-six percent of the total dataset hours consist of music originating from the Global North 44.
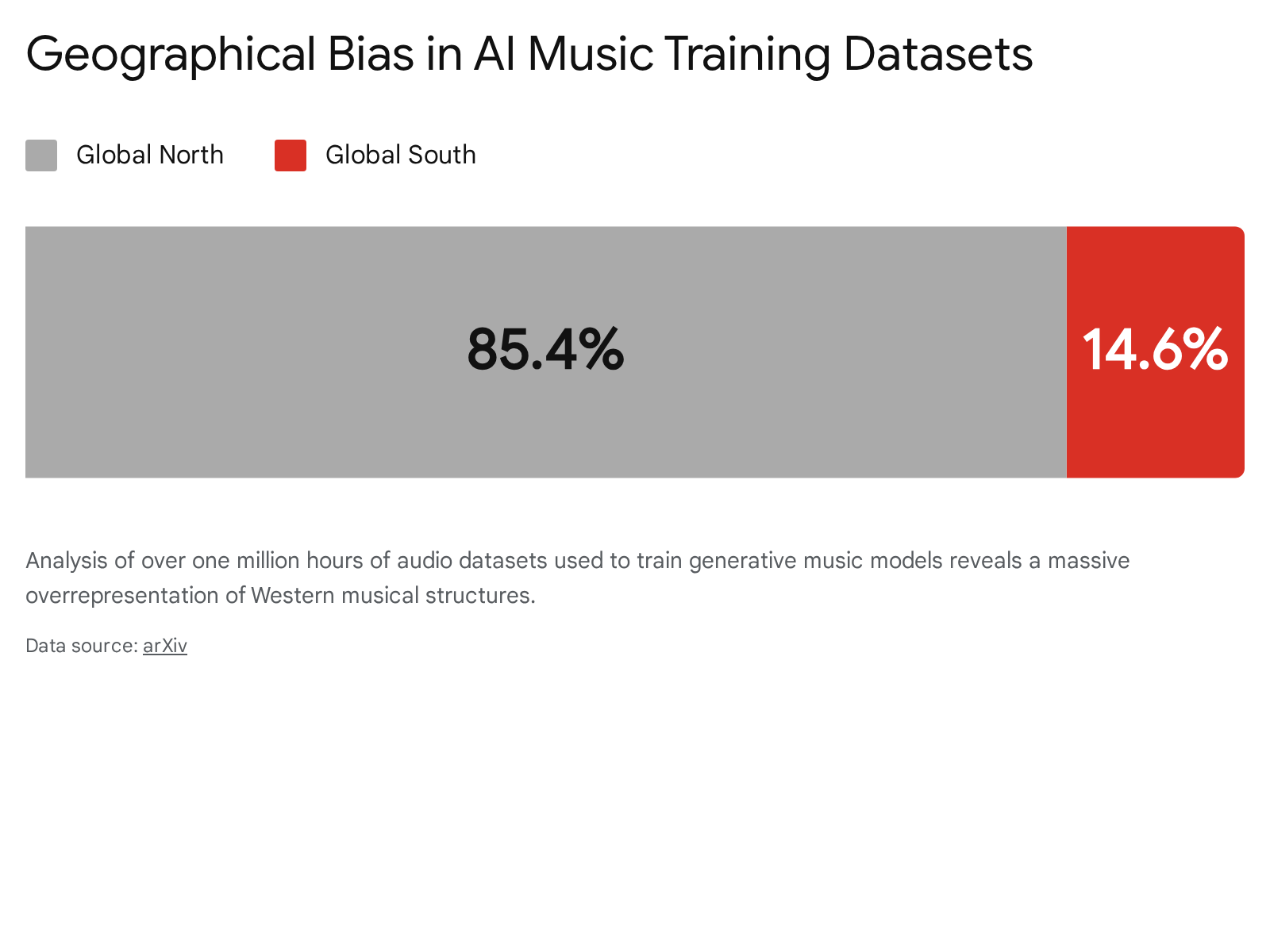
Conversely, musical genres indigenous to the Global South account for less than fifteen percent of the available training data 44. Furthermore, the majority of research concentrates on symbolic music generation, a method that inherently fails to capture the complex microtonal structures, intricate rhythmic syncopations, and cultural nuances present in South Asian, Middle Eastern, and African music 44. Because generative models produce outputs based entirely on the statistical distribution of their training sets, this massive underrepresentation means current AI systems struggle to accurately replicate non-Western music. As AI becomes a ubiquitous tool for global music creation, this underlying dataset bias threatens to standardize and flatten global music production around Western harmonic and rhythmic norms 44.
Legal and Regulatory Frameworks
The ingestion of millions of hours of copyrighted audio to train these highly advanced generative models has precipitated a global legal and regulatory crisis. The core dispute across all jurisdictions centers on whether training an artificial intelligence on copyrighted material constitutes massive copyright infringement or if it falls under legal exceptions such as "fair use" or "text and data mining."
Copyright Litigation and Major Label Settlements
In the summer of 2024, the Recording Industry Association of America, acting on behalf of major record labels including Universal Music Group, Sony Music Entertainment, and Warner Music Group, filed coordinated, high-stakes copyright infringement lawsuits against both Suno and Udio. The labels alleged mass, unauthorized scraping of copyrighted sound recordings, arguing that the AI systems were trained on protected works to develop models capable of generating directly competing compositions 114523.
By late 2025, the legal landscape began to fracture as AI companies sought to transition from unauthorized web scraping to licensed models to ensure their long-term viability. Warner Music Group reached a landmark settlement with Suno in November 2025, establishing a partnership to develop new, fully licensed models while Suno agreed to deprecate models trained on unlicensed data 92047. Universal Music Group reached a similar settlement with Udio in October 2025, resulting in the temporary walled-garden restrictions on Udio's platform 2047. Concurrently, startups like Klay Vision emerged, securing licensing deals from all three major labels from their inception to avoid litigation entirely 20.
However, as of early 2026, Sony Music remains a steadfast holdout, continuing active litigation against both platforms. The forthcoming rulings in the Sony cases are highly anticipated, as they are expected to set a pivotal legal precedent regarding the viability of the "fair use" defense for generative audio training in the United States 172047. In the interim, independent artists have also filed class-action lawsuits seeking compensation for the use of their master recordings in training pools, expanding the scope of the legal battle beyond the major labels 47. Furthermore, precedent established in related cases, such as Bartz v. Anthropic, suggests that courts may rule that training AI on copyrighted works qualifies as fair use only if the works were legally acquired, rather than pirated, adding another layer of complexity to data sourcing 24.
Global Regulatory Divergence
As litigation unfolds in the United States, international governments are establishing divergent statutory frameworks to govern AI training data, reflecting vastly different national priorities regarding technological innovation versus creator protection.
The European Union Artificial Intelligence Act The EU AI Act represents the most stringent and comprehensive regulatory approach globally. Enforced in phases leading into 2026, the Act mandates severe transparency and accountability rules for providers of general-purpose AI models. Crucially, AI companies operating in the EU must publish a detailed public summary of their training data utilizing a mandatory transparency template provided by the European Commission 4925. Developers are legally required to respect copyright reservations (opt-outs) invoked by rightsholders and must clearly label or watermark AI-generated outputs 4926. While the template attempts to balance transparency with the protection of trade secrets by allowing generalized descriptions of private datasets, it fundamentally outlaws the unmitigated, unlicensed scraping of web content in Europe 27.
Japan's Permissive Copyright Environment In stark contrast, Japan has historically maintained one of the world's most permissive environments for artificial intelligence development. An amendment to Japan's Copyright Act (Article 30-4) explicitly permits both commercial and non-commercial entities to use copyrighted works for data analysis and machine learning without obtaining prior permission from copyright holders 532829. The legal rationale relies on the distinction that machine learning constitutes "information analysis" rather than human "enjoyment" of the copyrighted work 53.
However, facing intense pushback from the Japan Newspaper Publishers & Editors Association and other cultural industries warning of economic unsustainability, the Japanese government enacted the AI Promotion Act in May 2025. While primarily a pro-innovation statute aimed at boosting research and development, it has signaled an impending regulatory shift toward stricter intellectual property enforcement and the potential introduction of licensing frameworks expected to materialize later in 2026 283031.
South Korea's AI Basic Act South Korea is navigating a volatile middle ground. The nation implemented its AI Basic Act in January 2026, which established verification procedures allowing rights holders to legally check if their specific works were utilized as training data 5832. However, the government concurrently introduced "Action Plan No. 32," an initiative aimed at creating explicit copyright exceptions for text and data mining to protect domestic AI developers from legal risk and foster international competitiveness 6033. This action sparked a massive backlash from a broad coalition of Korean creator organizations, who argued the plan prioritized tech companies' legal certainty over creators' private property rights, threatening the economic foundation of the country's massive cultural export sector 6033.
Comparison of International Copyright Frameworks
The global divergence in AI regulation creates a complex compliance environment for generative music platforms. The table below summarizes the key legal postures across major jurisdictions in early 2026.
| Jurisdiction | Primary Legislation | AI Training Data Policy | Creator Compensation and Opt-Out Rights |
|---|---|---|---|
| European Union | EU AI Act (Regulation 2024/1689) 62 | Strict compliance required. Mandatory public disclosure of training data sources via standardized templates 4927. | Rightsholders can legally reserve rights (opt-out); unauthorized scraping of protected web content is prohibited 49. |
| Japan | Copyright Act (Article 30-4); AI Promotion Act (2025) 2830 | Explicitly permitted for commercial and non-commercial machine learning under the "information analysis" exception 5328. | Currently none required, though intense creator pushback is forcing policy re-evaluations and potential licensing rules in 2026 2831. |
| South Korea | AI Basic Act (January 2026) 3234 | Government attempting to introduce text and data mining exceptions (Action Plan 32) to reduce developer risk 6033. | AI Act provides a mechanism to verify data use, but creators are aggressively fighting the proposed data mining exceptions 5833. |
| United States | Reliance on existing Copyright Law frameworks 2428 | Heavily litigated; AI companies argue "Fair Use," while rights holders argue mass infringement 2435. | Decided via courts and private settlements (e.g., Warner/Suno, Universal/Udio); no universal statutory opt-out exists 2047. |
Conclusion
The architecture of artificial intelligence music generation has transcended basic novelty, evolving into a highly sophisticated ecosystem of neural codecs, cross-attention mechanisms, and latent diffusion models capable of producing studio-quality audio directly from natural language. Platforms like Suno and Udio demonstrate the immense technical viability of these systems, offering unprecedented speed and structural versatility. However, the true complexity of AI music generation no longer lies solely in its underlying code; it resides in the friction of its real-world application.
The transition from traditional, human-centric production pipelines to AI-assisted workflows forces a critical re-evaluation of authorship, creativity, and authenticity. As K-Pop fandoms have demonstrated, listeners maintain a deep psychological attachment to the human effort behind music - a parasocial connection that synthetic generation struggles to replicate without inducing feelings of deception. Furthermore, as the legal landscape of 2026 clearly illustrates, the foundational data structures of these models are built upon fiercely contested ground. The divergent regulatory approaches of the European Union, Japan, and South Korea, coupled with massive industry settlements and ongoing litigation in the United States, suggest that the future of artificial intelligence in music will be dictated just as much by copyright law and dataset licensing as by advancements in transformer architecture. The technology has arrived, but the industry is still negotiating the terms of its existence.