AI Text Watermarking and Detection
Introduction
The rapid advancement of large language models has fundamentally altered the digital information ecosystem, allowing machines to generate highly sophisticated, contextually accurate, and fluent text at an unprecedented scale. As the underlying architectures of these models optimize for linguistic coherence and semantic relevance, their outputs have become perceptually indistinguishable from authentic human writing 12. This structural evolution presents substantial societal and technological challenges, ranging from the proliferation of automated misinformation campaigns and identity fraud to systemic violations of academic integrity and the unauthorized use of synthetic data in subsequent model training pipelines 234. Between 2023 and 2025 alone, tracking metrics indicated a global surge in deepfake and synthetic media incidents from approximately 500,000 cases to over eight million 5.
To address these vulnerabilities, the artificial intelligence research community and major commercial model providers have invested heavily in text provenance and detection mechanisms. The strategies for identifying machine-generated text generally divide into two distinct operational paradigms: post-hoc detection and generation-time statistical watermarking. Post-hoc detection systems operate independently of the text generation process, utilizing secondary classifier algorithms to scrutinize text for stylistic regularities or statistical artifacts characteristic of machine generation 56. Conversely, generation-time statistical watermarking is an active intervention. It modifies the underlying autoregressive decoding process of the language model itself, subtly manipulating vocabulary probability distributions to embed a hidden, cryptographically verifiable signal directly into the output sequence 87.
While post-hoc detection initially dominated the market due to its ease of implementation, severe structural flaws - most notably its fragility against minor editing and its systemic bias against non-native language speakers - have forced a shift in industry consensus toward statistical watermarking 6811. However, embedding watermarks in text presents profound mathematical and engineering challenges that do not exist in continuous media domains like audio or visual generation 1213. Because text operates as a discrete, low-entropy medium, modifying even a single token can drastically alter grammatical structures or semantic meaning 1213. This report exhaustively details the algorithmic mechanics of statistical text watermarking, analyzes the vulnerabilities of these systems against adversarial tampering and open-weight model extraction, contrasts probabilistic watermarking with cryptographic metadata standards, and examines the complex commercial realities governing current industry deployments.
Post-Hoc Detection Systems and Algorithmic Bias
Post-hoc text detection aims to classify content after it has been produced, requiring no direct access to the model that generated it or the computational parameters used during decoding 46. These systems rely on the fundamental assumption that inherent stylistic and statistical deviations exist between human cognition and machine-generated probabilities 4.
Detection Mechanics and Vulnerabilities
Post-hoc classifiers typically analyze text utilizing metrics such as log probability curvature, divergent n-gram analysis, and intrinsic dimension estimation 46. The most heavily weighted metric in commercial post-hoc detection is "perplexity," which measures the degree to which a language model is "surprised" by a given sequence of words 58. Because language models are trained to maximize likelihood, their natural outputs tend to follow highly predictable probability pathways, resulting in low perplexity scores 58. Human writers, by contrast, frequently utilize unexpected vocabulary combinations, varied sentence lengths, and idiosyncratic grammar, yielding higher perplexity scores 5.
However, the efficacy of post-hoc detection is rapidly deteriorating. As foundational models grow increasingly sophisticated, the statistical gap between machine and human text continues to narrow 4. Modern models deliberately incorporate sampling techniques like temperature scaling and Top-P (nucleus) sampling to inject randomness and variability into their outputs, thereby artificially raising perplexity and neutralizing the primary signal relied upon by detectors 9. Furthermore, post-hoc detectors demonstrate extreme fragility to basic adversarial interventions. Users can easily bypass these classifiers through "prompt engineering" - explicitly instructing the model to adopt higher linguistic diversity, emulate specific human imperfections, or utilize varied syntactic structures 5. Consequently, studies have demonstrated that post-hoc detection methods are neither accurate nor reliable at scale, suffering from high false positive rates and an inability to adapt to iterative model updates without constant retraining 46.
Structural Bias Against Non-Native Writers
The most critical operational failure of post-hoc detection is its systemic bias against non-native English speakers. Because these classifiers conflate low perplexity with machine generation, they inherently penalize human writers who utilize constrained linguistic expressions 810. Non-native speakers naturally exhibit lower lexical richness, lower lexical diversity, and more rigid syntactic and grammatical complexity compared to native speakers 58.
A comprehensive 2023 study conducted by researchers at Stanford University quantified the severity of this bias. The researchers evaluated the performance of seven prominent commercial AI detectors using 91 essays sourced from the Test of English as a Foreign Language (TOEFL) dataset 58. The empirical results demonstrated catastrophic failure rates: the detectors misclassified 61.22% of the TOEFL essays written by non-native students as AI-generated 5. Furthermore, all seven AI detectors unanimously misclassified 19% of the non-native essays, while an overwhelming 97% of the essays were falsely flagged by at least one detector 510. By contrast, the same detectors demonstrated near-perfect accuracy when evaluating essays written by native-born eighth-grade students, who inherently utilize higher linguistic variability 58.
This disparity highlights a severe algorithmic inequity. When controlling for average review ratings in academic abstracts, texts authored by researchers from non-native English-speaking countries still exhibited significantly lower perplexity scores than their native-speaking peers, leading directly to higher false positive rates 816. Meta-analyses of plagiarism and AI detection tools across multiple global datasets further corroborate this, showing error rates up to 30% higher for non-native writers 16. In academic and professional evaluation environments, reliance on post-hoc detection tools risks exacerbating global inequalities and falsely penalizing diverse voices through unjust accusations of academic dishonesty 81016.
Statistical Watermarking Mechanics
To overcome the inherent limitations and biases of post-hoc detection, the computational linguistics community developed generation-time statistical watermarking 1117. Rather than passively observing text for artifacts, statistical watermarking actively modifies the stochastic sampling process of the language model, embedding a verifiable signal that persists regardless of the output's overall perplexity or style 18.
Token Partitioning and Logit Biasing
The foundational architecture for modern text watermarking relies on the token-probability shifting methodology, most prominently defined by the KGW (Kirchenbauer et al.) algorithm 11112. Large language models autoregressively generate text by calculating a probability distribution across their entire vocabulary for each successive token. The KGW framework intervenes immediately before the token is sampled 1213.
At each decoding step, the algorithm employs a pseudorandom function - seeded by a combination of a secret cryptographic key and the sequence of preceding context tokens - to partition the model's vocabulary into two disjoint subsets: a "Green List" (preferred tokens) and a "Red List" (suppressed tokens) 81322. The size of the Green List relative to the total vocabulary is determined by a splitting ratio parameter, commonly denoted as gamma ($\gamma$) 22.
Once the vocabulary is partitioned, the algorithm applies a fixed positive scalar value, known as the watermark logit or bias ($\delta$), to the pre-softmax logits of all tokens residing in the Green List 2214. When the softmax function subsequently normalizes these logits into a probability distribution, the likelihood of selecting a token from the Green List is mathematically inflated 2415.
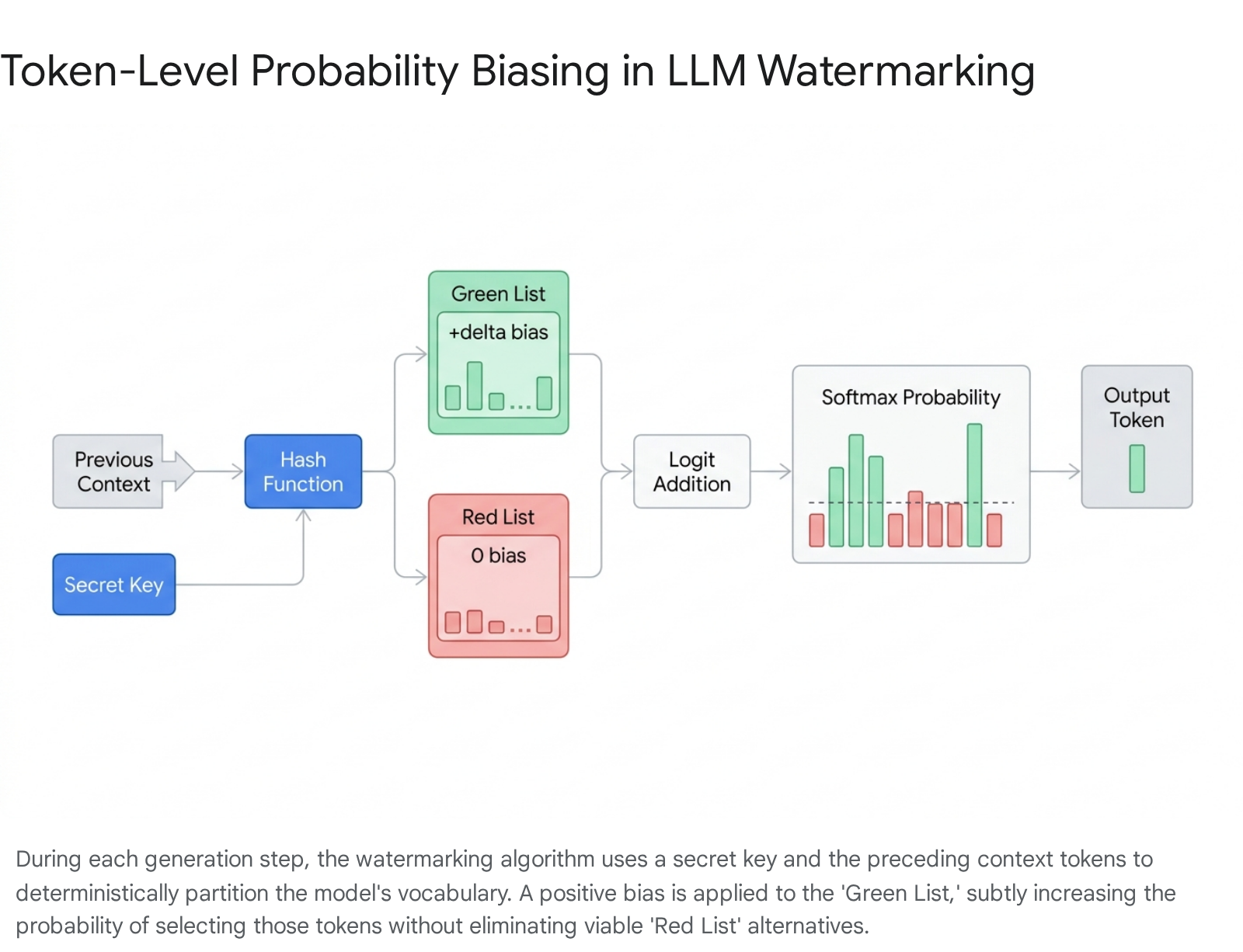
The language model still retains the capacity to select a Red List token if no Green List token is contextually appropriate - for instance, when generating factual data or rigid code where low-entropy options dominate the logits - thereby preventing catastrophic hallucinations or grammatical collapse 71124.
Hypothesis Testing and Detectability
The fundamental strength of statistical watermarking lies in its capacity for formal hypothesis testing. A detector algorithm, possessing the identical secret cryptographic key used during generation, analyzes a suspect text by reconstructing the Green and Red List partitions for every token position based on the preceding context 2416.
The detector then counts the total occurrences of Green List tokens. Because human-authored text is generated independently of the cryptographic key, the occurrence of Green List tokens in natural text will converge on the splitting ratio (e.g., 50% if the vocabulary is split equally) 1227. Conversely, watermarked text will exhibit a disproportionate frequency of Green List tokens. Detection is formalized via a one-proportion z-test 1117. The resulting z-score quantifies the statistical divergence from the natural baseline, allowing the detector to calculate a precise p-value 1215. If the z-score exceeds a critical threshold, the null hypothesis - that the text is human-written - is rejected with extreme mathematical confidence, achieving near-zero false positive rates on sufficient sample lengths 172417.
Distortion-Free Watermarking Architectures
While the KGW logit-biasing paradigm successfully embeds traceability, it is classified as a "distortionary" watermark. By artificially inflating the probabilities of arbitrary Green List tokens, the algorithm inherently shifts the marginal output distribution of the language model 729. Although careful calibration of the bias parameter minimizes visible degradation, distortionary algorithms inevitably incur slight penalties in text perplexity and overall fluency, which can compound over long generations or in highly constrained technical domains like code generation 1129.
To circumvent this degradation, the field has advanced toward "distortion-free" watermarking schemes. These algorithms guarantee that, in expectation over all possible secret keys, the marginal distribution of the watermarked text perfectly matches the original distribution of the unwatermarked language model 729.
The Gumbel-Max Approach
One prominent distortion-free architecture leverages the Gumbel-max trick, conceptualized by researcher Scott Aaronson 718. Standard autoregressive generation can be executed by adding independent Gumbel-distributed noise to the pre-softmax log-probabilities of all vocabulary tokens, then greedily selecting the token with the maximum resulting value 1831.
In the Gumbel-max watermarking framework, the random Gumbel noise is replaced with pseudorandom noise seeded deterministically by the secret key and the preceding context tokens 31. Because the injected noise perfectly mimics natural Gumbel variables from the perspective of an observer lacking the key, the final token selection preserves the exact mathematical distribution of the base model 718. During detection, the algorithm recalculates the key-derived noise values for the observed tokens; watermarked text will exhibit a severe statistical skew toward maximal noise values, enabling definitive identification 18.
Tournament Sampling and SynthID-Text
An alternative distortion-free methodology, termed "Tournament Sampling," was introduced by Google DeepMind within its SynthID-Text architecture and published in Nature in late 2024 719. Rather than relying on static vocabulary lists or directly injecting noise into logits, Tournament Sampling structures token selection as a multi-layer elimination bracket 719.
At each decoding step, the model draws $2^m$ candidate tokens from its unmodified baseline distribution 7. The algorithm then executes $m$ successive layers of binary tournaments. A pseudorandom $g$-function, securely derived from the cryptographic key and the preceding context tokens, calculates an alignment score for every token pairing 719. In each round, the token with the higher $g$-value advances, systematically eliminating half the candidates until a single victor remains 7.
Because the initial candidates are drawn directly from the base model, and the tournament solely re-ranks them based on the hidden $g$-function, the model's text quality remains theoretically pristine. Empirical testing across 20 million responses within Google's Gemini models demonstrated that Tournament Sampling yields no statistically significant degradation in human-rated text quality or perplexity 727. Furthermore, the algorithm integrates natively with speculative decoding, ensuring computational efficiency necessary for hyperscale production environments 720.
Performance Evaluation and Standardization Metrics
The deployment viability of any text watermarking algorithm is governed by a rigorous trilateral trade-off between detectability, robustness against tampering, and impact on text quality 721. Optimizing a model for high resilience against attacks often necessitates more aggressive probability biasing, which inversely degrades generation fluency 1521.
Statistical Evaluation Parameters
Watermarking algorithms are evaluated using standard classification metrics derived from hypothesis testing 1717. The True Positive Rate (TPR) denotes the frequency of successful watermark identification, while the False Positive Rate (FPR) denotes the critical error of misidentifying human text as machine-generated 1817. Because the reputational and legal consequences of false positives are severe, operational thresholds demand an FPR strictly bounded below 1%, and frequently targeting less than $10^{-5}$ 722. Global detection capabilities are measured using the Area Under the Receiver Operating Characteristic Curve (AUC), which maps the trade-off between sensitivity and specificity across varying threshold adjustments 1723.
The MarkLLM Evaluation Toolkit
The rapid proliferation of competing watermarking algorithms created deep fragmentation in evaluation methodologies. To standardize comparative analysis, researchers from multiple institutions developed MarkLLM, an open-source evaluation toolkit that consolidates implementations across both the KGW-based probability-shifting families and the Christ-based distortion-free families 2137.
MarkLLM executes automated pipelines to assess algorithms against standardized benchmarks such as the C4 dataset for general prose, WMT16 for translation, and HumanEval for code generation 3724. The toolkit assesses the three primary operational pillars using twelve distinct analytical tools, ranging from dynamic threshold calculators for detectability to WordNet and DIPPER integrations for simulating real-world document tampering 2425.
| Evaluation Domain | Evaluated Metrics and Analytical Methods | Primary Purpose |
|---|---|---|
| Detectability | True Positive Rate (TPR), False Positive Rate (FPR), Area Under ROC Curve (AUC), F1 Score, Z-score analysis. | Determines the statistical reliability of the watermark and its baseline sample efficiency on raw text. |
| Text Quality | Perplexity (PPL), Log Diversity, BLEU scores, Pass@1 (for code), GPT-4 discriminator judgments. | Quantifies the distortionary impact of the watermark on linguistic fluency, factual accuracy, and task-specific competence. |
| Robustness | Word-level substitution (WordNet), document-level paraphrasing (DIPPER), cross-lingual translation, copy-paste truncation. | Assesses the fragility of the watermark sequence when subjected to adversarial evasion tactics or incidental human editing. |
Adversarial Vulnerabilities in Text Watermarking
Despite robust mathematical foundations, text watermarking faces severe operational vulnerabilities in real-world environments. Because text is discrete, modifications that preserve semantic meaning can systematically disrupt the cryptographic sequence required for successful detection.
Paraphrasing and Reverse-Engineering Attacks
The most acute threat to token-biasing watermarks is adversarial paraphrasing. When an algorithm relies on the exact sequence of preceding tokens to hash the subsequent Green List, altering or deleting a single word disrupts the context window, misaligning the detector for all subsequent tokens and destroying the statistical signal 1226.
Sophisticated attacks leverage the predictable nature of static watermarking architectures. Research published at EMNLP 2024 demonstrated that watermarks relying on fixed or semantically invariant Green Lists are trivial to reverse-engineer 122. By querying a black-box watermarked model to generate approximately 200,000 tokens, adversaries can execute frequency analyses comparing the output distributions against baseline human corpora (such as OpenWebText) 2227. This allows attackers to map the specific tokens assigned to the hidden Green List with an F1 score exceeding 0.8 122.
Once the Green List is mapped, attackers integrate this knowledge into automated paraphrasing models like DIPPER, instructing the model to systematically penalize Green List tokens during the rewriting phase 22. Experimental data confirms this technique's devastating efficacy: against robust Unigram and Semantic-Invariant algorithms, targeted paraphrasing attacks collapsed the True Positive Rate (at a 1% FPR) from baseline rates exceeding 93% down to as low as 3.8% or 0.2%, entirely neutralizing detection capabilities while preserving the semantic fluency of the text 22.
Translation and Copy-Paste Vulnerabilities
Even highly resilient, distortion-free algorithms like Google's SynthID-Text suffer under complex transformations. Systematic assessments indicate that translating watermarked text into another language (e.g., from English to Chinese) and back-translating it strips the underlying tournament sampling signal entirely, dropping detection F1 scores to 0.711 and true positive rates to 0.675 - a threshold barely exceeding random guessing 26. Furthermore, text watermarking is heavily dependent on volume; while an image watermark can survive extreme cropping, text watermarks generally require a minimum contiguous horizon of 100 to 200 words to accumulate sufficient statistical divergence from the natural baseline 27. Snippets, short tweets, or fragmented copy-pasted sentences fail to cross the requisite confidence thresholds 12.
| Adversarial Attack Type | Mechanism of Disruption | Impact on Watermark Detectability |
|---|---|---|
| Synonym Substitution | Replaces individual words using tools like WordNet. | Moderate; localized disruption of the hash context window, though the overall signal often survives in long texts. |
| Generative Paraphrasing | Utilizes secondary models (e.g., DIPPER, GPT-4) to rewrite sentence structures while maintaining semantic intent. | Severe; completely desynchronizes the preceding context window and neutralizes basic token-shifting mechanisms. |
| Green-List Deciphering | Extracts token probability biases via 200k black-box queries, then actively suppresses Green List tokens during generation. | Catastrophic; drives TPR below 4% at low FPRs, effectively destroying both static and semantic-invariant architectures. |
| Round-Trip Translation | Translates text through a secondary language boundary and back, stripping syntactic structure. | Severe; destroys discrete token correlations required by algorithms like SynthID-Text, reducing detection to near random chance. |
Semantic-Invariant and Post-Hoc Adaptations
To counter paraphrasing fragility, researchers developed Semantic-Invariant Robust (SIR) watermarking (Liu et al. 2024). Rather than hashing literal token strings, SIR processes preceding tokens through an auxiliary embedding model (such as BERT) to extract a continuous semantic vector, which a secondary watermark network transforms into the required logit biases 2844. Because paraphrasing alters surface syntax but preserves underlying semantics, the semantic embeddings remain stable, preserving the watermark signal 4429. However, this framework demands parallel execution of a secondary embedding model during every autoregressive generation step, introducing computational latency that impedes hyperscale deployment 4429.
Alternatively, researchers have explored post-hoc watermarking applications, wherein a secondary language model rewrites existing unwatermarked text while simultaneously applying generation-time watermarking protocols 1730. This allows organizations to retroactively apply verifiable statistical signatures to large repositories of existing copyrighted documents or sensitive codebases 30. Post-hoc application permits aggressive allocation of computational resources - such as utilizing wide beam search or multi-candidate generation - to optimize the quality-detectability trade-off without the strict latency constraints required by real-time conversational APIs 3047.
Vulnerabilities in Open-Weight Model Ecosystems
While watermarking protocols are highly effective in closed-API environments where the provider maintains strict control over the generation pipeline, the global proliferation of open-weight models introduces an insurmountable structural vulnerability 4849.
When an organization releases the weights of a foundational model, attackers gain unrestricted white-box access to the neural architecture 50. Recent studies presented at the USENIX Security Symposium (2024) have demonstrated that neural network plasticity fundamentally compromises embedded watermarking protocols. Watermarks embedded directly into model weights exist in a highly malleable, high-dimensional parameter space 4831. Adversaries can utilize "Smoothing Attacks," which selectively analyze the relationship between model confidence and watermark detectability, to erase embedded traces across models ranging from 1.3B to 30B parameters without degrading output quality 32.
More broadly, simple fine-tuning attacks reliably destroy watermarks. Research confirms that training an open-weight model on as few as 5,000 clean domain samples for just three epochs - a process requiring minimal computational expense - is sufficient to entirely overwrite the watermark mechanisms while maintaining over 95% of the model's core functional accuracy 48. This vulnerability has already transitioned from theoretical research to active exploitation; researchers at ETH Zurich documented systemic "model laundering" on the Hugging Face platform in 2023, identifying over 50 instances where watermarked open-source models were stripped via basic quantization and pruning and subsequently re-uploaded under different nomenclatures 48. Consequently, security architects acknowledge that deploying watermarks within open-weight architectures functions solely as an evidence-gathering mechanism for retroactive copyright litigation, rather than an operational access control mechanism 48.
Cryptographic Provenance and Metadata Standards
In parallel with statistical watermarking, a distinct framework for digital authenticity relies on cryptographic metadata standards. The most prominent initiative is the Coalition for Content Provenance and Authenticity (C2PA), an open technical standard maintained by an industry consortium that includes Adobe, Microsoft, Intel, and the BBC 5.
The Anatomy of C2PA Manifests
Unlike statistical watermarking, which embeds imperceptible mathematical signals directly into the text tokens or image pixels, C2PA operates externally by appending a tamper-evident "Manifest" (or Content Credential) to the media file container 533. This manifest details the complete provenance history of the asset: the original creator, the specific hardware or software tool utilized, the timestamp of creation, and a comprehensive audit trail of any subsequent edits, including specific disclosures regarding generative AI involvement 533.
To ensure security, the C2PA standard binds this declarative metadata to the underlying digital asset using hard cryptographic hashes and signs the entire package utilizing X.509 certificates issued by trusted Certificate Authorities 55434. Any unauthorized manipulation of the asset's binary structure instantly invalidates the cryptographic signature, providing absolute, deterministic proof of tampering 556. This framework aligns directly with emerging global regulatory requirements, notably the European Union's AI Act and the IPTC 2025.1 metadata standard, which mandate explicit, machine-readable disclosures for synthetic content 556.
The Integrity Clash and Metadata Washing
Despite providing exceptionally rich provenance data, C2PA manifests suffer from a critical structural fragility: they are entirely dependent on the integrity of the file container across digital distribution channels 33. If a user copies text into a new document, captures a screenshot, or uploads an asset to a social media platform that routinely strips metadata to save bandwidth, the C2PA manifest is permanently destroyed 53357. The absence of a C2PA manifest cannot definitively prove that an asset is a deepfake; it only proves the asset lacks a verifiable cryptographic history 5.
Statistical watermarking provides the exact inverse capability. It carries minimal informational data - typically a simple binary flag indicating "AI-generated" - but offers profound resilience, persisting through copying, paraphrasing, and formatting changes 3357.
This bifurcation of capabilities has led researchers to identify a security vulnerability termed the "Integrity Clash." Because C2PA validation (a cryptographic signature check) and statistical watermark detection (a probabilistic signal decoding operation) function as entirely independent technical layers, neither conditions its verification on the output of the other 2. This independence permits adversarial "metadata washing." An attacker can maliciously strip the C2PA manifest from an AI-generated asset and subsequently apply a new, cryptographically valid C2PA manifest falsely asserting human authorship 2. A platform evaluating only the metadata will authenticate the asset as human, while a watermark detector will correctly flag it as synthetic 2. Consequently, comprehensive content authentication architectures require a cross-layer audit protocol, utilizing C2PA manifests for rich, primary provenance reporting, while relying on resilient statistical watermarks as an immutable, fallback truth signal 2733.
| Feature Characteristic | C2PA Content Credentials (Metadata) | Statistical Watermarking (Token Biasing) |
|---|---|---|
| Operational Mechanism | Appends X.509 cryptographically signed manifests to the file container structure. | Modifies vocabulary probabilities to embed mathematical signals in the text itself. |
| Informational Payload | Exceptionally high; records precise creator identity, toolchain, timestamps, and exhaustive edit histories. | Extremely low; typically restricted to a binary verification flag ("AI-Generated"). |
| Resilience to Distribution | Highly fragile; automatically stripped by screenshots, copy-pasting, and standard social media re-encoding. | Highly resilient; persists through copying, format changes, and moderate manual editing. |
| Tamper Evidence | Absolute; any unauthorized alteration of the file invalidates the cryptographic signature. | Probabilistic; heavy paraphrasing decays the detection confidence but does not explicitly flag a tamper event. |
| Standardization | Open, interoperable industry standard supported by major regulatory frameworks (EU AI Act). | Highly fragmented and proprietary; requires specific detection APIs matched to specific model providers. |
Industry Deployment and Production Status
Despite the rapid maturation of theoretical watermarking architectures and the availability of unified evaluation toolkits, global deployment across commercial language models remains highly fragmented. The hesitation stems from a complex calculus weighing technical limitations, operational overhead, and user retention risks.
Google DeepMind SynthID Integration
Google represents the most aggressive adopter of generative watermarking. Having successfully scaled SynthID-Image to watermark over ten billion synthetic images and video frames across its ecosystem by 2025, Google open-sourced the underlying algorithms for SynthID-Text through a Nature publication and integrated the toolkit directly into the Hugging Face Transformers library (v4.46.0+) 792058.
SynthID-Text leverages the distortion-free Tournament Sampling method, enabling watermarking integration directly into production pipelines via speculative sampling without degrading response latency or user-rated quality 720. However, its operational boundaries remain strictly defined by the medium's inherent vulnerabilities. SynthID-Text achieves functional detection accuracies ranging from 60% to 85% on unedited Gemini text outputs - a rate significantly lower than the 96%+ accuracy achieved by its image counterpart . Furthermore, Google openly acknowledges that detection reliability collapses if the text sequence is shorter than 200 words, if it involves rigid factual or code-based domains, or if it undergoes systematic paraphrasing or cross-lingual translation 927. Consequently, SynthID functions optimally as a preliminary screening mechanism within controlled publishing and academic environments, rather than an impenetrable security barrier .
OpenAI Deployment Hesitation
OpenAI's strategic trajectory highlights the commercial risks associated with watermarking text. Internal documentation leaked to The Wall Street Journal in 2024 revealed that OpenAI had successfully developed a robust text watermarking system for ChatGPT 3560. Widely believed to be a variation of the Aaronson Gumbel-max architecture, the system demonstrated near-perfect 99.9% detection accuracy during localized internal testing and had been classified as production-ready for nearly a year 76036.
Nevertheless, OpenAI intentionally suspended the public release 3662. The decision was driven by severe commercial apprehension; internal polling indicated that nearly 30% of loyal ChatGPT users would drastically reduce their reliance on the platform if anti-cheating watermarks were mandated, fearing professional and academic stigmatization 606263. Furthermore, OpenAI engineers expressed deep skepticism regarding the system's resilience against "globalized tampering" - such as users routing text through intermediate translation systems, employing unwatermarked competitor models for prompt rewriting, or executing basic character insertion-deletion scripts 3563. Compounding these technical concerns were ethical apprehensions mirroring the Stanford post-hoc studies, specifically that probabilistic detection thresholds could disproportionately and falsely penalize non-native English speakers relying on AI for legitimate writing assistance 353663. In response, OpenAI has shifted its operational focus toward metadata embeddings (C2PA) and expanding watermarking solely within its audiovisual product lines, such as DALL-E 3 and Sora 633738.
Anthropic and Meta Policy Approaches
Other foundational model developers have similarly deferred token-level text watermarking. Anthropic, developer of the Claude series of models, maintains an explicit policy confirming that its text outputs are not watermarked as of late 2025 6639. While Anthropic signed the 2023 White House voluntary commitments recognizing watermarking as a crucial developmental priority, the organization currently relies entirely on alternative safety frameworks, including Reinforcement Learning from Human Feedback (RLHF), Constitutional AI guardrails, and stringent usage policies governing political, cybersecurity, and agentic workflows 6640.
Meta's approach is strictly bifurcated by modality. Meta actively deploys highly sophisticated watermarks within continuous media domains, including "AudioSeal" for speech synthesis and "Stable Signature" for its latent diffusion image models 741. Stable Signature operates by fine-tuning the foundational VAE decoder, ensuring that the watermark is inherently rooted within the generation process and persists even if downstream users subsequently fine-tune the open-source architecture 4142. However, Meta has deliberately omitted equivalent token-biasing watermarks from its open-weight LLaMA text models, acknowledging the reality that any text-based watermark embedded in an open-weight ecosystem can be trivially erased via basic fine-tuning or smoothing attacks by malicious actors possessing white-box access 48.
Conclusion
The pursuit of reliable mechanisms to detect AI-generated text exposes a profound operational tension between mathematical theory and the inherent limitations of language as a discrete data medium. Post-hoc detection systems, while simple to deploy, are fundamentally flawed; their reliance on stylistic heuristics generates unacceptable false positive rates, systemic biases against non-native speakers, and extreme fragility to basic prompt engineering. Conversely, generation-time statistical watermarking - whether executed via distortionary token-probability shifting or sophisticated distortion-free algorithms like Tournament Sampling - provides the rigorous mathematical foundation required for provable hypothesis testing without degrading linguistic fluency.
Despite these theoretical achievements, the low-entropy nature of text allows malicious actors to execute semantic-preserving paraphrasing and translation attacks that effectively scramble the requisite cryptographic sequences, neutralizing detection capabilities. Furthermore, the global expansion of open-weight model architectures renders embedded watermarks structurally insecure, as minor neural fine-tuning can permanently erase tracing mechanisms. Consequently, while text watermarking provides critical baseline transparency, it remains an imperfect, probabilistically bounded tool. It serves as a vital component of a defense-in-depth strategy when synchronized with cryptographic metadata standards like C2PA, but the fundamental plasticity of human language currently precludes the deployment of a definitive, tamper-proof verification architecture.