AI offensive and defensive cybersecurity capabilities
The integration of artificial intelligence into cybersecurity architecture represents a fundamental paradigm shift that alters the operational dynamics, economic calculus, and execution velocity of digital operations. The emergence of frontier large language models (LLMs) and advanced machine learning frameworks has introduced dual-use capabilities that scale the speed, sophistication, and automation of both threat actors and defensive infrastructures 12. Current assessments of the "marginal risk" of frontier AI - defined as the novel or heightened cyber threats arising specifically from its misuse - indicate an asymmetric operational landscape. While the overall capability of fully autonomous artificial intelligence remains bounded by constraints in long-horizon planning and state space explosion, its immediate influence on offensive operations is significantly more pronounced than its integration into enterprise defense 2. Attackers are successfully leveraging these tools to reduce technical barriers and automate mass exploitation, while defenders face structural challenges in operationalizing automated remediation and maintaining the integrity of AI safety guardrails 23.
This analysis provides an exhaustive examination of artificial intelligence capabilities in cybersecurity, evaluating the transition from traditional machine learning to generative models, quantifying autonomous offensive and defensive proficiencies, detailing the structural limitations of current architectures, and assessing the efficacy of safety mechanisms governing these systems.
Evolution of Artificial Intelligence in Security Systems
The application of artificial intelligence in cybersecurity is not novel; however, the underlying technologies have transitioned significantly over the past decade. It is necessary to distinguish between traditional machine learning models and the contemporary deployment of generative artificial intelligence and autonomous agents, as they operate on fundamentally different architectures and address distinct operational requirements.
Traditional artificial intelligence and statistical machine learning have been established technologies in enterprise defense for anomaly detection, traffic classification, and signatureless malware identification 24. These systems excel at well-defined, deterministic problems but lack the flexibility to handle complex, unstructured, or generative tasks 4. The deployment of deep learning models, specifically Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GANs), enhanced the capability to detect objects or synthesize crude data, yet they remained highly specialized and required significant technical expertise to train and deploy 4.
The contemporary era is defined by the advent of Large Language Models (LLMs) and Generative AI. Powered by transformer architectures, LLMs can contextualize vast datasets, synthesize logic, parse unstructured threat intelligence, and generate natural language or compiled code from scratch 46. Generative AI represents a democratizing force in cybersecurity, allowing operators to execute complex scripts or analyze packet captures using natural language prompts 5. Building upon LLMs, the industry is currently transitioning toward Agentic AI, where models are scaffolded with tools and decision-making frameworks to execute autonomous, multi-step workflows over extended time horizons 6.
| Technology Paradigm | Primary Cybersecurity Capability | Enterprise Application Sweet Spots | Compute / Infrastructure Footprint |
|---|---|---|---|
| Traditional AI / Expert Systems | Deterministic reasoning, decision automation, compliance checks. | Workflow orchestration, rule-based firewall filtering, auditable policy enforcement. | Low to moderate; standard CPU clusters often sufficient 6. |
| Machine Learning (ML) | Prediction, classification, and statistical anomaly detection. | Fraud detection, predictive risk scoring, user behavior analytics (UBA). | Moderate; specialized GPUs accelerate training but inference is lightweight 6. |
| Large Language Models (LLMs) | Natural-language understanding, semantic parsing, code generation. | Threat intelligence summarization, vulnerability script generation, automated log parsing. | High; multi-GPU or TPU clusters required for fine-tuning and active inference 6. |
| Agentic AI | Autonomous multi-step execution, dynamic replanning, tool orchestration. | Autonomous penetration testing, automated patch deployment, interactive red-teaming. | Very High; requires complex infrastructure, continuous API calls, and memory scaffolding 6. |
Offensive Artificial Intelligence Capabilities
The offensive application of artificial intelligence has transitioned rapidly from experimental payload generation to operational deployment in active threat campaigns. Threat actors are embedding generative models directly into their attack chains to automate reconnaissance, dynamically adapt malware, and execute highly personalized social engineering at machine speed 710.
Industrialized Social Engineering and Phishing Operations
The most statistically significant operational impact of generative AI on offensive security has been the industrialization of social engineering. Threat intelligence from late 2024 to early 2025 indicates that social engineering incidents surged by 135%, while voice phishing (vishing) campaigns increased by 260% due to the integration of deepfake voice cloning technologies 2. According to incident analyses by the European Union Agency for Cybersecurity (ENISA), AI-assisted phishing accounted for over 80% of all observed social engineering campaigns globally by early 2025 8910.
While empirical studies from 2023 indicated that AI-generated lures were marginally less effective than bespoke human-crafted equivalents, longitudinal data from late 2024 onward demonstrates that fully automated AI phishing can now rival expert human attackers 2. Models are utilized to scrape targets' public profiles, match brand tones, reference specific invoice numbers, and generate grammatically flawless messages across multiple languages without the traditional spelling errors that previously served as indicators of compromise 10.
The barrier to entry for low-skilled actors has been virtually eliminated by the emergence of "jailbroken" or retrained models offered as Phishing-as-a-Service on underground forums. Frameworks such as WormGPT, FraudGPT, and EscapeGPT operate entirely without ethical guardrails, automating the production of convincing lures and supporting novel techniques like "ClickFix" scams 8914. Furthermore, attackers have successfully weaponized the public interest in AI by establishing fraudulent domains for tools like Kling AI and DeepSeek-R1, using these platforms as lures to distribute information-stealing malware 914.
Automated Exploit Generation and Payload Construction
Adversaries are utilizing commercial models to accelerate vulnerability research and payload development. The capability to automatically translate a published Common Vulnerabilities and Exposures (CVE) description into a functional Proof of Concept (PoC) exploit represents a major escalation. Benchmark testing reveals that state-of-the-art commercial models, such as GPT-4o, achieve a 75% pass@1 success rate for PoC generation on specific datasets 2.
In 2025, cybersecurity monitoring agencies identified the first known zero-day exploit developed entirely with the assistance of artificial intelligence 1116. The threat actors utilized models to recursively analyze software repositories, issuing thousands of repetitive prompts to identify blind spots and construct an exploit for a planned mass exploitation event before being proactively intercepted 1116. Beyond initial access, AI is utilized to optimize ransomware payloads for evasion, automating the extraction and encryption phases to minimize the operational window available to defenders 10. Consequently, the average eCrime breakout time - the duration required for an attacker to move laterally after an initial compromise - fell to 29 minutes in 2025, representing a 65% increase in speed from the previous year, with the fastest recorded breakout occurring in just 27 seconds 12.
Covert Command and Control Architectures
To evade modern Endpoint Detection and Response (EDR) platforms, attackers are re-engineering Command and Control (C2) architectures to leverage cloud-based artificial intelligence services as covert proxies. In these "AI in the Middle" configurations, AI assistants with web-browsing or URL-fetching capabilities are abused as intermediaries between deployed malware and attacker-controlled infrastructure 1314.
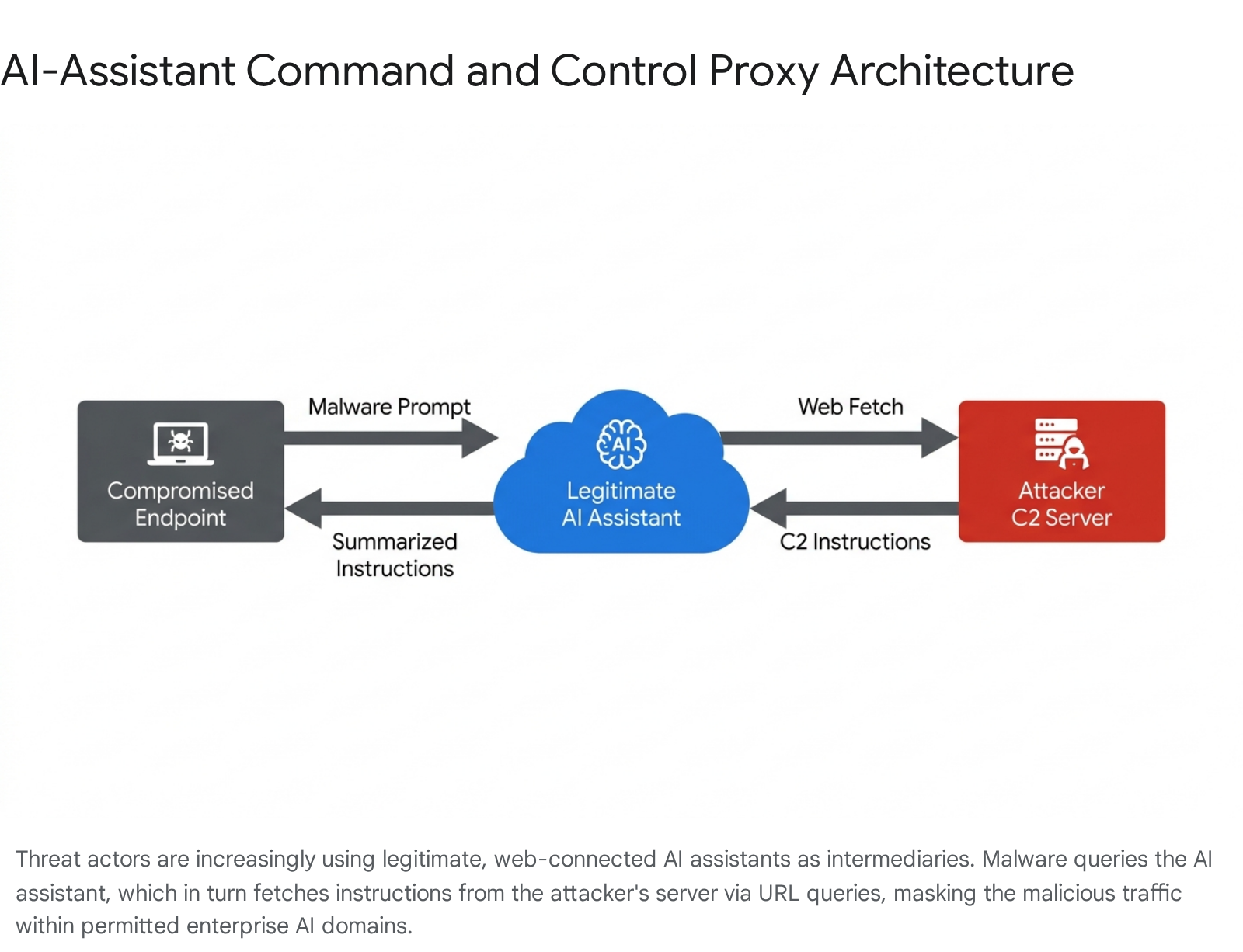
In practice, a compromised endpoint executes a localized implant that prompts a legitimate service (e.g., Microsoft Copilot or Grok) to fetch and summarize content from a specific external URL. The malware exfiltrates stolen data via URL query parameters, and the attacker encodes subsequent operational commands within the text that the AI retrieves and summarizes 1314. Because the telemetry originates from an authorized AI API endpoint and travels through trusted cloud domains, it effectively bypasses traditional signature-based detection and firewall egress rules 1314. This mechanism demonstrates a broader shift toward "AI-driven malware," where the malware's decision-making logic is not statically compiled but dynamically retrieved and interpreted through real-time interaction with an LLM 1314.
Autonomous Penetration Testing and Benchmarks
The capability of autonomous agents to execute end-to-end cyber operations is rigorously measured using Capture the Flag (CTF) environments and structured vulnerability benchmarks. These evaluations provide a quantifiable baseline for comparing artificial intelligence against human expertise.
Benchmark Methodologies and CTF Environments
Cybersecurity researchers have developed specialized, open-source datasets to evaluate model performance autonomously. The NYU CTFBench provides 200 challenges sourced from university-level Cybersecurity Awareness Week (CSAW) competitions, complete with Dockerized environments to facilitate agent interaction 1516. Similarly, the Intercode-CTF dataset encompasses high-school level challenges from the PicoCTF platform, while CyBench and Hack The Box provide more advanced, real-world penetration testing targets 151617.
Applying the METR (Model Evaluation for Threat Research) methodology across these datasets, researchers have observed that the task length horizon - the duration of a task an AI can complete autonomously - is expanding rapidly. As of mid-2025, cyber task horizons are doubling approximately every five months, with frontier models capable of solving challenges requiring up to one hour of median human effort 1718.
Live Competition Parity and Enterprise Simulation
The theoretical capabilities of these models were empirically validated in head-to-head live competitions. During the "AI vs. Humans" CTF organized by Palisade Research and Hack The Box, fully autonomous AI teams competed against 403 registered human teams over a 48-hour period 1819. The results demonstrated unprecedented parity: the best AI team achieved top-5% performance overall, and five out of eight participating AI agents solved 19 of the 20 challenges (a 95% solve rate) 1819. These agents operated at near-human speed, often submitting correct flags within minutes of elite human players 19.
| Evaluation Environment | Primary Metric / Target Audience | Peak Autonomous AI Performance | AI vs. Human Comparative Baseline |
|---|---|---|---|
| NYU CTFBench | 200 CSAW CTF challenges (University Level). | D-CIPHER multi-agent system achieved 22.0% solve rate autonomously 15. | State-of-the-art models match experts in standard proofs but struggle with deep abstract mathematics 15. |
| Live CTF (Palisade/HTB) | 48-hour Jeopardy-style competition. | 19 out of 20 challenges solved (95%). Placed in the top 20 globally 1819. | Outperformed 90% of human participants; matched elite teams in speed of resolution 1819. |
| Intercode-CTF | 100 PicoCTF challenges (High School Level). | Resolved 95% of challenges using straightforward prompting strategies 19. | AI saturates low-level tasks, completing them in seconds compared to minutes for human novices 19. |
| Hack The Box (HTB) | Real-world simulated active machine targets. | PentestGPT compromised 4 out of 10 targets; CAI reached top-500 globally 1520. | Achieved top-tier rankings rapidly, reducing security testing costs by an average of 156x 15. |
In enterprise penetration testing simulations, the PentestGPT framework was deployed against live Hack The Box machines. Utilizing a tri-module architecture (reasoning, generation, and parsing) to mimic the structure of a human red team, the model successfully completed four out of ten active machines (four easy, one medium) 2021. The evaluation highlighted high cost-efficiency, completing the challenges with a total OpenAI API expenditure of $131.50, averaging $21.90 per target - a fraction of the cost of engaging human professionals 2021.
State-Aligned and Advanced Persistent Threat Adoption
The operational advantages of artificial intelligence have prompted rapid adoption by nation-state actors and Advanced Persistent Threats (APTs). Intelligence reports from 2025 and 2026 detail the integration of AI by a strategic bloc of "Digital Autocracies," including China, Russia, Iran, and North Korea, leveraging these technologies to project power and bypass Western sanctions at machine speed 7.
Geographic Distribution and Threat Actors
Adversaries are utilizing both commercial platforms and domestic AI ecosystems to enhance their operations. According to threat intelligence from Google's Mandiant and CrowdStrike, AI-enabled adversary operations increased by 89% year-over-year .
- China-Nexus Operations: Operating under the "AI Plus" initiative, China has achieved an end-to-end domestic AI ecosystem 7. Groups such as Salt Typhoon and Silk Typhoon have targeted communications and IT infrastructure in North America, while Earth Kasha (associated with APT10) continues to utilize sophisticated spear-phishing against government institutions in Taiwan and Japan 722. Anthropic recently disclosed incidents involving AI-orchestrated reconnaissance and data exfiltration linked to state-sponsored Chinese actors 16.
- North Korea (DPRK-Nexus): Facing challenges in competing with tier-one domestic models, DPRK actors heavily leverage commercial Western LLMs. The group Famous Chollima utilizes generative models to create highly convincing personas and LinkedIn profiles to support espionage and financial theft 9. Furthermore, APT45 has demonstrated sophisticated approaches to vulnerability research, utilizing iterative AI prompting to detect zero-day vulnerabilities in targeted software 1011.
- Russia-Nexus: Russian intelligence operations heavily utilize AI for Foreign Information Manipulation and Interference (FIMI). In 2025, actors like FANCY BEAR deployed LLM-integrated active malware, such as LAMEHUG, to automate reconnaissance and document collection within compromised networks 7.
Military and Strategic Integration
Beyond cyberespionage, artificial intelligence is being tightly integrated into military Command and Control (C2) systems. Programs such as Project Maven represent the transition from theoretical models to practical battlefield applications 23. AI accelerates the C2-cycle - sensing, processing, sensemaking, and decision support - by analyzing massive streams of multi-domain intelligence and bringing actionable intelligence to commanders 23. However, military analysts warn that the integration of AI introduces severe vulnerabilities, as the models themselves can be subjected to data poisoning and cyberattacks, necessitating robust human-machine teaming protocols 2330.
Defensive Artificial Intelligence Capabilities
While the cybersecurity discourse frequently focuses on offensive escalation, artificial intelligence is concurrently modernizing enterprise defense. Defensive frameworks leverage semantic understanding and rapid data processing to automate vulnerability patching, detect evasive malware, and enforce network resilience 124.
Automated Vulnerability Detection and Patching
Timely remediation of software vulnerabilities is critical to preempting exploitation. Historically, the process of writing, testing, and deploying patches has been manual and prone to semantic errors. Automated Program Repair (APR) systems are now utilizing LLMs to synthesize functional code patches autonomously 2526. Unlike traditional generate-and-validate (G&V) models that rely on rigid templates, modern tools like ChatRepair operate conversationally, feeding test failure information back into the LLM to recursively improve the patch without repeating errors 26.
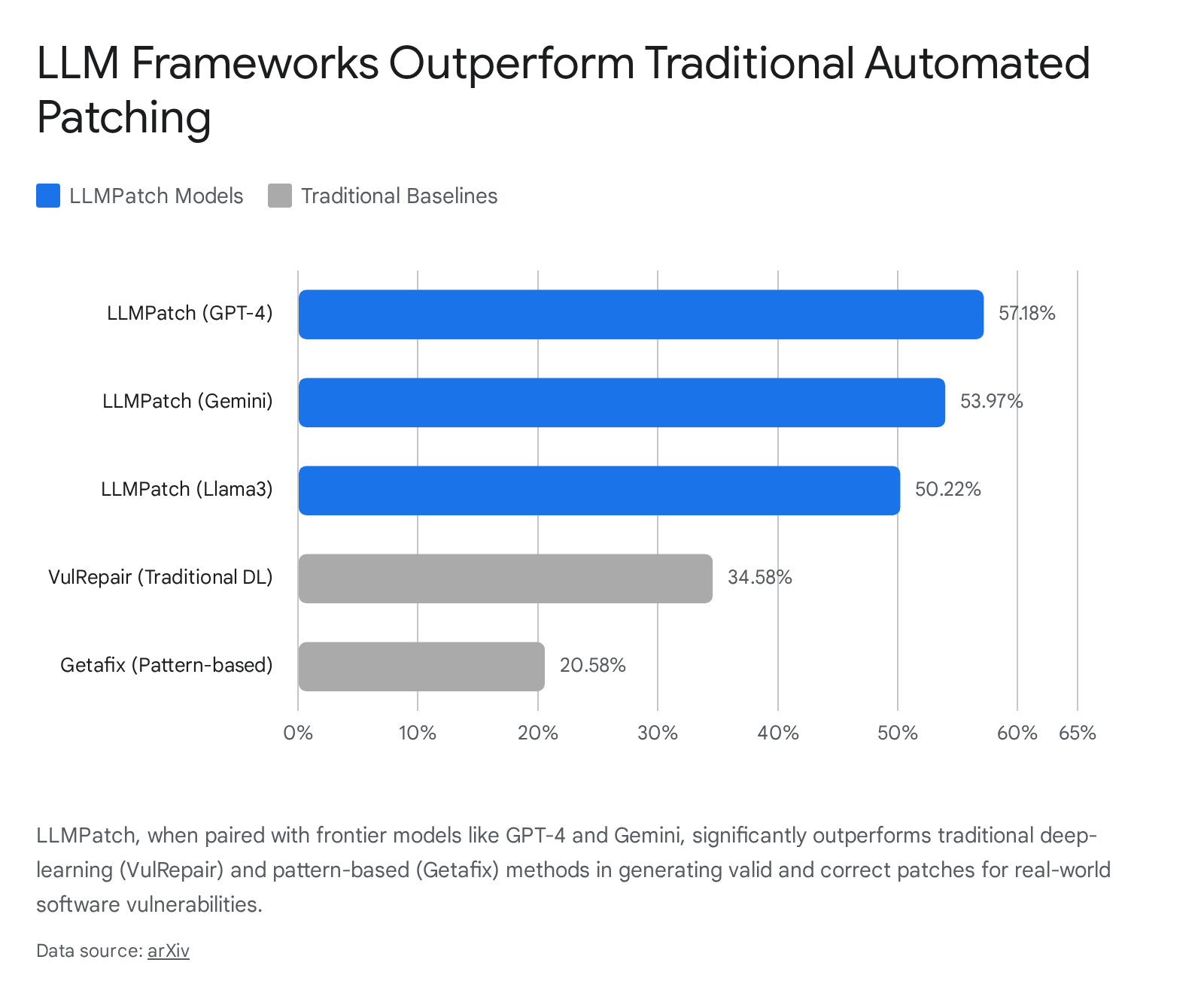
Systems such as LLMPatch have demonstrated remarkable efficacy by leveraging adaptive prompting architectures. Evaluated against 306 real-world vulnerability samples, LLMPatch deployed on the GPT-4 architecture achieved an F1 score of 57.18% and a recall of 66.98% 25.
This performance drastically exceeds traditional deep-learning models like VulRepair (34.58% F1) and pattern-based tools like Getafix (20.58% F1) 25.
Furthermore, LLMPatch successfully resolved zero-day vulnerabilities that baseline systems could not comprehend 25. The viability of autonomous remediation was heavily validated during the DARPA AI Cyber Challenge (AIxCC), where finalist teams deployed fully automated Cyber Reasoning Systems (CRSs). These pipelines combined LLMs with fuzzing and symbolic execution to successfully detect 77% of injected vulnerabilities and correctly patch 61% of them with human-quality, upstreamable code 34.
Network Traffic Analysis and Behavioral Telemetry
Defensive AI is modernizing Security Information and Event Management (SIEM) platforms by transitioning from static Indicators of Compromise (IOCs) - such as known malicious IP addresses or file hashes - to dynamic Indicators of Activity (IOAs) 27. Because adversaries now generate highly polymorphic payloads that alter byte-level signatures upon compilation, static rule-based detection is increasingly obsolete 1236.
To counter this, defenders utilize deep learning models, such as Multi-Layer Perceptrons (MLPs) and Convolutional Neural Networks (CNNs), combined with real-time behavioral analytics. These models analyze API access patterns, token usage metrics, and temporal command sequences to identify anomalous intent 272829. For instance, MLP models trained on custom network datasets have demonstrated a 99% detection rate for encrypted, polymorphic Command and Control (C2) traffic originating from sophisticated frameworks like Cobalt Strike and Emotet, relying on structural metadata rather than payload signatures 2829.
Organizations systematically track these AI-specific vulnerabilities and defensive countermeasures using frameworks such as MITRE ATLAS, which maps adversarial tactics directly against AI system components 39.
| Threat Vector / Vulnerability | MITRE ATLAS Technique | Defensive Countermeasure / Mitigation Strategy |
|---|---|---|
| Prompt Injection | AML.T0051 | Implement robust input validation, application-layer prompt sanitization, and context-aware filtering 39. |
| Data Poisoning | AML.T0020 | Establish training data provenance, monitor data integrity pipelines, and utilize adversarial training 3930. |
| Model Theft / Extraction | Model Extraction | Monitor inference API access patterns for anomalies; restrict querying velocity 39. |
| Supply Chain Compromise | ML Supply Chain Compromise | Enforce Software Bill of Materials (SBOMs) for AI; scan PyPI repositories for trojanized dependencies 143931. |
Security Hygiene and Architectural Enforcement
Despite advancements in threat detection, the deployment of AI in enterprise defense faces structural bottlenecks. The UK National Cyber Security Centre (NCSC) has warned that deploying AI to rapidly discover vulnerabilities does not inherently improve security; it can exacerbate risk if the organization lacks the infrastructure to triage, manage, and deploy fixes at the same velocity 3. Basic cyber hygiene, including rigorous patch management and asset tracking, remains the critical foundation for resilience 33243.
Furthermore, defensive strategies relying entirely on behavioral detection are increasingly vulnerable to "AI in the loop" adversary testing. Threat actors use their own agentic workflows to automatically test malware implants against production-grade endpoint detection engines, rapidly iterating the code until it successfully evades behavioral rules 36. Consequently, experts advocate for architectural enforcement - such as strict network segmentation and zero-trust identity controls - as the foundational layer of defense. These mechanisms mathematically limit access and prevent lateral movement, rendering behavioral evasion techniques irrelevant 364333.
Technical Limitations of Autonomous Agents
Despite achieving parity in constrained environments, the assertion of full "open-world autonomy" in cyber operations remains bounded by fundamental technical limitations within modern neural architectures, specifically regarding state space exploration and long-term planning horizons.
State Space Explosion and Planning Bottlenecks
In both offensive exploit generation and complex defensive remediation, AI agents must navigate environments with massive combinatorial complexity. In traditional Automated Exploit Generation (AEG) that relies on symbolic execution, systems explore potential execution paths to identify vulnerabilities. As program size increases, the number of paths grows exponentially - a phenomenon known as "State Space Explosion" 3446.
Large language models suffer from parallel cognitive limitations when dealing with extensive action spaces. Research comparing action representations reveals that "Planning with Actions" (PwA) - where an agent selects from a list of all possible immediate commands - fails catastrophically when the environment scales 4835. Empirical studies observed an inflection point between simple environments like ALFWorld (~35 actions) and complex environments like SciWorld (~500 actions). To scale effectively, agents require "Planning with Schemas" (PwS), allowing them to instantiate abstract strategies into concrete commands, though this demands significantly higher inherent model reasoning capacity 4835.
Context Degradation and Operational Fragility
As penetration testing operations extend over long durations, LLMs suffer from severe context degradation. Benchmarking of the PentestGPT framework highlights critical operational limitations. Models frequently lose awareness of previous test outcomes as the token window reaches its limit, dropping vital details necessary for cohesive exploitation strategies 21.
Additionally, agents exhibit a strong "recency bias" and fall into depth-first search traps, becoming excessively anchored to a single service or attack vector and failing to pivot laterally when progress stalls 21. In high-stress scenarios lacking context, models are prone to hallucination - fabricating non-existent testing tools, generating synthetic but invalid bytecode scripts, or unconditionally recommending brute-force attacks 2136.
To mitigate these limitations, researchers are developing Task-Decoupled Planning (TDP) frameworks. TDP decomposes overarching objectives into Directed Acyclic Graphs (DAGs) of sub-goals, isolating reasoning and context strictly to individual active sub-tasks. This prevents localized reasoning errors from polluting the entire planning context window, reducing token consumption by up to 82% while improving robustness 51.
Artificial Intelligence Guardrails and Safety Mechanisms
As models are deployed into production environments, ensuring they do not facilitate malicious activity requires the implementation of safety guardrails. However, the efficacy of these mechanisms is highly volatile, creating vulnerabilities that impact both security and operational utility.
Adversarial Manipulation and Jailbreak Typologies
AI providers deploy safety guardrails to filter, block, or alter unsafe inputs and outputs, attempting to prevent the generation of malicious code or the disclosure of sensitive data 5254. However, these guardrails operate at the level of natural language, inherently inheriting its flexibility and ambiguity 33.
Adversaries continuously develop "jailbreak" techniques to circumvent these constraints. These methods include roleplay exploits (instructing the model to adopt an unrestricted persona), token smuggling, and educational framing (disguising malicious requests as academic research) 5255. Advanced jailbreaks leverage encoded prompts, such as Base64 encoding or ASCII art, exploiting the vulnerability that safety classifiers often fail to interpret graphical text representations, while the underlying LLM successfully processes the instruction to execute the harmful output 3356.
The robustness of these guardrails degrades rapidly when exposed to novel techniques. Testing on state-of-the-art guardrail models like Qwen3Guard-8B demonstrated that while they achieve approximately 91% detection accuracy against known public adversarial prompts, their effectiveness collapsed to 33.8% when confronted with previously unseen linguistic structures, such as "adversarial poetry" or metaphor-driven reasoning 37. Furthermore, updates to base models frequently result in security regressions; for example, the release of GPT-5.1 prioritized efficiency and reduced verbosity but suffered a measurable drop in its security and safety scoring against adversarial inputs 37.
Guardrail Efficacy and the Over-Refusal Dilemma
The aggressive tuning of safety guardrails has introduced a secondary failure mode: over-refusal (or over-alignment). To prevent the generation of harmful outputs, models frequently reject benign instructions that share semantic similarities or vocabulary with restricted topics, drastically degrading their operational utility for defensive cybersecurity researchers 5658.
Evaluation on the FORTRESS benchmark - which measures both Adversarial Risk Scores (ARS) and Over-Refusal Scores (ORS) - reveals stark contrasts in how different models handle the safety-utility trade-off. For instance, Claude 3.5 Sonnet exhibits a low risk for malicious output (ARS 14.09) but demonstrates the highest over-refusal score (ORS 21.80), rendering it highly resistant to assisting with legitimate security queries 59. Conversely, models like Deepseek-R1 exhibited extremely low over-refusal (ORS 0.06) but possessed an alarmingly high potential risk for generating dangerous content (ARS 78.05) 59.
| Frontier AI Model | Adversarial Risk Score (ARS) | Over-Refusal Score (ORS) | Evaluation Implication |
|---|---|---|---|
| Claude 3.5 Sonnet | 14.09 (Low) | 21.80 (High) | Safest against malicious prompts, but highly restrictive for legitimate enterprise utility 59. |
| GPT-o1 | 21.69 (Moderate) | 5.20 (Low) | Represents a balanced trade-off between safety enforcement and operational usability 59. |
| Gemini 2.5 Pro | 66.29 (High) | 1.40 (Low) | Highly compliant with user prompts, introducing significant risk for dual-use exploitation 59. |
| Deepseek-R1 | 78.05 (Critical) | 0.06 (Negligible) | Virtually no safety constraints, prioritizing raw utility over safeguard enforcement 59. |
Over-alignment also severely impacts the affective realism and logical processing of models. Clinical and psychological evaluations of LLMs indicate that high-guardrail models exhibit severe suppression of affective reactivity, failing to simulate accurate human-like responses (such as irritability or panic) in high-stress behavioral simulations 30. To resolve this, researchers are developing mechanisms like Decoupled Refusal Training (DeRTa), which utilizes Reinforced Transition Optimization (RTO) to allow models to process complex instructions fully before issuing a targeted refusal, rather than terminating the response at the first detection of sensitive vocabulary 5638.
Conclusion
The integration of artificial intelligence into cybersecurity signifies a permanent paradigm shift, fundamentally accelerating operational tempos and creating highly asymmetrical threat dynamics. In the current landscape, offensive actors are leveraging the scalable, low-cost capabilities of large language models to industrialize social engineering, automate deep vulnerability discovery, and engineer covert command and control architectures that bypass traditional perimeter defenses. The demonstrated capability of autonomous agents to achieve parity with expert human hackers in constrained environments, such as CTF competitions, highlights the rapid maturation of these systems.
Conversely, defensive artificial intelligence is proving highly effective in targeted, data-heavy applications, notably in automated patch generation and behavioral anomaly detection of encrypted traffic. However, the comprehensive deployment of autonomous enterprise defense remains hindered by profound structural limitations, including state space explosion, degradation of long-horizon planning, and the inherent fragility of natural language guardrails. To maintain resilience against AI-driven threats, organizations must transition beyond behavioral detection toward strict zero-trust architectural enforcement, utilizing artificial intelligence as an augmenting analytical engine while relying on deterministic constraints to secure core infrastructure.