AI for formal mathematics and machine-verified proofs
The intersection of artificial intelligence and advanced mathematics has historically been dominated by computational algebra and numerical analysis. However, the contemporary frontier of mathematical artificial intelligence focuses on reasoning, abstract deduction, and the synthesis of original, logically sound mathematical proofs 12. Unlike natural language processing domains, where heuristic approximation and generative plausibility are often sufficient, formal mathematics demands absolute deductive correctness. A single logical discrepancy or unverified assumption can invalidate an entire proof architecture 3.
To overcome the inherent unreliability and hallucination tendencies of large language models (LLMs), researchers have increasingly paired neural architectures with interactive theorem provers (ITPs) such as Lean, Coq, and Isabelle 45. These neuro-symbolic systems navigate the vast, infinitely branching search space of mathematical tactics while strictly bound by verified computational logic. This paradigm shift has accelerated rapidly, moving AI capabilities from solving high-school algebra benchmarks to achieving certified gold-medal parity at the International Mathematical Olympiad (IMO) between 2024 and 2025 678.
Foundational Frameworks for Formal Mathematics
The development of autonomous mathematical agents relies fundamentally on the environments in which they operate. While human mathematicians communicate via informal natural language - relying on shared intuition, implicit assumptions, and peer review to bridge logical gaps - formal mathematical systems require every premise and deduction to be explicitly coded 910.
The Lean Theorem Prover and Kernel Architecture
Lean 4 represents the current state-of-the-art in interactive theorem proving and dependently typed functional programming. It is designed to deliver both scalable formal verification and high-performance computation 2. The architecture of Lean 4 is highly modular, reflecting best practices from proof engineering and programming language implementation.
The processing pipeline of Lean 4 operates through several distinct stages. Initially, source files are parsed into an annotated Abstract Syntax Tree (AST) that supports both user-defined and core syntax extensions. This is followed by elaboration, a process where the system resolves overloading, inserts implicit arguments and coercions, generates unification constraints, and outputs pre-terms with full typing, eliminating all syntactic sugar 2.
At the center of Lean's architecture is the minimal trusted kernel, which acts as the ultimate arbiter of mathematical truth. The kernel implements a dependent type theory based on the Calculus of Inductive Constructions, evaluating elaborated terms to ensure metatheoretical correctness 211. This design adheres to the "de Bruijn criterion," which dictates that proof assistants must produce proof terms that can be verified by a small, independent, and highly scrutinized piece of code 11. By separating the massive machinery used to generate proofs from the minimal code required to check them, Lean guarantees that bugs in the higher-level automation scripts or AI-generated inputs cannot accidentally validate a false proof 11. For AI models, this creates an uncompromising filter: the AI can hallucinate any sequence of tactics, but if the steps do not align with the foundational axioms of type theory, the Lean compiler simply rejects the code 411.
The Mathlib Ecosystem and Decentralized Development
The utility of any theorem prover is constrained by its library of existing mathematical knowledge. For Lean, this repository is Mathlib, a community-driven, open-source library that has become one of the fastest-growing collections of formalized mathematics 1312. As of early 2026, Mathlib contained over 1.9 million lines of code, encompassing more than 92,000 definitions and 179,000 theorems across fields such as algebra, topology, and number theory 131213.
Mathlib is characterized by a decentralized governance model, relying on contributions from over 370 active developers globally 1214. The library's structural complexity is immense; a network analysis of Mathlib revealed a multilayer dependency graph comprising 308,129 declarations and 8.4 million edges 17. Notably, 74.2% of all dependency edges are invisible in the source code, generated silently by the compiler through mechanisms like coercions and structure inheritance 17.
To manage this scale and ensure global coherence, the Mathlib community relies heavily on automated semantic linters 13. These include syntax linters and environment linters that enforce strict coding conventions and verify global coherence properties 13. Despite these efforts, Mathlib remains incomplete, missing formalizations for large segments of modern, research-level mathematics. When an AI system encounters a problem requiring a theorem not yet in Mathlib, it faces a significant bottleneck, necessitating that the system auto-formalize the missing prerequisites 1519.
Early Neural Theorem Proving Architectures
Before achieving Olympiad-level performance, AI researchers developed intermediate methodologies to bridge the gap between informal human reasoning and formal syntactic constraints. Two prominent architectures that defined this transitional period were the Draft, Sketch, and Prove (DSP) framework and HyperTree Proof Search (HTPS).
Draft, Sketch, and Prove Methodologies
The translation of existing, human-written mathematical proofs into machine-verifiable code is a notoriously difficult process 2016. The Draft, Sketch, and Prove (DSP) methodology was introduced to automate this auto-formalization by taking advantage of the informal reasoning capabilities inherent in large language models 1617.
The DSP pipeline operates in three discrete stages. First, in the drafting phase, an LLM is prompted with an informal mathematical statement and generates a natural-language proof 1617. Researchers utilized models such as Codex and various scales of the Minerva model (8B, 62B, and 540B parameters), using greedy decoding or nucleus sampling to generate up to 100 informal drafts per problem 17. Second, in the sketching phase, the informal proof is mapped into a formal "proof sketch." The model translates the high-level reasoning steps into intermediate formal conjectures, aligning them with informal proof segments via in-line comments, but leaves the complex logical transitions as open gaps 1618. Finally, in the proving phase, an automated theorem prover (ATP) such as Sledgehammer - operating within the Isabelle environment - is deployed to synthesize the missing formal proofs for every open conjecture 1617.
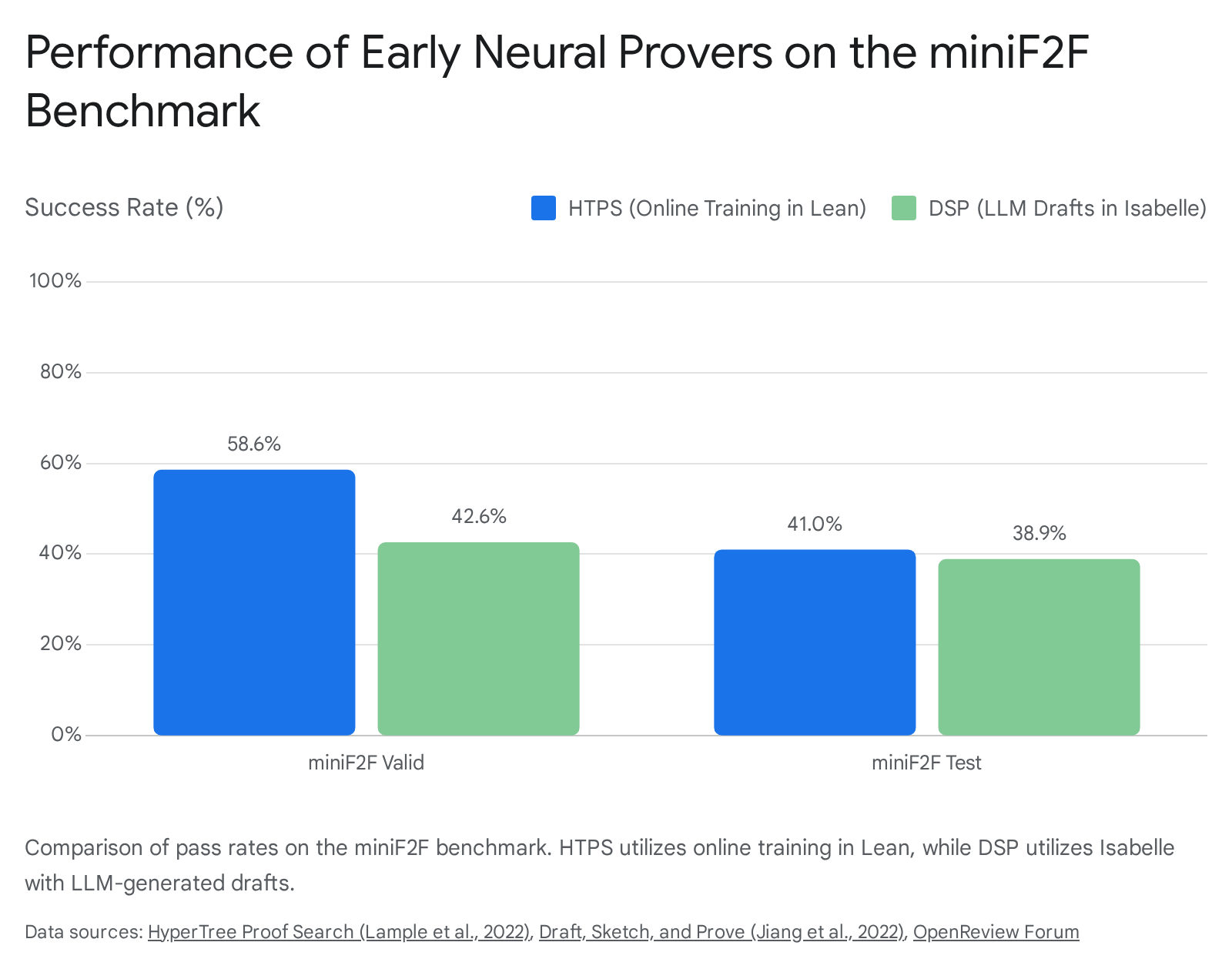
Ablation studies demonstrated that the DSP methodology was highly effective at guiding search algorithms toward easier sub-problems. On the miniF2F benchmark - a cross-system dataset of high-school competition mathematics - DSP increased the baseline success rate of automated provers from 20.9% to 39.3% using human-written informal drafts, and up to 38.9% when using drafts generated entirely by the Minerva 540B model 161719.
HyperTree Proof Search Algorithms
While DSP relied on external ATPs to close logical gaps, HyperTree Proof Search (HTPS) sought to optimize the search algorithm itself within formal environments like Lean and Metamath. Theorem proving can be conceptualized as a zero-sum game with perfect information, where the state space is defined dynamically by the theorem being proved 2520.
Inspired by the AlphaZero reinforcement learning algorithm, HTPS utilizes an online training procedure for transformer-based provers 1021. The model employs a policy network to sample potential tactics and a value network to evaluate the viability of resulting proof states 22. By extracting minimal proofs of solved nodes and learning from both successful and failed searches, HTPS generalizes to mathematical domains far outside its initial training distribution 1022.
Evaluations showed that HTPS achieved state-of-the-art performance on multiple environments. In Metamath, a model trained via HTPS managed to prove 65.4% of a held-out set of theorems in a supervised setting, which increased to 82.6% when augmented with online training 1022. On the Lean-based miniF2F-curriculum dataset, HTPS advanced the proving accuracy from 31% to 42% 2122.
Neuro-Symbolic Systems and the 2024 Olympiad
The transition from standard benchmark success to solving International Mathematical Olympiad (IMO) problems marked a watershed moment. The IMO is widely regarded as the ultimate grand challenge for mathematical AI, requiring solutions to exceptionally difficult, novel problems in algebra, combinatorics, geometry, and number theory over a 4.5-hour time limit per session 6723. In July 2024, Google DeepMind deployed a combined system of AlphaProof and AlphaGeometry 2, achieving an unprecedented silver-medal standard 730.
AlphaGeometry 2 Architecture
Olympiad geometry problems present a unique challenge because they frequently require the construction of auxiliary geometric elements - such as new points, lines, or circles - that are not explicitly referenced in the problem statement 31. Traditional computer algebra systems and symbolic deduction engines struggle to identify these constructive leaps due to the practically infinite search space 2531.
AlphaGeometry 2 overcomes this via a neuro-symbolic hybrid architecture 3032. A neural language model based on Gemini suggests potential auxiliary geometric constructions, providing the intuitive, creative leaps necessary to unlock the problem. Simultaneously, a high-speed symbolic deduction engine receives these suggestions and performs rigorous logical deductions to verify if they lead to a complete proof 3132.
To train the neural component, DeepMind bypassed the scarcity of human-written proofs by generating an algorithmic dataset of 100 million synthetic geometry problems 3133. This massive pre-training allowed AlphaGeometry 2 to master complex relationships involving the movements of objects, equations of angles, and distance ratios 733. Before the 2024 competition, AlphaGeometry 2 was evaluated on all historical IMO geometry problems from the past 25 years, achieving a solve rate of 84% to 88%, up from the 53% rate of its predecessor 733. During the official IMO 2024 event, AlphaGeometry 2 successfully solved Problem 4 in a mere 19 seconds after receiving its formalization 7.
AlphaProof and Test-Time Reinforcement Learning
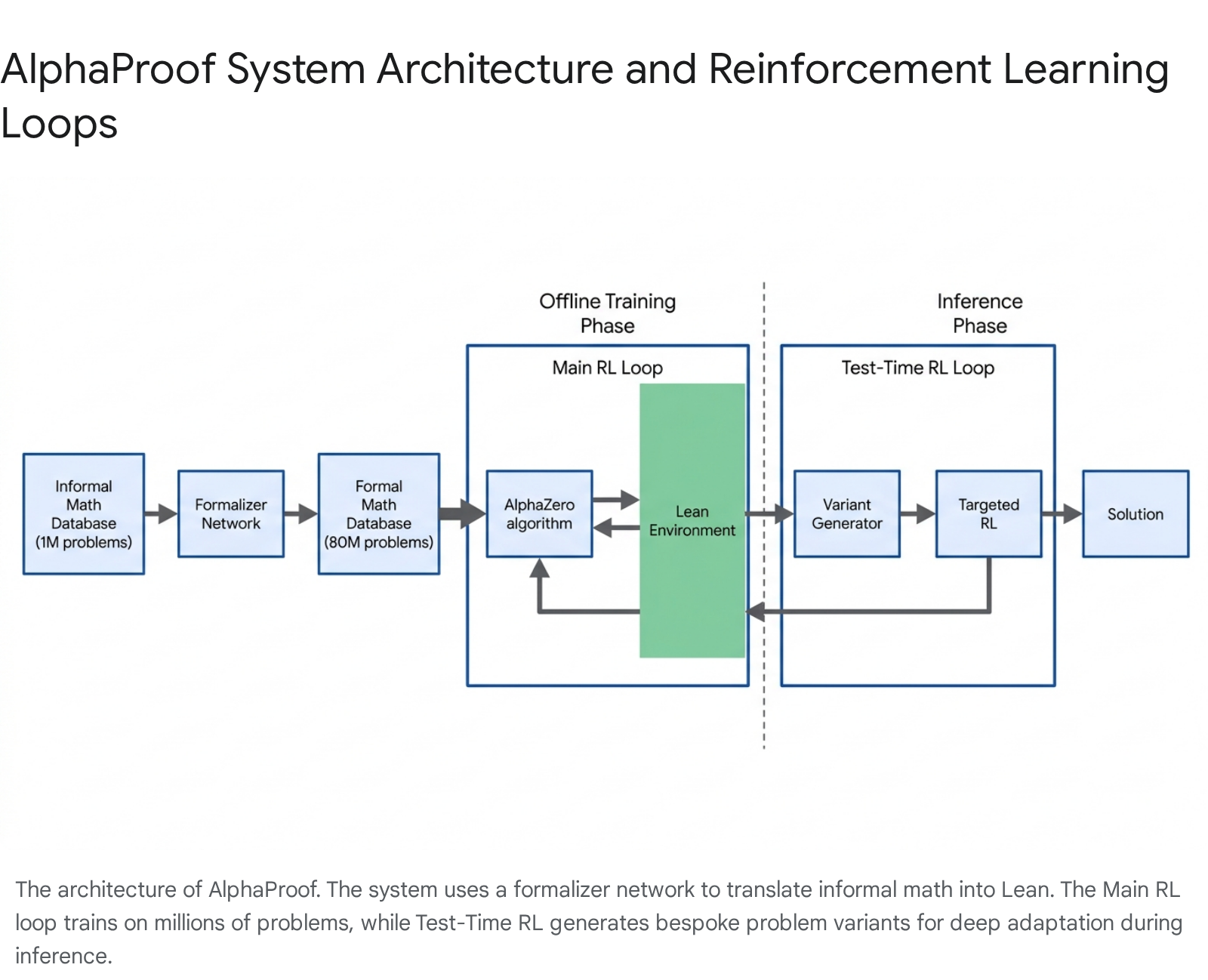
While AlphaGeometry 2 specialized in Euclidean geometry, AlphaProof was developed as a generalist reasoning engine for algebra, combinatorics, and number theory 724. AlphaProof operates entirely within the Lean formal language, utilizing a 3-billion-parameter encoder-decoder transformer model coupled with an AlphaZero-inspired reinforcement learning loop 2536.
The primary obstacle to training AlphaProof was "data finiteness" 25. There are relatively few mathematical proofs written natively in Lean. To create a sufficiently large curriculum, DeepMind first pre-trained the model on roughly 300 billion tokens of code and mathematical text, followed by fine-tuning on 300,000 human-written formal proofs from Mathlib 2026. Subsequently, an auto-formalizer network translated approximately one million informal, natural-language math problems into 80 million distinct formal Lean statements 252627. In the main offline RL loop, AlphaProof continuously attempted to prove or disprove these 80 million statements. Every proof successfully verified by the Lean kernel provided a precise reward signal, updating the neural network over a massive training phase that consumed roughly 80,000 TPU days 725.
The offline training alone, however, was insufficient to solve the most difficult IMO problems. To overcome this, AlphaProof utilized Test-Time Reinforcement Learning (TTRL) 2026. At inference time, when presented with a highly complex target problem, a variant generator creates a diverse, bespoke curriculum of millions of localized problem variations - such as simplifications or generalizations of the target theorem 2526. A specialist AlphaProof agent is then trained from scratch via RL on this specific curriculum 20. By solving easier variants, the agent uncovers the local mathematical structure and specific tactics needed to eventually conquer the main problem 2536. This process is highly computationally intensive; solving the most difficult questions required two to three days of TTRL compute, utilizing hundreds of TPU-days per problem 202528.
Performance Validation at IMO 2024
At the IMO, contestants tackle six problems worth a maximum of 7 points each, for a total of 42 points. Medals are distributed to approximately the top 50% of participants, dynamically adjusting the cutoffs so that gold, silver, and bronze are awarded in a 1:2:3 ratio 2329. For the 2024 iteration, the cutoff for a bronze medal was 16 points, silver was 22 points, and gold was 29 points .
The combined AlphaProof and AlphaGeometry 2 system achieved 28 points, solving three problems via AlphaProof (including Problem 6, which was solved by only 5 out of 609 human contestants) and one geometry problem via AlphaGeometry 2 725. Scoring perfect marks on the four problems it solved, the system fell exactly one point short of the gold medal threshold, officially placing it at the upper limit of the silver medal category 730.
The Paradigm Shift to Natural Language Reasoning
Despite the historic achievement of AlphaProof, the system suffered from a severe structural bottleneck: it lacked true autonomy. Because AlphaProof operated natively in Lean, the English-language IMO problems had to be manually translated into formal specifications by human experts before the system could begin its multi-day computation 8. Furthermore, the Lean outputs were largely incomprehensible to standard mathematical readers without formal logic training 30.
In July 2025, Google DeepMind announced a fundamental architectural pivot with an advanced version of its Gemini model running in "Deep Think" mode. This system abandoned the formal verification framework of Lean entirely, achieving state-of-the-art results operating end-to-end in natural language 6844.
Gemini Deep Think and Parallel Exploration
Gemini Deep Think was designed to mimic the cognitive workflow of human mathematicians. Instead of relying on a human-in-the-loop for translation, it directly parsed the official natural-language problem statements 845. To prevent the logical hallucinations common in unconstrained LLMs, Deep Think utilized a mechanism described as "parallel thinking." Rather than pursuing a single, brittle chain of thought, the model simultaneously explored and evaluated multiple distinct mathematical hypotheses, combining insights from various solution paths before converging on a final answer 64631.
For advanced, research-level mathematics beyond the IMO, DeepMind integrated Deep Think into a math research agent codenamed Aletheia 32. Aletheia features a natural language verifier that iteratively identifies flaws in candidate solutions, allowing the model to revise its proofs or intelligently admit failure to prevent spurious logic 32. This end-to-end framework outputs human-readable proofs akin to those found in mathematical journals, allowing human judges to assess the causal narrative directly 3045.
Performance Metrics at IMO 2025
Operating under the strict 4.5-hour session limits of the competition and without relying on external symbolic aids, Gemini Deep Think successfully solved five out of six problems at IMO 2025 444531. The system achieved a score of 35 out of 42 points, satisfying the 2025 cutoff for a gold medal and placing the AI in the top 10% of elite human competitors 844. During the same competition, OpenAI fielded a competitive natural-language reasoning model that achieved an identical score of 35 points 444631.
The success of these models confirmed an emerging scaling law: massive inference-time computation, combined with reinforcement learning for multi-step reasoning, allows natural language models to approach the logical rigor of formal systems without the latency of formal translation 4632.
However, the limits of current architectures remain visible. Gemini Deep Think scored zero points on Problem 6, the most difficult combinatorial challenge of the 2025 event, indicating that the absolute peak of human mathematical ingenuity still exceeds machine capabilities 81330. This boundary is further evidenced by benchmarks like EPOCH AI's FrontierMath, an evaluation suite of research-grade problems developed by over 60 mathematicians (including 14 IMO gold medalists and a Fields Medalist) spanning complex intersections of number theory, group theory, and algebraic geometry 33. While leading models achieve near 99% on standard olympiad qualifiers like AIME, they struggle significantly on the research-grade difficulty of FrontierMath, solving less than 40% of the Tier 4 challenges 1334.
| Evaluation Metric | AlphaProof & AlphaGeometry 2 (2024) | Gemini Deep Think (2025) | OpenAI IMO Model (2025) |
|---|---|---|---|
| Reasoning Medium | Formal Language (Lean 4) + Symbolic | Natural Language | Natural Language |
| Human Translation | Required for input/output | Fully Autonomous | Fully Autonomous |
| Execution Time | 2 to 3 days per problem | Within 4.5 hour limit | Within 4.5 hour limit |
| Verification Method | Automated (Lean Kernel) | Human IMO Judges | Human IMO Judges |
| IMO Score / 42 | 28 Points | 35 Points | 35 Points |
| Medal Equivalent | Silver | Gold | Gold |
Table 1: Comparison of milestone mathematical AI systems across recent International Mathematical Olympiads, detailing methodology and performance.
Epistemological Impacts on Mathematical Practice
The rise of automated theorem provers and natural language AI has triggered profound philosophical debates within the mathematical community regarding the nature of proof, trust, and the purpose of human mathematical endeavor.
The Concept of the Odorless Proof
In traditional mathematical practice, a proof serves two distinct purposes: establishing the objective truth of a statement and providing an explanatory narrative that imparts intuitive understanding to the reader 135135. Mathematicians evaluate proofs contextually, relying on tacit knowledge to skip routine algebra while focusing on the novel deductive leaps 953.
Formal proofs generated by systems like AlphaProof often fulfill the first purpose while abandoning the second. These machine-verified proofs can be structurally massive, containing thousands of lines of syntax, redundant steps, and inexplicable logical jumps 31354. Because they lack a causal narrative, experts refer to them as "odorless proofs" 13. They easily satisfy the strict parameters of the Lean type-checker but fail the intuitive "smell test" that a human mathematician applies to gauge mathematical elegance and deeper insight 13.
This tension is not entirely new. The history of computer-assisted proofs - such as the 1976 proof of the Four Color Theorem and Thomas Hales' Flyspeck project verifying the Kepler Conjecture - demonstrated that humans cannot adequately peer-review millions of computational cases 15536. While formal proof assistants ultimately validated these historic theorems, many mathematicians remain skeptical of their pedagogical or theoretical value, arguing that if a human cannot comprehend the proof, the underlying mathematical theory has not truly been advanced 5355. The success of Gemini Deep Think in 2025 temporarily shifted momentum back toward human-readable natural language, yet researchers emphasize that without a formal kernel, verifying the authenticity of LLM logic remains a critical vulnerability 3037.
Large-Scale Collaboration and Machine Verification
Despite readability concerns, the undeniable guarantee of correctness provided by formal systems is revolutionizing mathematical collaboration. Historically, mathematical research is a localized, small-team effort, constrained by the immense time required for human referees to rigorously check complex proofs 1051.
Formal languages like Lean allow massive, decentralized collaboration by modularizing proof architecture. Because the Lean compiler objectively verifies each lemma, researchers can contribute to a project without needing to comprehend the entire theoretical framework 38. A prominent example of this is the Equational Theories Project (ETP), launched in 2024. Over 50 contributors across the globe collaborated to completely determine all 22,028,942 implications between 4,694 equational laws on magmas 3960. Contributors utilized a combination of human formalization, automated tactics, and AI assistance, with every edge of the implication graph certified by Lean 3960.
Similarly, Fields Medalist Terence Tao utilized Lean to formalize the proof of the Polynomial Freiman-Ruzsa (PFR) conjecture. Tao has advocated for a workflow where mathematicians explain their intuitive proofs to an LLM, which acts as a co-pilot to auto-formalize the logic into Lean, allowing the formal compiler to instantly spot subtle errors or confirm optimal bounds during the drafting process 5337. In this vision, AI and formal systems do not replace the mathematician but act as an uncompromising verification infrastructure 3738.
Pedagogical Implications of Automated Provers
The integration of advanced mathematical AI into educational frameworks presents significant challenges and opportunities, challenging traditional constructivist methodologies.
Shifting Understandings of Mathematical Certainty
In educational settings, proof is often taught not merely to verify truth, but as a discovery process intended to foster critical reasoning 4041. Studies show that when students are presented with counterintuitive mathematics, engagement through peer discussion and manual calculation significantly improves conceptual understanding 4142.
The availability of instant, machine-generated proofs threatens to short-circuit this cognitive struggle. When students utilize technological tools that rapidly verify cases or provide absolute answers, they often develop an "empirical conviction" - a false sense of confidence based on external validation rather than an internalized understanding of deductive logic 4043. If an AI can instantly generate a flawless natural language proof or perfectly execute a Lean tactic, students may view the arduous process of mathematical proof as a dispensable procedural chore rather than the essence of the discipline 4044.
Integration into University Curricula
Conversely, interactive theorem provers are increasingly being introduced into university "transition to proof" modules to enforce rigor 45. Research indicates that teaching students to write in Lean mitigates common logical errors found in early undergraduate pen-and-paper proofs 4546. Because Lean requires students to explicitly define a proof strategy and provides immediate, unyielding feedback at every tactical step, it forces an engagement with formal logic that traditional grading cannot match 4546.
However, automated proof assistants were designed for research computer scientists, not as pedagogical tools 44. The syntactic complexity of dependently typed programming languages presents a steep learning curve, often conflating mathematical difficulty with programming frustration 4546. Educators must carefully balance the use of AI and formal systems to ensure that they augment, rather than replace, the development of human mathematical intuition 4144.
The trajectory of AI for formal mathematics underscores a dual reality: machines are now capable of executing deductive logic at the apex of human competitive standards, yet the semantic meaning, narrative elegance, and theoretical direction of mathematics remain profoundly human endeavors.