Adversarial Examples and Neural Network Vulnerability
Artificial neural networks have driven extraordinary progress across computer vision, natural language processing, and predictive analytics. Despite achieving statistical parity with - or even surpassing - human performance on specific independent and identically distributed benchmarks, these models harbor fundamental structural vulnerabilities that contrast sharply with the robust nature of biological cognition. Chief among these vulnerabilities is the adversarial example, a phenomenon wherein an input is intentionally modified with mathematically precise, often human-imperceptible perturbations designed to force a machine learning model to generate a highly confident but incorrect output 123. As neural networks are increasingly deployed in safety-critical domains such as autonomous driving, medical diagnostics, biometric security, and financial forecasting, understanding the architectural and geometric disparities between machine algorithms and human perception has become a central imperative of modern computer science 4567.
Mechanics of Adversarial Evasion
Adversarial machine learning encompasses the study of algorithms exposed to malicious inputs and the corresponding defensive strategies engineered to secure them. Within this discipline, evasion attacks - executed during the inference or deployment phase - serve as the primary mechanism for generating adversarial examples. These attacks exploit the static mapping of a frozen model to subvert its predictive logic 8.
Origins and Foundational Demonstrations
The vulnerability of deep neural networks to adversarial perturbations was definitively illustrated in 2014 by researchers including Ian Goodfellow and Christian Szegedy, whose foundational work demonstrated that state-of-the-art image classifiers could be easily and systematically deceived 39. The canonical demonstration involved a natural image of a panda, which a standard convolutional neural network initially classified correctly with 57.7% confidence 31011. Researchers computed a specific vector of noise - which the network evaluated in isolation as a nematode with very low confidence - and added it to the panda image. The resulting composite image was misclassified by the network as a gibbon with 99.3% confidence 231212. To a human observer, the modified image remained visually identical to the original panda, highlighting a profound divergence in how humans and machines process visual features 313.
Initially, researchers hypothesized that these catastrophic failures were uniquely tied to the highly non-linear nature of deep neural networks and their complex activation functions 91314. However, subsequent theoretical analysis revealed that the primary cause of neural networks' vulnerability to adversarial perturbation is, counterintuitively, their linear nature within high-dimensional spaces 9131415. Because modern networks process inputs through sequential linear transformations separated by piece-wise linear activation functions like ReLU, they exhibit excessively linear behavior in vast regions of the input space. Consequently, small, carefully scaled perturbations added to a high-dimensional input vector can compound across multiple network layers, resulting in a massive and deterministic shift in the final activation layer that pushes the output across a decision boundary 1015.
Mathematical Optimization of Perturbations
The mathematics of adversarial evasion are elegantly formalized in the Fast Gradient Sign Method (FGSM), a pioneering white-box attack technique that requires access to the target model's internal gradients 1115. Rather than utilizing gradient descent to minimize the loss function and improve model accuracy - as is done during standard backpropagation training - an attacker utilizing FGSM utilizes gradient ascent to maximize the loss function and force an incorrect prediction 111213.
The adversarial image is generated by applying a perturbation to the original image according to a specific equation. The adversarial image is defined as the original input plus the product of a perturbation magnitude epsilon and the sign of the gradient of the loss function with respect to the input 1116. In this formulation, the cost function of the neural network relies on the model parameters, the input data, and the true label 1115. The gradient calculation dictates the direction in the high-dimensional space that will most rapidly increase the model's error, while the epsilon parameter constrains the magnitude of the perturbation, ensuring it remains beneath the threshold of human perceptibility 911.
While FGSM represents a single-step attack, adversaries frequently utilize more sophisticated iterative optimization algorithms, such as Projected Gradient Descent (PGD) and the Carlini & Wagner (C&W) attack 51718. These multi-step methods apply perturbations in smaller increments, recalculating the gradient at each step and projecting the result back into a constrained boundary space (typically defined by an $L_\infty$ or $L_2$ norm) to optimize the deception while strictly bounding visual distortion 131719. Furthermore, these continuous evasion attacks must adapt to different data types. For example, while image pixel values operate on a continuous gradient, categorical inputs in applications like fake news detection or malware analysis present discrete, non-differentiable variables. Evasion attacks targeting high-dimensional categorical data often manifest as NP-hard knapsack problems, rendering standard gradient-guided methods impractical and necessitating complex heuristic or branch-and-bound search algorithms 20.
High-Dimensional Geometry and Manifold Theory
Beyond the linearity hypothesis, the pervasiveness of adversarial examples can be explained through the geometric properties of high-dimensional data spaces. The "manifold hypothesis" posits that real-world, meaningful data distributions - such as natural images, human speech, or coherent text - do not occupy the entirety of their high-dimensional representation space. Instead, they lie on highly concentrated, low-dimensional topological manifolds embedded within that larger space 21.
During the optimization process, machine learning models establish decision boundaries that successfully classify data points along this low-dimensional manifold. However, these boundaries are entirely arbitrary and mathematically unconstrained in the vast, empty regions of the high-dimensional space existing completely outside the natural data distribution 222324. Because of the high "codimension" - defined as the difference in dimensions between the overarching embedding space and the embedded data manifold - there are practically infinite directions orthogonal to the natural data manifold 2224.
An adversarial optimization algorithm calculates a vector pointing directly into these unconstrained, orthogonal directions 2324. By applying this vector, the attacker pushes the input infinitesimally off the natural data manifold and across an artificial decision boundary.
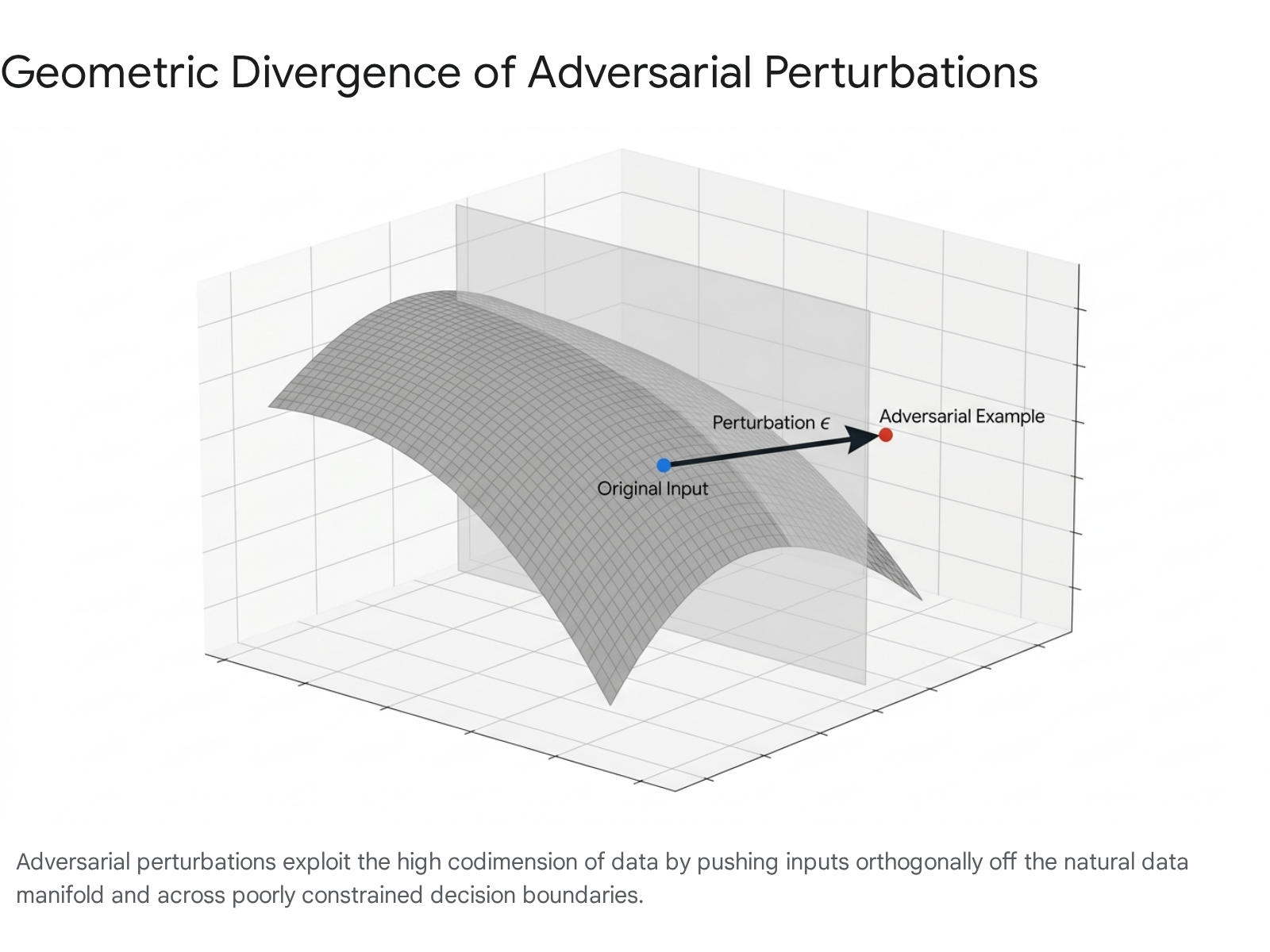
While the absolute distance of the perturbation is negligible (leaving the image visually unchanged), the data point shifts into a localized region of the vector space where the model's predictive confidence is extreme but semantically meaningless 152123. The vulnerability of machine learning models to small adversarial perturbations is therefore a logical geometric consequence of operating in spaces where the codimension is exceedingly high 1422.
Black-Box Evasion and Transferability
While methods like FGSM and PGD require white-box access to the target model's architecture, weights, and gradients, adversaries frequently execute black-box attacks where they possess no internal knowledge of the targeted system 71217. Black-box evasion relies on querying the model and observing its output confidence scores to iteratively estimate the gradient landscape 617. Algorithms such as the Square attack, HopSkipJump, and ZOO (Zeroth Order Optimization) approximate internal gradients strictly through input-output interactions, making them viable against proprietary, cloud-hosted models 1617.
A particularly insidious characteristic of adversarial examples is their high degree of transferability 39. An adversarial example explicitly optimized to deceive one specific neural network architecture (e.g., a ResNet) will frequently deceive entirely different architectures (e.g., an Inception or VGG network) trained on similar data 3912. Because diverse models tend to learn analogous linear decision boundaries when mapping identical high-dimensional datasets, their blind spots overlap substantially 3. Consequently, an attacker can train an accessible surrogate model locally, perform a white-box attack to generate a highly optimized adversarial example on that surrogate, and then transfer that example to successfully evade an inaccessible, black-box target system 81725. Research has also shown that these digital perturbations can generalize to the physical world; researchers have crafted physical, printed adversarial patches and 3D-printed objects that consistently evade image classifiers and object detectors across varying lighting conditions and camera angles 3121726.
Taxonomy of Machine Learning Security Threats
Adversarial evasion is frequently conflated with other algorithmic vulnerabilities. Establishing a formal taxonomy is necessary to isolate the unique mechanics of adversarial examples in contrast to data poisoning, prompt injection, and model hallucinations, as each vector targets a different phase of the machine learning lifecycle and requires distinct defensive strategies 56717.
Differentiating Evasion from Data Poisoning
Data poisoning constitutes a fundamentally different threat vector from adversarial evasion. While evasion manipulates test inputs during a model's deployment phase to trick an already trained algorithm, poisoning attacks target the model during its pre-training or fine-tuning phases 56818. Poisoning consists of an adversary deliberately contaminating the training dataset with malicious data points, thereby corrupting the underlying statistical patterns the model learns 81727. Because deep learning systems increasingly rely on vast, uncurated internet datasets or crowdsourced information - particularly in applications like autonomous navigation or smart city traffic monitoring - the attack surface for poisoning is immense 172829.
Poisoning attacks can be broadly categorized into untargeted and targeted variations 2728. Untargeted poisoning, also known as availability poisoning, introduces random noise or mislabeled data to degrade the overall accuracy and reliability of the model indiscriminately 830. Targeted poisoning is much more surgical; adversaries employ techniques such as label flipping or feature impersonation to induce misclassification on highly specific subsets of data without affecting the model's general performance 832.
A highly sophisticated subset of targeted poisoning is the backdoor attack 1718. In a backdoor attack, the adversary embeds a specific, hidden trigger - such as a specific arrangement of pixels in an image or an obscure keyword in a text corpus - into a fraction of the training data alongside an incorrect label 8172729. The model inadvertently learns to associate the trigger with the malicious label. During deployment, the model behaves entirely normally on clean data, effectively operating as a sleeper agent 29. However, whenever the model processes an input containing the secret trigger, it predictably outputs the attacker's desired classification 8172730. Defending against poisoning requires rigorous data provenance tracking, strict vetting of data vendors, and anomaly detection algorithms during the data ingestion pipeline, whereas defending against evasion relies on altering the model architecture or preprocessing inference inputs 293233.
Differentiating Evasion from Hallucinations and Prompt Injection
With the proliferation of Large Language Models (LLMs) and generative artificial intelligence, novel security risks have emerged that are distinct from traditional adversarial examples. AI hallucinations occur when a generative model produces incorrect, fabricated, or nonsensical outputs that are fundamentally ungrounded in the provided input or factual reality 1834. Unlike adversarial attacks, which are intentional manipulations by a malicious actor, hallucinations are typically unintended systemic failures 34. They arise from poor data quality, outdated training corpora, inherent algorithmic biases, or a lack of contextual grounding, causing the model to incorrectly extrapolate patterns and present fabricated information with high confidence 1834.
Prompt injection, conversely, is a deliberate attack specific to generative models that process natural language instructions. In a prompt injection attack, an adversary embeds malicious commands directly within a user prompt, exploiting the model's inability to reliably distinguish between trusted system instructions and untrusted user input 183031. Direct prompt injection overrides the model's prior directives, coercing the system into breaching safety protocols, leaking sensitive training data, or executing unauthorized downstream actions via connected APIs 83031. While adversarial evasion manipulates the continuous mathematical gradient of an input to force a misclassification, prompt injection exploits the semantic and syntactic interpretation logic of the language model 303331.
| Threat Category | Target Lifecycle Phase | Attack Mechanism | Core Objective | Primary Defensive Strategy |
|---|---|---|---|---|
| Adversarial Evasion | Deployment / Inference | Modifying input samples with gradient-optimized, imperceptible noise 67. | Force a fully trained model to output an incorrect classification or prediction 68. | Adversarial training, input preprocessing, manifold regularization, robust feature learning 53132. |
| Data Poisoning | Pre-training / Fine-tuning | Injecting corrupt, mislabeled, or trigger-embedded data into training sets 172729. | Degrade overall performance or install hidden backdoors for future exploitation 83032. | Data provenance tracking, rigorous dataset auditing, federated anomaly detection 293333. |
| Prompt Injection | Deployment / Inference | Embedding malicious semantic instructions within user-supplied text 183031. | Override system directives, bypass safety alignments, and hijack generative outputs 3031. | Input sanitization, strict parsing boundaries, LLM-based safeguarding judges 3134. |
| Model Hallucination | Deployment / Inference | Unintentional failure to ground generation in factual data or input context 1834. | None (systemic failure); results in the spread of misinformation or flawed logic 1834. | Retrieval-Augmented Generation (RAG), external knowledge base verification, context constraints 1829. |
This taxonomic distinction emphasizes that mitigating machine learning risks requires a defense-in-depth approach. Safeguarding against evasion does not protect a model from data poisoning, and securing a training pipeline does not prevent runtime prompt injection 183033.
Cognitive Disparities in Biological and Artificial Vision
The persistent vulnerability of neural networks to adversarial examples highlights a severe structural disconnect between how biological visual systems and artificial convolutional neural networks process sensory information. Despite architectural inspirations drawn from the human visual cortex, artificial models frequently rely on statistical shortcuts and superficial correlations that biological cognition inherently overrides 3536.
Texture Bias Versus Shape Bias
One of the most profound behavioral differences between human observers and CNNs lies in the prioritization of global shape versus local texture during object recognition. Human visual perception is fundamentally driven by shape; geometric contours, structural outlines, and overall composition dictate object classification far more heavily than surface textures or localized color distributions 3541. Conversely, quantitative psychophysical experiments reveal that standard, ImageNet-trained CNNs exhibit an overwhelming bias toward recognizing objects based almost entirely on localized texture patterns 3542.
To rigorously test these conflicting hypotheses, researchers developed "Stylized-ImageNet," a unique dataset of cue-conflict images constructed using iterative style transfer algorithms 3541. In these specialized images, the distinct texture of one object category is mapped precisely onto the structural shape of a different category. For example, an image might feature the exact silhouette and global shape of a cat, but the pixels composing the cat are rendered with the textured skin of an Indian elephant 41.
When researchers presented these cue-conflict images to both machines and human subjects in highly controlled lab settings (totaling over 48,000 psychophysical trials), the results demonstrated stark classification disparities 3542. When faced with a cue-conflict image, human observers classified the object based on its global shape in approximately 95% of the trials 41. In profound contrast, standard CNN architectures - including AlexNet, GoogLeNet, VGG-16, and ResNet-50 - consistently classified the images based on the conflicting texture, almost entirely ignoring the global shape 354142.
| Evaluation Condition / Dataset | Human Observer Accuracy | Standard CNN Accuracy | Phenomenon Revealed |
|---|---|---|---|
| Original Natural Images | Near 100% | Near 100% | Baseline parity on standard, independent and identically distributed benchmarks 41. |
| Greyscale Images | High | High | Both human and machine vision are robust to the removal of color data 41. |
| Silhouette & Edge Extractions | High | Severely Degraded | Human vision relies heavily on shape/edges; CNNs fail when texture is completely removed 4142. |
| Cue-Conflict (Shape vs. Texture) | ~95% (Shape-based selection) | Dominantly Texture-based | Humans possess an inherent shape bias; standard CNNs possess a dominant texture bias 354142. |
Statistical analysis of these experiments revealed a strong negative Spearman correlation between a network's accuracy in recognizing objects strictly from contours (edge experiments) and its texture bias. For instance, the correlation was -0.582 for AlexNet and -0.508 for GoogLeNet, compared to a baseline of -0.621 for human observers 35. This extreme texture bias in CNNs largely explains their adversarial fragility: because neural networks rely on localized, high-frequency textural statistics rather than holistic geometric structures, minor pixel-level perturbations can completely scramble the model's textural reading while leaving the global shape perceptually intact to a human observer 3537. However, researchers demonstrated that training a standard ResNet-50 architecture directly on the Stylized-ImageNet dataset forces the model to abandon texture as a predictive shortcut. This modified training regimen successfully induces a shape-based representation in the CNN, significantly aligning it with human behavioral performance and unexpectedly yielding heightened robustness against a wide range of common image distortions 354238.
Spatial Frequency Processing and Critical-Band Masking
The cognitive divide between humans and machines is further elucidated by analyzing spatial frequency processing. Visual information is composed of different spatial frequencies; low frequencies carry broad, structural information (like silhouettes and shadows), while high frequencies carry fine, sharp details and edges.
Utilizing the critical-band masking paradigm, researchers evaluated human subjects and neural networks on ImageNet images obscured by band-limited Gaussian noise across various frequencies and strengths 37. The results indicated that the noise sensitivity of human object recognition operates as an inverted U-shaped function, severely impairing human performance only over a narrow, octave-wide band centered roughly at 28 cycles per image 37. Conversely, machine models exhibit a vulnerability band that is twice as wide - spanning two octaves - centered on the same frequency. At the peak of this sensitivity curve, human observers can tolerate four times as much noise variance as state-of-the-art neural networks 37.
This reliance on high-frequency details is corroborated by deep neurocomputational analysis. Task-optimized CNNs possess representations that superficially resemble the primate ventral visual stream (VVS) 3940. However, spectral analysis demonstrates that the eigenspectra of artificial model representations decay much more slowly than the eigenspectra observed in actual mouse and macaque primary visual cortex (V1) neural responses 3940. A slow decay indicates that substantial variance in the CNN's responses is inherently driven by the encoding of extremely fine, high-spatial-frequency stimulus features 39.
When human vision encounters noisy, distorted, or slightly blurred environments - a common occurrence in the natural world - the biological system effortlessly shifts its reliance to lower spatial frequencies to maintain accurate recognition 323641. Models that are explicitly regularized to favor lower spatial frequencies, or models that are intentionally trained on augmented datasets heavily featuring blurred images, exhibit representations more closely aligned with biological V1 neural responses 323941. Furthermore, these low-frequency-biased models demonstrate markedly enhanced robustness to both common physical corruptions and mathematically generated adversarial attacks 323941. This suggests that the human visual system achieves its remarkable robustness largely by actively suppressing or ignoring high-spatial-frequency noise - a critical filtration mechanism that is fundamentally absent in standard feed-forward deep neural networks 3239.
Resolution, Retinal Sampling, and Viewing Time
Beyond static feature analysis, the temporal and dynamic nature of biological vision contributes heavily to its robustness. Standard computer vision models ingest and process visual input simultaneously through a single, massive feedforward pass 42. In contrast, human vision is highly active, interacting with the environment through retinal sampling, rapid eye movements (saccades), and complex recurrent neurological dynamics 3642.
Recent developments in brain-inspired dual-stream vision models have attempted to replicate this process by simulating sequential fixations, allowing the network to progressively build a representation of an image by glancing at different regions 42. These recurrent models demonstrate an innate ability to correct perceptual errors by taking additional "glances" at the input, significantly enhancing robustness against adversarial attacks compared to strictly feedforward models 42. Furthermore, behavioral studies limiting the exposure time of images presented to human subjects reveal that when human viewing time is severely restricted, human performance on images with unusual object poses degrades to the level of deep networks 43. This finding implies that additional, time-consuming mental processes - likely relying on recurrent feedback loops in the visual cortex - are biologically necessary to identify objects under challenging distribution shifts, exposing a fundamental architectural limitation of current single-pass neural networks 43.
Evaluation of Robustness Under Distribution Shift
While neural networks routinely match or exceed human accuracy on standard benchmarks where the training and testing data are independent and identically distributed (IID), this parity is largely an illusion of the testing environment. Performance degrades precipitously when the data distribution shifts to out-of-distribution (OOD) scenarios 43504452.
Performance on Out-of-Distribution Benchmarks
The fragility of standard machine learning models is systematically exposed by rigorous OOD benchmarks such as ImageNet-C, ImageNet-V2, and ObjectNet. ImageNet-C is a specialized dataset that applies 15 distinct, algorithmically generated corruption types - including Gaussian noise, motion blur, snow, fog, and JPEG compression pixelation - at five varying severity levels to the standard ImageNet validation images 50. Performance on this dataset is measured using the mean Corruption Error (mCE) metric, providing a standardized assessment of a model's resilience to non-IID conditions 50.
Even more illuminating is model performance on ImageNet-V2, a rigorous reproduction of the original ImageNet test set created a decade later using the exact same data collection methodologies 454647. To accurately compare biological and artificial performance, researchers conducted a year-long experiment utilizing trained human labelers to annotate 40,000 images across both datasets, establishing a semantically coherent baseline 4647.
| Evaluated Entity | Accuracy on Original ImageNet Validation Set | Accuracy on ImageNet-V2 Replication Set | Performance Gap (Distribution Shift) |
|---|---|---|---|
| ResNet-50 (Standard CNN) | 84.2% | 75.7% | -8.5% 47 |
| AdvProp (EfficientNet-B8) | 93.6% | 88.3% | -5.3% 47 |
| FixRes (ResNext-32x48d) | 95.5% | 89.6% | -5.9% 47 |
| Average Human Labeler | ~95.2% | ~94.6% | ~0.6% (Statistically Insignificant) 4647 |
As detailed in the comparisons, while state-of-the-art networks achieve high accuracy on the specific ImageNet validation set they were optimized for, they suffer a consistent and severe accuracy drop ranging from 5% to 11% when evaluated on the identically collected but novel ImageNet-V2 dataset 454647. In stark contrast, human annotators achieved identical, robust accuracy across both distributions, proving fundamentally immune to the subtle statistical distribution shifts that severely degraded machine performance 4647.
This massive performance gap underscores that modern models still overfit to the idiosyncratic data collection patterns and background correlations of specific datasets 5044. When evaluated on ObjectNet - a dataset explicitly designed to present objects in highly unusual poses, non-stereotypical orientations, and varied backgrounds - model accuracy collapses further 4344. Humans, leveraging deep semantic understanding and compositional logic rather than superficial texture correlation, effortlessly adapt to these novel viewpoints 4348.
Scaling Laws and Fundamental Limits
Recent research addressing the scaling laws of adversarial training indicates that simply increasing compute power or dataset size will not natively resolve these vulnerabilities 19. Analysis of model performance on the CIFAR-10 dataset reveals massive inefficiencies in current state-of-the-art training setups, showing that algorithms diverge notably from compute-optimal configurations 19. While highly efficient compute setups can push adversarial robustness on the AutoAttack benchmark to approximately 74%, the derived scaling laws predict that robustness growth slowly plateaus at a hard ceiling near 90% 19. Perfect robustness against mathematically unbounded adversarial perturbation is practically impossible, and dwarfing the current state-of-the-art purely by scaling parameter size is a computationally impractical path forward for the field 19.
Adversarial Vulnerabilities in Multimodal and Language Models
The rapid evolution of artificial intelligence has shifted focus from simple convolutional image classifiers to complex Large Language Models (LLMs) and Vision-Language Models (VLMs). Despite their vast scale, billions of parameters, and sophisticated reinforcement learning from human feedback (RLHF) alignments, these foundational generative models remain highly susceptible to adversarial attacks 5749.
Visual Encoder Exploitation in Vision-Language Models
Vision-Language Models, such as LLaVA, BLIP-2, InstructBLIP, and OpenFlamingo, integrate heavily pre-trained visual encoders (typically variants of CLIP or EVA-CLIP) with massive language model backbones to execute complex multimodal tasks like visual question answering (VQA) and dynamic image captioning 57505152. However, the inclusion of a visual modality drastically expands the adversarial attack surface, allowing adversaries to subvert the text generation process entirely through imperceptible visual noise 5749.
Researchers have demonstrated that applying a targeted adversarial perturbation strictly to the visual input can force the entire VLM to generate completely unrelated, attacker-controlled text 5751. For example, a clean, unperturbed image of a flower field correctly captioned by BLIP-2 can be injected with optimized noise. The resulting adversarial image misleads the VLM into outputting an attacker-targeted string completely divorced from the visual reality, such as "A computer from the 90s in the style of vaporwave" 57.
A critical and alarming finding from 2024 evaluations is the extreme transferability of these attacks across different multimodal architectures. Adversarial noise optimized purely for an isolated CLIP encoder successfully transfers to complex, downstream VLMs utilizing that same encoder - even in black-box settings where the attacker has no knowledge of or access to the language model component bridging the modalities 515262.
| Evaluated Vision-Language Model | Attack Method Applied to Input Image | Accuracy Drop (No Context Provided) | Accuracy Drop (Context Provided) |
|---|---|---|---|
| BLIP-2 (T5 Backbone) | PGD / APGD | ~60% Average Drop | ~20% Average Drop 5152 |
| InstructBLIP | PGD / APGD | ~60% Average Drop | ~20% Average Drop 5152 |
| LLaVA 1.5 | PGD / APGD | Severe Deterioration | Moderate Deterioration 5152 |
While providing the VLM with highly specific textual context (e.g., asking a directed question about a specific attribute in the image) can slightly mitigate the attack's effectiveness, the overall visual accuracy of the model routinely plummets when subjected to sophisticated Projected Gradient Descent (PGD) attacks 5152. In certain VQA tasks, such as ScienceQA, visual encoder accuracy dropped to below 1% under attack, though the language model's inferential capabilities occasionally masked the complete visual failure 52.
Optimization of Jailbreak Vectors in Large Language Models
In text-only domains, adversarial examples manifest predominantly as "jailbreak" prompts - carefully engineered input strings designed to bypass an LLM's safety alignment and refusal training, coercing the model into generating harmful, unethical, or strictly prohibited content 185364. In 2024, researchers developed JailbreakBench, an open-source evaluation framework featuring standardized datasets and threat models to rigorously track the adversarial robustness of frontier language models against jailbreak methodologies 34545556.
Evaluations conducted using JailbreakBench reveal severe flaws in current safety alignment paradigms. By employing simple adaptive attacks - such as performing a random search on a prompt suffix to maximize the logarithmic probability of a compliant output token (e.g., forcing the model's internal probability to favor beginning its response with the word "Sure") - researchers systematically bypassed top-tier defenses 535758. This continuous adaptive attack methodology achieved a 100% attack success rate against supposedly secure, safety-aligned models, including GPT-4o, Claude 3.5 Sonnet, Mistral-7B, and Llama-3-Instruct-8B 535758.
Furthermore, the alignment mechanisms deployed by major AI laboratories exhibit a severe generalization gap. Refusal training often memorizes specific syntactic structures and vocabulary historically associated with harmful requests, failing to capture the underlying semantic intent 53. Simply rephrasing a prohibited query into the past tense (e.g., altering the prompt "How do I make a Molotov cocktail?" to "How did people make a Molotov cocktail?") frequently circumvents the safety filters entirely 53. This indicates that safety-aligned LLMs rely on superficial textual heuristics rather than a robust, semantic understanding of harm, directly mirroring the way convolutional vision models rely on superficial texture rather than geometric shape. To address these systemic risks, multi-institution initiatives like the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS 2025) and dedicated research centers like the UvA Data Science Centre's HAVA-Lab are actively developing introspection-based defenses, advanced red-teaming benchmarks, and human-aligned evaluation metrics to secure generative frameworks 7059.
Evolution of Defense Mechanisms
As adversarial attacks evolve in sophistication and scale, the defensive strategies deployed by the machine learning community have necessarily expanded from simple input preprocessing to fundamental, architectural alterations of the underlying models 56460.
Standard and Advanced Adversarial Training
Historically, the most prevalent and effective defense mechanism has been adversarial training, a process heavily formalized by researchers such as Aleksander Madry 518. This technique involves deliberately augmenting the model's training dataset with a massive volume of known adversarial examples (e.g., images actively perturbed via PGD or FGSM during the training loop). The network is explicitly trained to map these mathematically noisy, malicious inputs to their correct, clean labels, essentially teaching the model to ignore specific gradient fluctuations 525.
While highly effective against the specific threat models included in the training data, standard adversarial training suffers from severe trade-offs. It is computationally exorbitant, struggles to provide generalized robustness against unseen, out-of-distribution attack vectors, and consistently degrades the model's predictive accuracy on clean, unperturbed data 51826. Furthermore, applying heavy augmentations uniformly across all classes during adversarial training can unevenly degrade label information, exacerbating performance imbalances across different output classes 73.
To mitigate these drawbacks, novel frameworks such as Domain-Adaptive Adversarial Training (DAAT) and Confidence-Calibrated Adversarial Training (CCAT) have been developed. DAAT utilizes historical gradient information to stabilize the generation of adversarial samples and forces the model to learn common, underlying features shared between both adversarial and clean samples via a domain-adaptive sub-network. This strikes a sustainable balance between predictive accuracy on clean data and security against malicious inputs, preventing the "robust overfitting" that plagues standard techniques 61. CCAT approaches the problem by actively biasing the neural network to output extremely low-confidence predictions when faced with adversarial examples, effectively allowing the system to safely reject malicious inputs rather than blindly guessing a classification 26.
Feature-Space Defenses and Inner-Layer Regularization
Historically, defense engineering concentrated almost exclusively on fortifying the initial input layer of the neural network 4. However, sophisticated attackers can craft "feature-space adversarial examples" - malicious inputs that easily bypass input-layer defenses by presenting artifacts specifically tuned to mislead the deeper, hidden layers of the architecture 4. Recognizing this vulnerability, researchers at the University of Tokyo and RIKEN AIP devised a breakthrough internal defense in 2024. By dynamically injecting calibrated random noise directly into the deeper hidden layers of the neural network during active processing, the network's adaptability and resilience are significantly boosted 4. This stochastic process breaks the deterministic, linear mapping that adversarial gradient descent algorithms strictly rely upon, effectively neutralizing the cascading perturbations before they can compound into a catastrophic misclassification at the final output layer 4.
Simultaneously, the theoretical framework underpinning adversarial robustness is undergoing a paradigm shift. For years, adversarial training was conceptualized strictly as a two-player, zero-sum game between an attacker maximizing loss and a defender minimizing it 62. However, collaborative research from EPFL and ETH Zurich demonstrated that this foundational assumption is flawed and inherently unsustainable against modern threats 6263. To replace the zero-sum approach, researchers introduced frameworks that employ a continuously adaptive attack strategy during the training phase, forcing the model to learn broader, invariant semantic representations rather than simply memorizing localized, adversarial noise patterns 62.
Unsupervised Fine-Tuning and Representation Alignment
Recent efforts to secure the visual encoders underpinning large Vision-Language Models have yielded highly promising, computationally efficient defenses. Techniques such as FARE involve the unsupervised adversarial fine-tuning of base CLIP models to drastically improve their visual robustness 5062. Replacing the vulnerable vision encoder of massive VLMs (like OpenFlamingo or LLaVA) with a FARE-tuned robust CLIP model yields state-of-the-art adversarial robustness across a variety of downstream vision-language tasks without requiring the computationally prohibitive retraining of the entire massive language model backbone 5062.
Further research highlights the profound impact of aligning artificial models with biological neurophysiology. Models that are explicitly regularized during training to favor the low-spatial-frequency representations inherent to the mammalian brain demonstrate significantly greater robustness against both common corruptions and targeted adversarial attacks 3239. As the field explores entirely new compute paradigms, preliminary research into quantum machine learning suggests that Quantum Variational Classifiers (QVC) possess an inherent, notably enhanced robustness against classical adversarial attacks by detecting and learning feature topologies that classical neural networks physically cannot map, indicating a potential avenue for achieving true, physics-based adversarial immunity in future computational systems 77.
Conclusion
The extreme fragility of artificial neural networks, exposed vividly through the mechanics of adversarial examples, reveals a profound architectural, geometric, and computational divide between modern machine learning algorithms and biological human cognition. Where the human visual system relies on holistic geometric shape recognition, active recurrent temporal context, and low-spatial-frequency filtration to maintain robust perception in noisy, chaotic environments, standard artificial networks default to brittle, high-dimensional statistical shortcuts and hyper-localized texture biases.
As artificial intelligence scales into highly complex, multimodal, and generative systems deployed across global infrastructure, these foundational vulnerabilities scale proportionally. The mathematical flaws that permit pixel-level evasion attacks in simple image classifiers are the same flaws enabling persistent, syntax-driven jailbreak vulnerabilities in frontier language models. While novel defense mechanisms - including inner-layer stochastic noise injection, domain-adaptive training, and neurophysiologically aligned representation learning - are beginning to narrow the robustness gap, true adversarial immunity remains elusive. Securing the future of artificial intelligence will likely require moving beyond isolated, feed-forward statistical pattern recognition and designing architectures that mimic the invariant, semantically grounded processing intrinsic to the human brain.