Activation Patching in Neural Networks
The attempt to decode the internal computations of deep learning models has coalesced into the field of mechanistic interpretability. The primary objective of this discipline is to reverse-engineer trained neural networks by mapping internal circuits, features, and weights into human-understandable algorithms 12. Unlike behavioral interpretability, which analyzes input-output relations, or concept-based interpretability, which identifies high-level representations governing behavior, mechanistic interpretability is a bottom-up approach that aims to uncover the precise causal mechanisms transforming inputs into outputs 12. Within this framework, localization - the isolation of specific computational components responsible for distinct behaviors - is a foundational step. Activation patching has emerged as the standard technique for this localization process 344.
Activation patching, frequently referred to in the literature as causal tracing, interchange intervention, or causal mediation analysis, evaluates the causal role of internal model components by swapping intermediate activations between different model forward passes 3567. Unlike purely observational techniques, such as probing or attention visualization, activation patching isolates the necessity and sufficiency of specific computational nodes 89. By observing how these interventions shift the model's output probabilities, researchers can reconstruct the causal computational subgraphs governing artificial cognition.
Theoretical Foundations of Interventional Interpretability
The fundamental premise of activation patching relies on treating a neural network as a structural causal model 2910. In a transformer architecture, the output of each layer is added to a residual stream, meaning the input to any subsequent layer is the exact sum of the outputs of all preceding components 11. This linear structure permits the isolation of specific nodes (such as attention heads or multi-layer perceptrons) or edges (the connections between nodes) in the computational graph 1112.
The Tripartite Procedural Framework
The standard activation patching protocol requires three distinct forward passes of the neural network to isolate a causal mechanism 713.
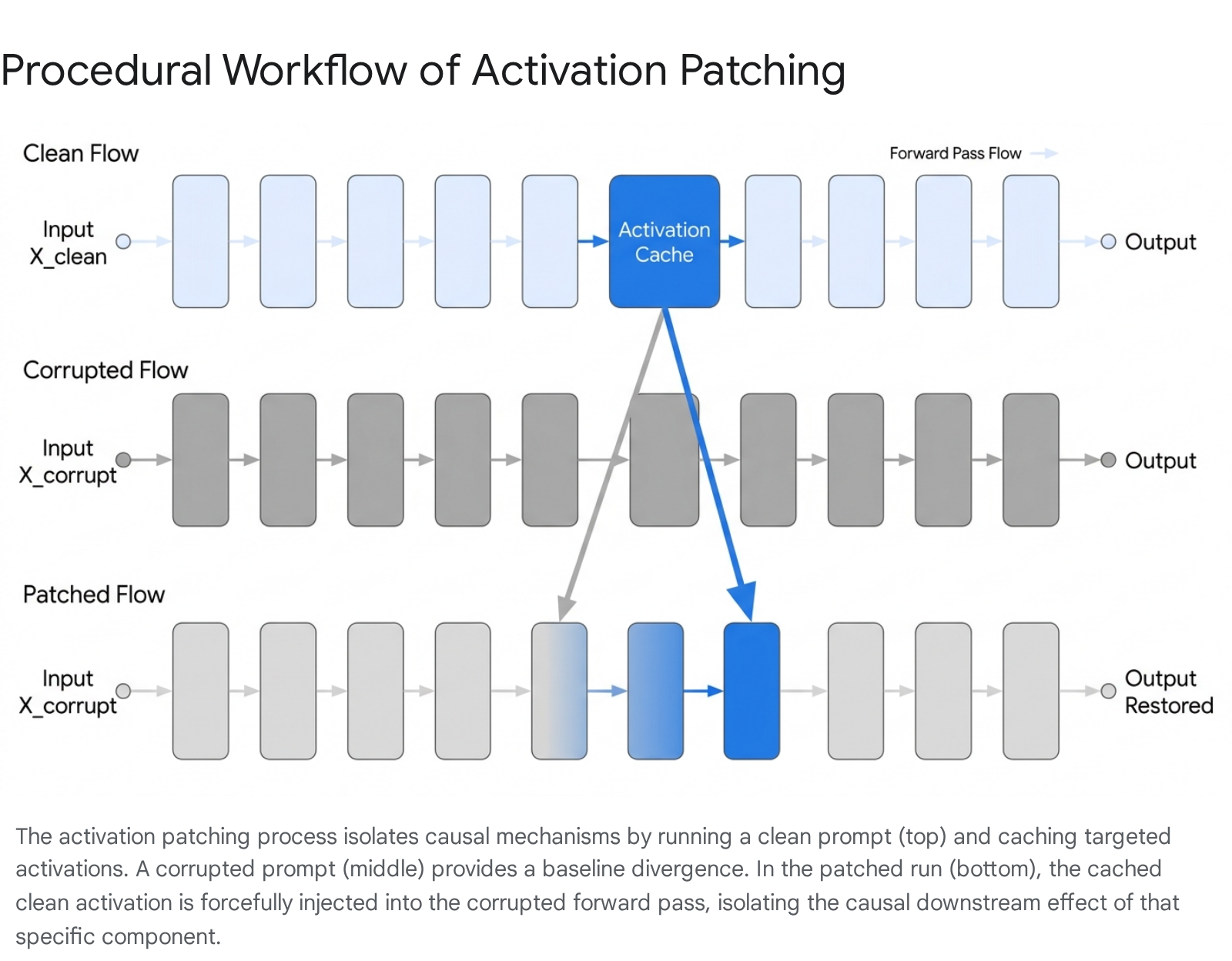
First, the model processes a primary prompt (the "clean" input), which elicits the target behavior. During this pass, the intermediate activations of the targeted neural components - such as the output of a specific layer's feed-forward network or the attention pattern of a specific head - are cached in memory 713.
Second, the model processes a counterfactual prompt (the "corrupted" input). This prompt is structurally identical to the clean prompt but differs in one critical semantic detail, ensuring that the target behavior is not elicited 56. For example, if the clean prompt is "The Eiffel Tower is in," the corrupted prompt might be "The Colosseum is in." The base output of this corrupted run is recorded to establish a baseline performance divergence 13.
Third, the model processes the corrupted prompt a second time. However, upon reaching the targeted component, the model's naturally generated activation is forcefully overwritten with the exact activation tensor cached during the clean run 713. By measuring the divergence of this patched run's output from the corrupted run's base output, researchers quantify the causal effect of the patched component 815. If patching a single attention head shifts the output from the corrupted state to the clean state (e.g., shifting the output prediction from "Rome" back to "Paris"), that head is deemed causally sufficient for the target behavior 513.
Counterfactual Generation and Corruption Methods
The choice of the corrupted prompt determines the specific causal counterfactual being tested. Variations in methodology significantly impact interpretability outcomes, leading researchers to systematically evaluate the most reliable techniques for generating corrupted inputs 3413. The literature identifies two primary approaches to generating corrupted inputs, each with distinct statistical implications.
Gaussian Noising adds a large, homoscedastic Gaussian noise vector directly to the token embeddings of the critical subjects within the prompt 313. While computationally straightforward and easily automated, Gaussian noising often forces the model's hidden states far off the manifold of its training distribution. This off-distribution shift can lead to uninterpretable or artifactual network behavior 314. Furthermore, the intervention may fail entirely if the magnitude of the model's normal activation vastly exceeds the scale of the injected noise, resulting in false negatives during localization 14.
Symmetric Token Replacement swaps the key tokens with semantically related, in-distribution tokens (for example, replacing "The Eiffel Tower" with "The Colosseum") 313. This strategy ensures that the model remains within its operational distribution while effectively removing the target information. Comparative analyses indicate that Symmetric Token Replacement yields more reliable and ecologically valid interpretability results than Gaussian noising, making it the preferred methodology for rigorous circuit discovery 3.
Evaluation Metrics for Interventions
To quantify the shift in model behavior during a patched run, continuous mathematical metrics are heavily favored over discrete accuracy checks. Continuous metrics provide high-resolution gradients of change, allowing researchers to detect subtle compensatory mechanisms or partial causal effects.
The most straightforward metric is absolute probability, which measures the absolute shift in the predicted probability of the target token 13. However, absolute probability can be skewed by general network confidence levels. A more robust alternative is Kullback-Leibler divergence, which measures the overall shift in the full output distribution rather than just specific target tokens, providing a holistic view of the intervention's impact 8.
The current standard in mechanistic interpretability is the logit difference. This metric measures the relative gap between the target token's logit and the corrupted token's logit 613. Taking the logit difference controls for circuits that generically decide whether to output a certain class of tokens (such as deciding to output any human name) regardless of the specific context 6. When utilizing logit difference, researchers typically normalize the patched effect against the baseline gap between the clean and corrupted runs. This normalization yields a score typically bounded between 0 and 1, where 1 indicates complete restoration of the target behavior and 0 indicates performance identical to the corrupted run 13.
Variants of Patching Techniques
The foundational activation patching technique has evolved into a taxonomy of distinct methodologies, each tailored to answer different causal questions or overcome specific computational constraints.
Directionality and Causal Framing
Activation patching can be applied in two primary directions, each addressing distinct causal hypotheses regarding the model's circuitry 515.
| Methodology Variant | Direction of Transfer | Causal Interpretation | Primary Use Case |
|---|---|---|---|
| Denoising (Causal Tracing) | Clean to Corrupted | Sufficiency: Identifies components that contain enough information to reconstruct the target behavior when injected into a baseline state. | Discovering primary computational circuits; verifying circuit completion 5615. |
| Noising (Resample Ablation) | Corrupted to Clean | Necessity: Identifies components whose removal actively breaks the model's ability to perform the target behavior. | Measuring component criticality; identifying single points of failure in circuits 5614. |
Measuring "sufficiency" via denoising is generally considered stronger evidence of a component's specific operational role than measuring "necessity" via ablation. Necessity can simply indicate a dependency on general network health, basic grammatical formatting structures, or upstream data routing, rather than the execution of the specific semantic computation under investigation 56.
Attribution Patching and Gradient Approximations
Despite its analytical power, exact activation patching scales poorly. Computing the exact causal effect of every node in a neural network requires a separate forward pass for each node evaluated 515. For fine-grained localization - such as analyzing every individual neuron or attention head across a massive model like the 70-billion parameter Chinchilla architecture - this methodology quickly becomes computationally intractable, requiring thousands of sequential forward passes 516.
To circumvent this computational bottleneck, researchers introduced Attribution Patching. This technique leverages the first-order Taylor series expansion to linearly approximate the causal effect of an activation patch using gradients 1517. The mathematical formulation approximates the change in a metric for a given node by taking the element-wise product of the activation difference (between the clean and corrupted states) and the gradient of the loss with respect to the activation evaluated at the corrupted state 51718.
Because standard backpropagation computes the gradient for all internal nodes simultaneously, Attribution Patching can estimate the impact of intervening on every single network component using only two forward passes (one clean, one corrupt) and a single backward pass (on the corrupt state) 515. This provides orders-of-magnitude improvements in processing speed and enables automated circuit discovery algorithms.
Pathologies of Linear Approximations
While highly efficient, Attribution Patching relies on a linear approximation of a deeply nonlinear system, leading to systematic failure modes 51819. These are not random statistical errors, but structural blind spots caused by the transformer architecture.
- Softmax Saturation: If a critical attention head is highly confident (e.g., an attention probability exceeding 0.95), the gradient of the softmax function mathematically approaches zero 18. Consequently, the attribution patch estimate will calculate a near-zero causal effect. This yields a severe false negative, flagging a highly important component as irrelevant 18.
- Zero-Gradient Regions: If the corrupted input lands in a flat region of the loss landscape - such as when the model makes a highly confident but incorrect prediction - the gradients throughout the network shrink. This suppresses the estimated importance of all upstream nodes, regardless of their actual causal role 18.
- Cancellation Effects: In deep architectures, positive and negative gradient signals from different layers may destructively interfere. This interference masks the true magnitude of an activation's influence when summed over the residual stream 18.
To address these limitations, algorithmic variants such as AtP have been developed. AtP mitigates the cancellation effect by applying GradDrop, which selectively zeroes gradient contributions from different layers and averages the absolute values 1819. Furthermore, it resolves softmax saturation by exactly computing the attention pattern changes rather than attempting to linearize through the highly non-linear softmax layer 171819. While these corrections require a fractional increase in forward passes, they preserve the profound asymptotic efficiency gains over exact activation patching 1819.
Path Patching and Causal Scrubbing
Treating a network strictly as a collection of nodes (individual layers or attention heads) is conceptually limiting, as a single node may participate in dozens of different functional circuits simultaneously 11. The shift toward graph-theoretic evaluation has led to Path Patching and its efficient gradient variant, Edge Attribution Patching. These techniques target the specific flow of information between two nodes (the edges) rather than the nodes themselves 69122021. Path patching isolates how components communicate by replacing activations only along the precise sub-path of interest, freezing the rest of the network 12.
This logic of tracing specific computational paths has been formalized by Redwood Research into an overarching methodology called Causal Scrubbing 11121420. Causal scrubbing rigorously tests structural hypotheses about a neural network. Instead of zeroing activations or applying random Gaussian noise, the algorithm systematically resamples activations from an entirely different dataset distribution 1214. It scrubs away every causal relationship that the researcher's hypothesis claims is irrelevant to the task 111422. If the model's performance on the target metric remains intact despite the massive injection of off-distribution noise into all supposedly "irrelevant" paths, the proposed causal circuit is empirically validated for completeness and faithfulness 1422.
Neural Redundancy and the Hydra Effect
Mechanistic interpretability historically operated under the assumption that neural circuits were structurally rigid - analogous to fixed, compiled code in traditional software engineering 12326. However, advanced activation patching experiments have repeatedly demonstrated that neural representations are dense, distributed, and highly dynamic.
The Superposition Hypothesis and Polysemanticity
The interpretation of patched activations is severely complicated by the phenomenon of polysemanticity. Transformers often encode features in "superposition," meaning the network represents more discrete semantic concepts than it possesses mathematical dimensions by mapping these concepts to almost-orthogonal linear combinations of neurons 1222425. Consequently, an individual neuron rarely represents a single, human-interpretable concept; it fires for a variety of seemingly unrelated inputs 2324.
When researchers patch a raw activation vector within the residual stream, they are simultaneously intervening on dozens of entangled features 2425. This dense clustering makes it difficult to ascertain which specific semantic concept drove the observed change in model behavior, often muddying the results of causal tracing 625.
Compensatory Mechanisms: Preemption
The assumption of rigid circuitry is further undermined by the discovery of compensatory network dynamics, formally known in the causality literature as preemption, and colloquially within the interpretability domain as the "Hydra effect" 110232630.
When a critical component (such as an early attention layer responsible for factual retrieval) is surgically ablated or significantly altered via patching, the network frequently does not suffer a catastrophic failure of the target behavior 2326. Instead, the network exhibits emergent self-repair.

Later layers - which were entirely dormant during the unperturbed forward pass - detect the missing information, dynamically re-route the computational load, and compensate for the ablated components 2326.
This self-repairing nature of large language models indicates intense serial and parallel redundancy 62331. In ablation studies using the Chinchilla language model, researchers observed that ablating certain attention layers caused immediate, localized downstream compensation by subsequent attention heads 2630. Simultaneously, late Multi-Layer Perceptron layers act as counterbalances, downregulating maximum-likelihood tokens to stabilize the output distribution 2630. Furthermore, layer-ablation tests across multiple models reveal deep structural depthwise redundancy, implying that models iteratively refine overlapping representations throughout their depth rather than computing entirely novel features at each discrete sequential layer 32.
Because of the Hydra effect, standard single-node activation patching or simple ablation may yield severe false negatives. A component might be causally sufficient and primarily responsible for a behavior, but appear mathematically unnecessary because the network immediately masks its removal by routing around the damage 61026. This necessitates the deployment of advanced, multi-node patching techniques and edge-level attribution to accurately map computational circuits.
Integration with Dictionary Learning
To overcome the profound barriers of polysemanticity and redundancy, the current frontier of mechanistic interpretability integrates activation patching with Sparse Autoencoders and shifts analysis from raw model activations to dictionary latents.
Sparse Autoencoders and Latent Patching
Sparse Dictionary Learning, implemented via Sparse Autoencoders, expands the original activation space of a neural network into a higher-dimensional, overcomplete basis. During training, the autoencoder enforces a strict L1 penalty to ensure sparsity, forcing the model to represent complex inputs with only a few active dimensions 124253334. The resulting autoencoder latents represent disentangled, highly specific, and theoretically monosemantic concepts that humans can easily interpret 242535.
Rather than patching a raw, polysemantic residual stream vector, modern interpretability protocols patch specific sparse latents. Because autoencoders are trained to map activations to themselves with high fidelity, splicing a trained autoencoder into a foundational model acts as a lossless interpretability bottleneck 2533. In "Patchscope" methodologies, researchers generate an explanation or behavior from a model and then intervene on specific sparse latents to see if the semantic meaning shifts predictably 25.
Recent experiments demonstrate that applying interventions to these latents yields highly precise behavioral control. Focusing strictly on the single highest-activated sparse latent (Top-1 steering) provides a more interpretable and stable causal steering vector than aggregating the Top-K features 35. Aggregating multiple top features often inadvertently injects non-semantic noise (such as dimensions tracking punctuation or structural formatting) and destabilizes the generation of multi-step reasoning 35.
Factual Localization and Model Editing
A primary application of activation patching is the localization and targeted editing of factual knowledge. Initial studies localized the storage of specific factual associations (e.g., "The Eiffel Tower is located in Paris") primarily to the mid-layer Multi-Layer Perceptrons of transformer models 203627.
Editing Algorithms: ROME and MEMIT
This precise localization led to the development of the Rank-One Model Editing (ROME) algorithm. ROME treats Multi-Layer Perceptron sublayers as key-value associative memories 362738. By performing causal tracing to identify the exact layer where a fact is recalled, ROME computes a precise rank-one update to the weight matrix of that single layer, mathematically forcing the model to associate a specific subject (the key) with a newly desired fact (the value) 2738.
However, ROME degrades quickly when applied to more than a few facts, suffering from severe performance drops after roughly ten edits 36. This limitation prompted the development of Mass-Editing Memory in a Transformer (MEMIT) 363839. MEMIT addresses the instability of single-layer updates by distributing the factual update vector across a range of continuous layers (typically layers 3 through 8 in GPT-J), resolving mathematical conflicts through complex batch updates 363839. This spatial dispersion significantly reduces the localized interference that destroys models under ROME, allowing researchers to execute thousands of simultaneous factual injections without immediate model collapse 39.
The Isolated Storage Misconception
Despite the engineering success of these advanced editing techniques, rigorous mechanistic research critiques the underlying assumptions of localized factual storage. The belief that facts are stored in isolated, easily swappable silos within specific layers is largely a misconception 362738.
| Failure Mode of Factual Editing | Mechanistic Description | Practical Implication |
|---|---|---|
| Directional Failure | Edits lack bidirectional generalization. Injecting the fact that the Eiffel Tower is in Rome allows the model to answer "Where is the Eiffel Tower?" but it fails to accurately respond to "Name a famous tower in Rome" 36. | The specific token association is edited, but the abstract conceptual relationship and underlying knowledge graph are not intrinsically reorganized 362739. |
| Absence of Ripple Effects | Activating an edit does not universally update the logical consequences of that edit across the network's latent knowledge structures 3839. | Editing the UK Prime Minister's identity will not necessarily update the model's knowledge of the Prime Minister's spouse, causing severe logical inconsistencies in multi-turn dialogues 3839. |
| Catastrophic Forgetting | As sequential edits accumulate, models experience an initial progressive forgetting of older edits, followed by an abrupt, catastrophic collapse of general downstream capabilities 3828. | Factual associations are intrinsically distributed across overlapping parameter matrices; continuous surgical interventions eventually destabilize the underlying multi-dimensional manifold 3828. |
These findings suggest that while activation patching can find a primary node for a factual recall, the total representation of that fact is deeply distributed. Intervening on a single node provides a superficial patch rather than a fundamental rewiring of the model's worldview.
Scalability and Advanced Modalities
As artificial intelligence rapidly advances, mechanistic interpretability techniques originally designed for small models face intense pressure to scale to frontier architectures, handle long context windows, and interpret multimodal inputs.
Frontier Model Scaling
Recent investigations into large-scale models, notably the 70-billion parameter Chinchilla architecture, demonstrate that the core suite of activation patching, logit attribution, and attention visualization remains functional at scale 16414243. In tasks requiring emergent algorithmic capabilities - such as identifying the correct letter label in a multiple-choice question format given knowledge of the answer text - researchers successfully mapped the terminal steps of the computational circuit 1643.
However, scaling does not equate to simplicity. While the broad algorithmic framework was identifiable, the specific feature representations within the attention heads remained mathematically messy and heavily polysemantic 164143. The success of the patching techniques proves that mechanistic interpretability is not merely an artifact of small-scale models, but it highlights that larger architectures exhibit significantly more complex internal hierarchies, requiring highly robust automated tools to untangle 3141.
Long Context Attention Scaling
Modern language models feature context windows extending from hundreds of thousands to millions of tokens. Traditional activation patching scales quadratically with context length in the attention mechanism, leading to impossible computational overhead. For instance, caching full attention patterns for a 100,000-token prompt requires terabytes of GPU memory, placing long-context interpretability out of reach for standard hardware 4429.
Recent literature has introduced solutions such as Sparse Tracing and the Stream algorithm 4429. Stream employs a compilable, hierarchical pruning framework that estimates per-head sparse attention masks, effectively discarding 90% to 99% of non-essential token interactions while preserving the model's exact next-token behavior 4429. By performing a binary-search-style refinement, the algorithm retains only the top-K key blocks that are causally critical, reducing computational time complexity to $O(T \log T)$ and space complexity to linear $O(T)$ 4429. This mathematical compression enables one-pass interpretability at massive scale, allowing researchers to causally trace information flow across vast documents.
Multi-Step Reasoning and Diverse Modalities
Researchers are increasingly applying activation patching to understand how models execute "System 2" multi-step logic entirely within their hidden states, without generating explicit chain-of-thought text 46473031. Cross-query semantic patching reveals that models perform staged, implicit computations layer-by-layer 4730. For example, in implicit two-hop reasoning tasks, models transition through distinct internal phases, localizing the extraction of a "bridge entity" in the mid-layers before generating the final combined output 4730. Errors in reasoning frequently stem from later layers overemphasizing the intermediate bridge entity, which suppresses the final required concept 47.
Mechanistic interpretability has also broadened to Vision Language Models and cross-lingual architectures 5032. In Vision Language Models, activation patching is utilized to discover how discrete visual patches integrate into semantic language feature spaces, although the dynamic integration processes remain significantly less understood than pure language models 5033. In cross-lingual research, attribution patching maps the specific multi-layer perceptron parameters responsible for translating core factual entities across linguistic boundaries. This research reveals how inconsistent representations across language families lead to cross-lingual hallucinations, exposing bottlenecks in factual consistency 3234.
Applications in Security and Alignment
Beyond academic curiosity, the rigorous causal verification provided by activation patching supplies critical infrastructure for AI alignment and safety protocols 1235.
Safety Neurons and Jailbreaks
Recent applications involve tracing the internal computational pathways of model refusals and evaluating susceptibility to adversarial jailbreaks 3336. By employing dynamic activation patching alongside Sparse Autoencoders, researchers identified distinct "safety neurons" governing harmlessness and refusal outputs 35.
Remarkably, these safety neurons are highly sparse and heavily concentrated. Restoring clean activations to roughly 5% of these identified safety neurons can recover 90% of a model's safety performance during an active adversarial jailbreak attack 35. Extensive evaluations across multiple large language models reveal a general pattern: successful jailbreaks function by mechanically suppressing the activation circuits tied to refusal while simultaneously amplifying internal components that reinforce affirmative compliance 36. By mapping these specific pathways, researchers can develop structural defenses that render models mathematically robust against prompt-injection attacks.
Auditing and Regulatory Compliance
Regulatory compliance frameworks are beginning to investigate activation patching as a tool to monitor foundational models in high-stakes environments. For instance, researchers have designed algorithmic tasks to use direct logit attribution and attention patching to identify whether a model internalizes forbidden biases, such as evaluating Fair Lending law violations in automated financial systems 2656. By shifting from external, black-box behavioral audits to mechanistic internal audits, researchers and regulators can identify hazardous capabilities and encoded biases deep within the network's weights long before they manifest in deployment or cause public harm.